CMU 15-445 Lecture #10: Sorting & Aggregation Algorithms
目录
CMU 15-445 Database Systems
Lecture #10: Sorting & Aggregation Algorithms
Query Plan
-
从本节课开始将讨论DBMS的Operator Execution
-
优化器会把SQL变成一棵执行树,递归式的向上执行
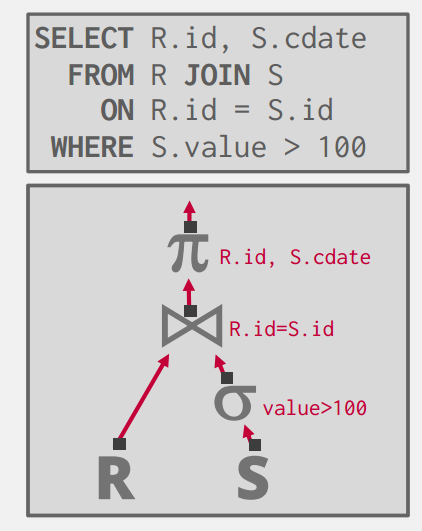
- 本课DBMS的特点:内存没法一次处理全部数据,会OOM,往往需要把中间结果也给写回到磁盘,磁盘和内存要相互配合,要最大化利用连续I/O,减少随机I/O的压力
Sorting
-
External merge sort
- 排的是硬盘里面的数据,而不是像往常那样排内存里面的数据
- 代表:MySQL
- Phase #1 – Sorting: First, the algorithm sorts small chunks of data that fit in main memory, and then writes the sorted pages back to disk.
- Phase #2 – Merge: Then, the algorithm combines the sorted runs into larger sorted runs.
-
