CMU 15-445 Lecture #13: Query Processing I
目录
CMU 15-445 Database Systems
Lecture #13: Query Processing I
Query Plan
- 就是前面提到的执行树
- 同一个SQL可以有很多执行计划
Processing Models
- Approach #1: Iterator Model
- Approach #2: Materialization Model
- Approach #3: Vectorized / Batch Model
-
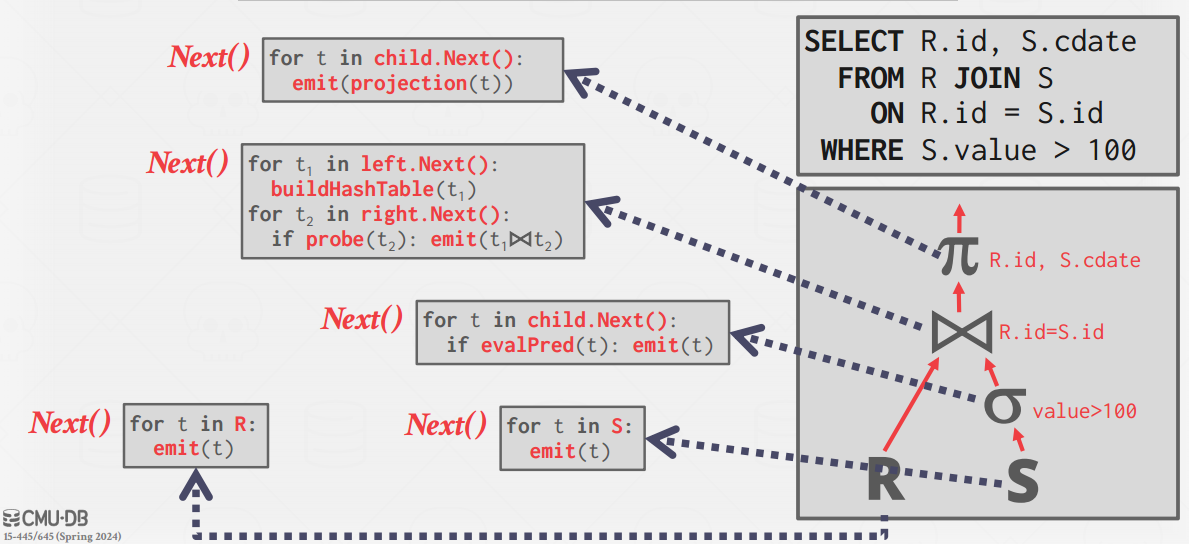
Iterator Model
-
每一个算子需要提供一个Next()的方法,父算子调用一次就吐出来一些数据,如果返回null说明数据都吐出来了(很像Python的yield),我也可以调用我的子算子的Next()方法
-
也叫“Volcano/Pipeline Model”
-

Volcano Model计算的模型 -
这个模型几乎在所有DBMS中都有使用
-
