CMU 15-445 Lecture #15: Query Planning & Optimization
目录
CMU 15-445 Database Systems
Lecture #15: Query Planning & Optimization
- 数据库最复杂的模块之一,论文都在这个上面做功夫
Overview
-
SQL都是声明式的,没有告诉DBMS执行的过程
-
需要优化器来根据SQL告诉DBMS具体怎么执行
-
两种流派
- SQL+优化器
- 大数据处理框架(flink,spark)+程序员
-
优化的两种流派
- Heuristics/Rules
- 启发式,通过查看catalog来看表的结构/有无索引,从而进行优化
- Cost-base Search
- 基于代价的:要估计每一个查询plan的变化,然后进行决策,要知道数据的情况
- 大部分的数据库会结合这两个流派
- Heuristics/Rules
-
Logical vs. Physical Plans
- 逻辑计划都是关系代数级别的
- 物理计划具体到怎么执行,比如算子怎么执行,是sort join还是hash join
-
计划的优化是NP难度级别的问题,这门课就是讲的普及
Logical Query Optimization
-
自己要写一些模式上面的规则,让优化器拿着规则去优化,比如JOIN怎么消除,怎么做索引下推
-
缺点:只能根据规则进行逻辑计划的转换,但是不能根据代价开销去进行优化,很死板
-
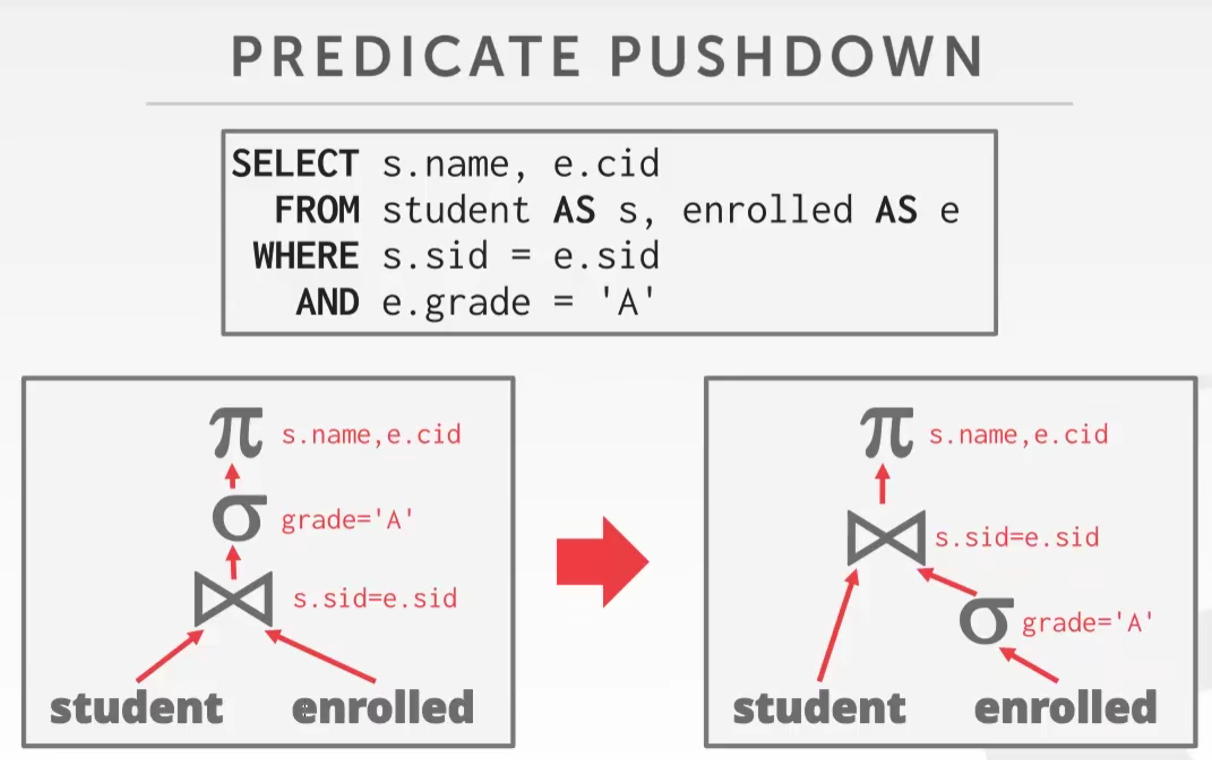
Some pattern
- Perform filters as early as possible (predicate pushdown).
- Reorder predicates so that the DBMS applies the most selective one first.
- Breakup a complex predicate and pushing it down (split conjunctive predicates)
Cost Estimations
-
最大的代价还是磁盘的I/O,这里的优化就是减少I/O
-
postgres:用的”magic”,黑魔法
-
老牌的商用数据库在优化的时候比开源的要保守和细得多,DB2就会结合事务,锁,用户数整体考虑,pg就比较激进和简单了
-
Selection Statistics
- 这个就是参数,关系型数据库会对每张表做统计信息,这样你分析才有参数