两种<Key,Value>的模式
- Early Materialization:<Key,Tuple>,直接存储的就是数据
- Late Materialization:<Key,Record id>,需要回表
-
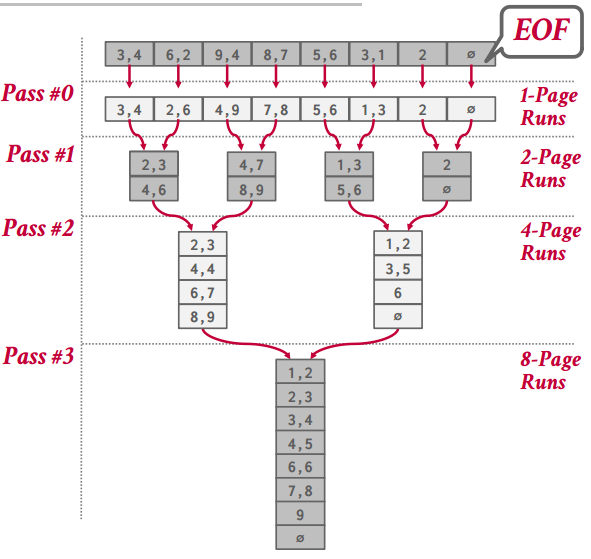
Two-way Merge Sort
- N个页的大表,缓存池最多能承受B个页的容量

把每页加载到内存后排序,然后把排序好的数据写回磁盘,最后再归并刚才写回磁盘的那些有序页 - 排序好的数据不是全部一把进到内存(那又该爆内存了,可以轮询着进,因为合并有序数组本来就是轮询比较的(参考力扣里面的题目))
-
多个页的情况 - 优化:一次I/O不要只读一页,尽最大可能多读几页
-
General (K-way) Merge Sort
- 二路归并变成K路归并,一次比如读N/B个页,然后进行排序,Merge的轮数会少很多,这样效率会提高很多

- Using B+Trees
- 直接利用B+ Tree的有序性
- 要考虑聚簇还是非聚簇,因为聚簇的话关系到Early Materialization的问题,可以省去回表的过程,提高效率
Aggregations
-
Sorting
-
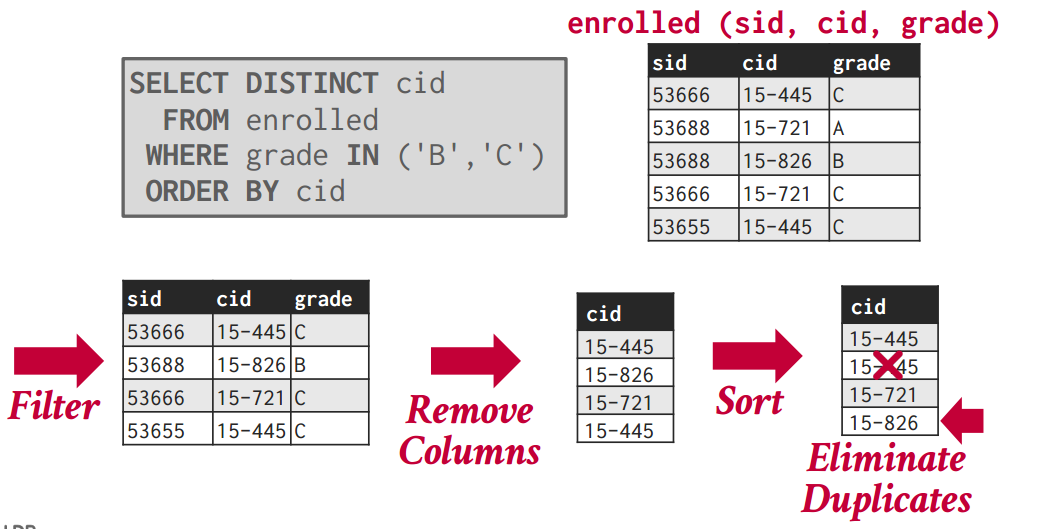
过滤,排序,去重
-
Hashing
-
如果不要求有序可以用Hashing来提高效率
-
External Hashing aggregations