这个模型会有Block的现象,比如Join的时候左边在hash,这个时候上层会被Block
-
部分操作不适合这个模型,比如Sort,只能Block之后全吐出来
-
优点:便于操作,比如LIMIT 100的话我Next() 100次就OK
-
缺点:过多的函数调用(一次返回一个,要调用好多次)会影响性能
-
-
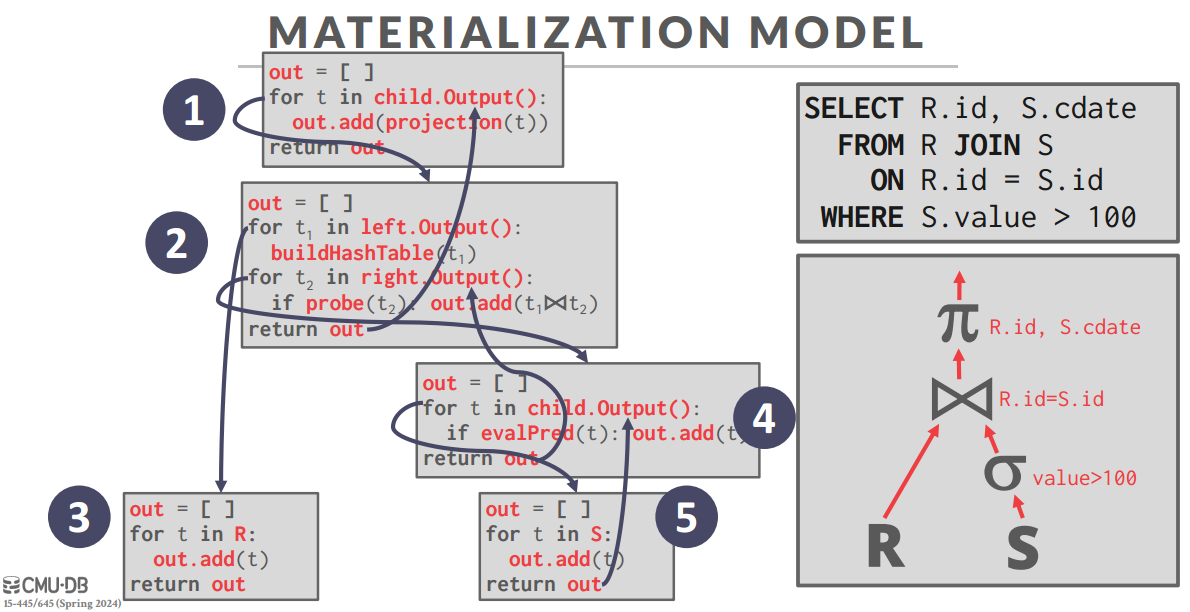
Materialization Model
-
符合直觉的模型,一把算出来给上面
-
这里的返回值就是数组,是下面算子的最终结果 -
OLTP的数据库喜欢这个模型(点查询)
-
OLAP容易给表吐爆
-
- Vectorized / Batch Model
- 前两个模型折中,Next()每次吐出来一批
-
每次吐出来一批数据 - OLAP友好,函数调用不会过多,又不会像Materialization Model那样一次返回的东西太大
- 还有个好处就是匹配硬件,现在部分CPU支持小规模并行处理事务(类似残废版CUDA),这种模型非常符合CPU的并行批处理指令
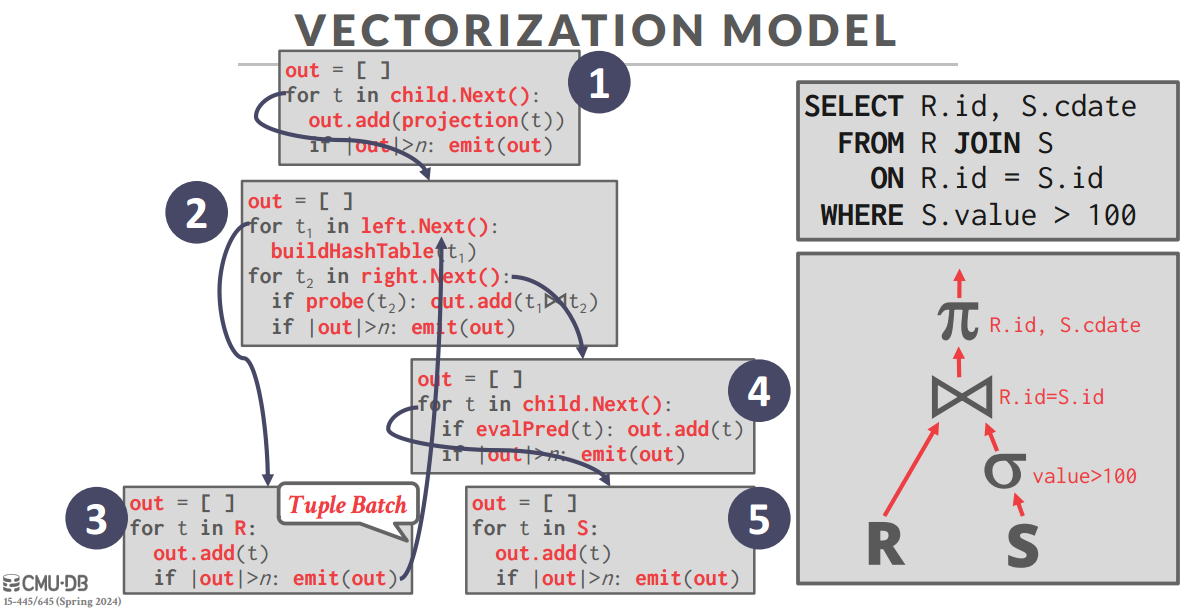
- 函数调用的方向可以根到叶子,也可以叶子到根
Access Methods
- Sequential Scan
- 顺序扫描
- 顺序把页读进来,然后顺序扫描叶中的元组
- 优化
- 预加载
- 不再读的东西扫完就扔
- 并行化
- Zone Maps
-
给每个页做统计信息,这样算子可以不用加载到缓存池就对页做一次判断和过滤 - 问题:数据冗余,而且不能存到页里面(那又该加载到缓存池了),要转门找地方存,还要同步数据
- 晚物化:只要需要的数据,不要整个Tuple,或者只存Record ID,利用回表拿数据

- Index Scan
- 考虑的条件后面会讲
- 用什么索引要靠优化器分析
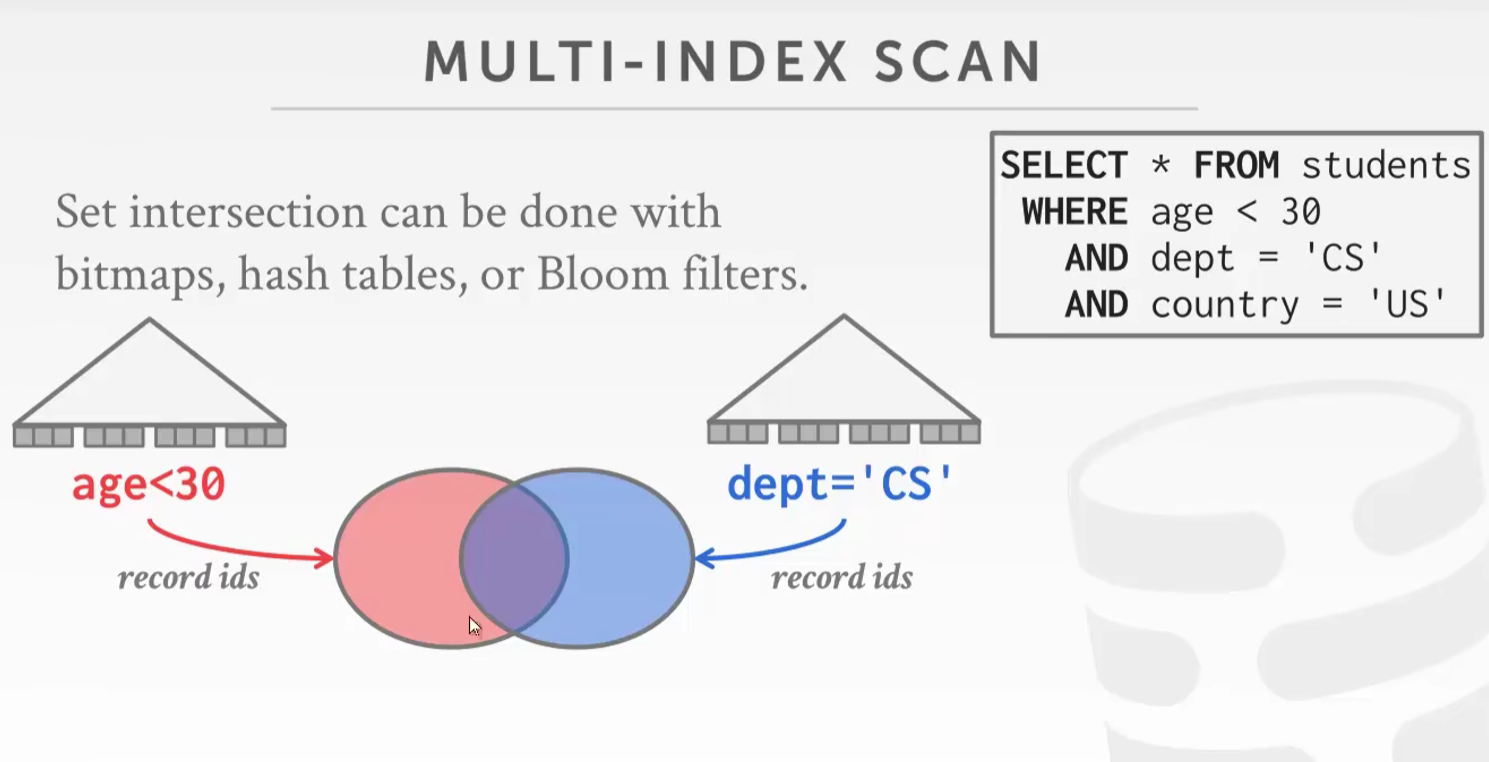
- Multi-Index Scan
-
多索引扫描每一个条件取集合,根据谓词做交/并的操作
Modification Queries
-
更改的操作,逻辑会不一样
- 不能无脑修改,要检查当前表的约束
- 索引等其他数据要同步进行维护
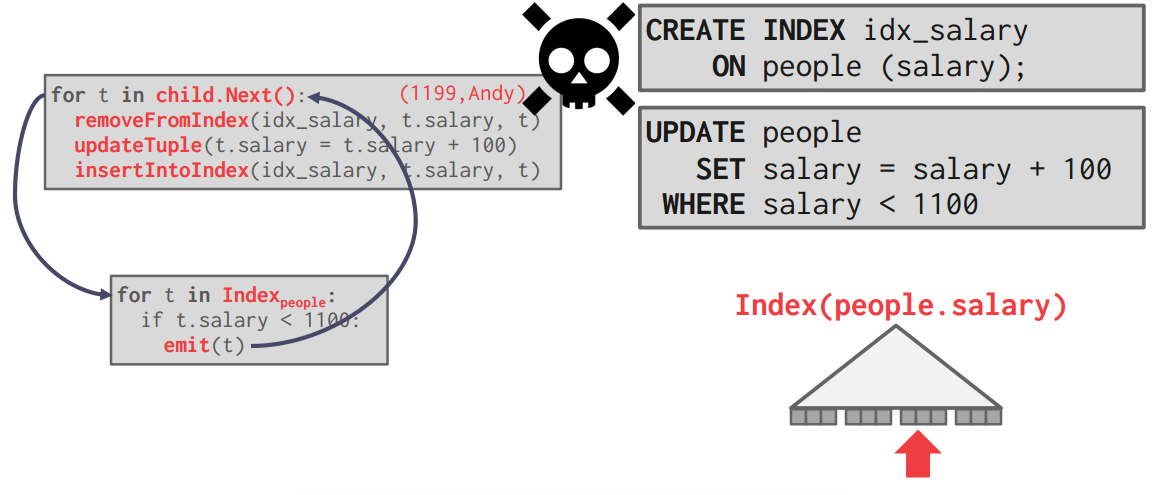