-
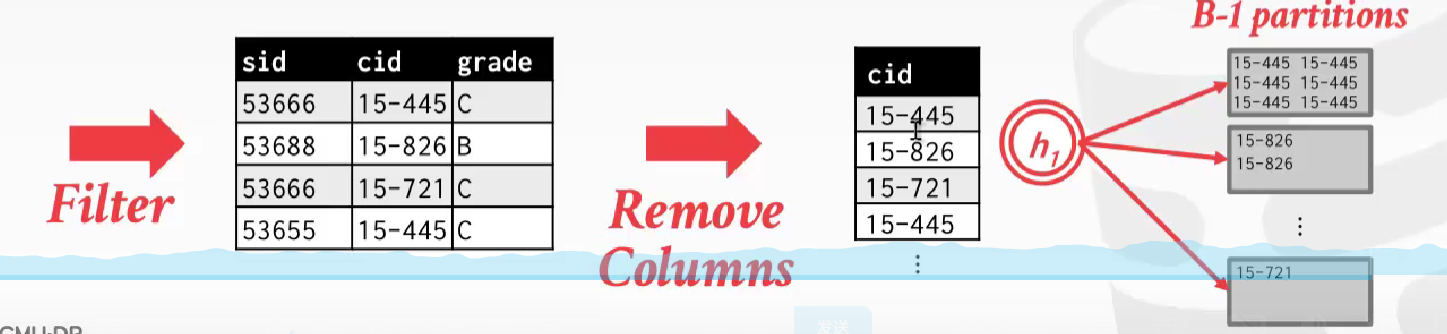
Phase #1 – Partition
- 先给要Agg的字段做一个哈希表,然后把这个哈希表写回到磁盘里面
-
把需要Agg的字段做第一次哈希,相同的值+碰撞的都放在一个桶
-
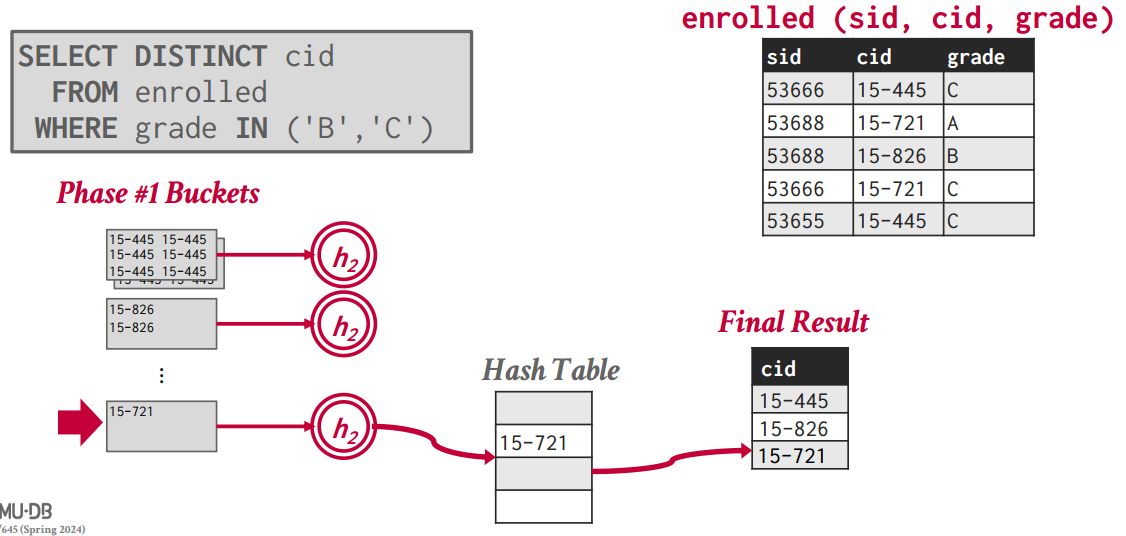
Phase #2 – ReHash:把磁盘里面的哈希表再加载到内存中,读进去之后再做第二次哈希,这样就把碰撞的值也分开了,这样就生成了第二次的哈希表,也就是最终结果
-
二次哈希解决了哈希碰撞,也就拿到了最终结果
-
Hashing summarization
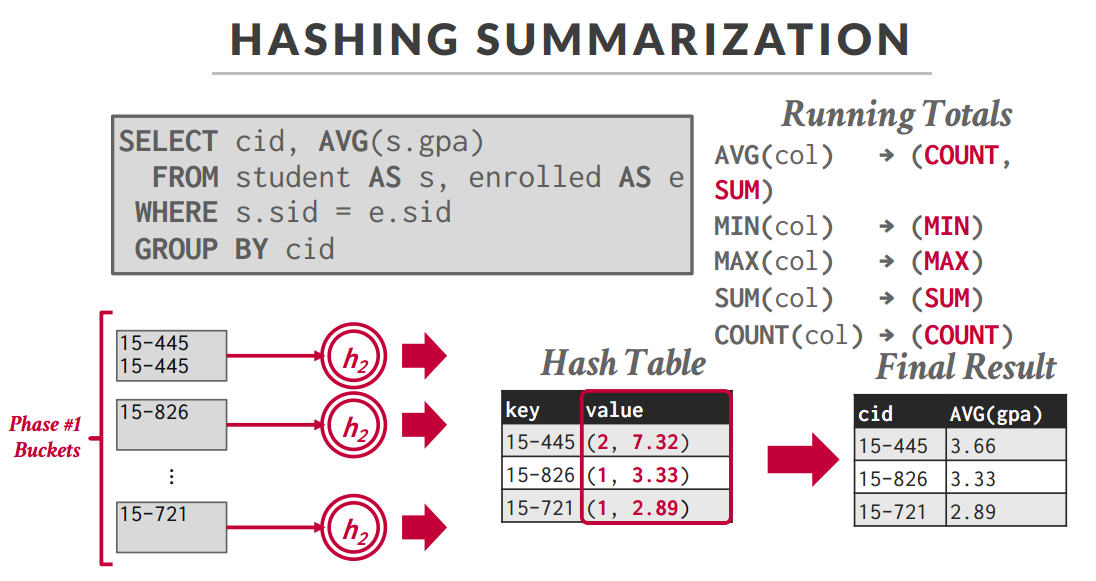
- During the rehash phase, store pairs of the form (GroupKey→RunningVal) 如果说需要对值进行计算(count,sum等),那么在hash的过程中也要带上其他需要的数值,这部分叫RunningVal
-
带上需要的数据进行聚合类函数的计算
-
-
Sorting和Hashing没有绝对的好,要看条件,比如前置的数据有没有做了排序或者哈希,需要的结果到底要不要进行排序
-
优化的思路
- 随机I/O尽量变成连续I/O:一次写入页的数量尽量多
- 预加载:能先加载到内存中的数据都先加载到内存中