- HALLOWEEN PROBLEM
-
不记录之前操作过什么数据会导致部分数据被多次更新(更新完了之后没有达到预定条件被扫到再次被更新)
-
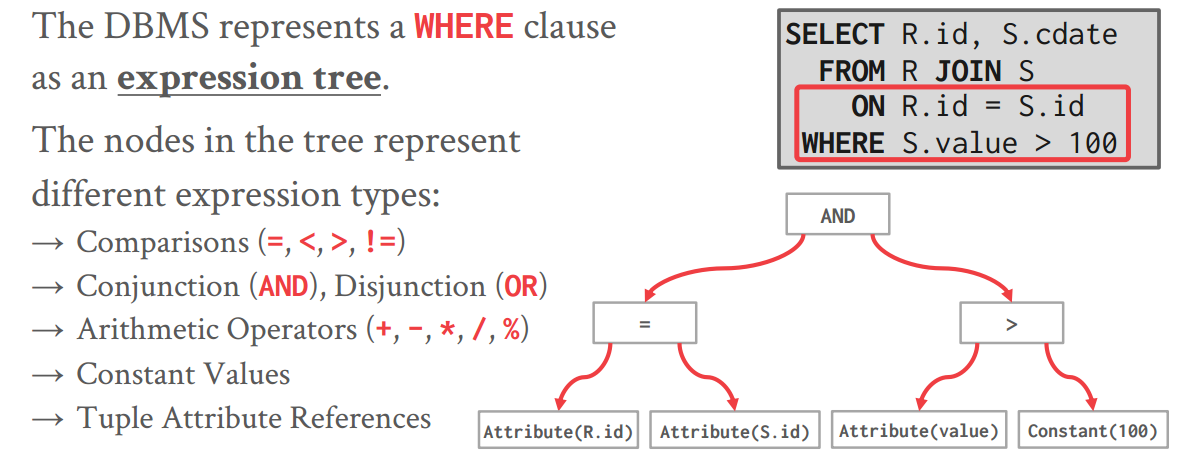
expression tree
- 给谓词表达式也用树的结构处理
-
expression tree
- 缺点:可能会重复计算浪费时间
- 解决方案:能先算出来的全算出来,像Java的JIT(比如经常跑的一段Java字节码,我直接转成二进制CPU指令,然后跑的时候直接跑CPU指令,省去JVM解析的过程)
- 给谓词表达式也用树的结构处理
CONCLUSION
- The same query plan can be executed in multiple different ways.
- (Most) DBMSs will want to use index scans as much as possible.
- Expression trees are flexible but slow.JIT compilation can (sometimes) speed them up.