CMU 15-445 Lecture #17: Two-Phase Locking
CMU 15-445 Database Systems
Lecture #17: Two-Phase Locking
Transaction Locks
-
在操作数据的时候通过DBMS的锁管理器给数据上一把锁,这样就可以避免并发的数据竞争问题
-
但是这个锁怎么加怎么解的方案需要设计
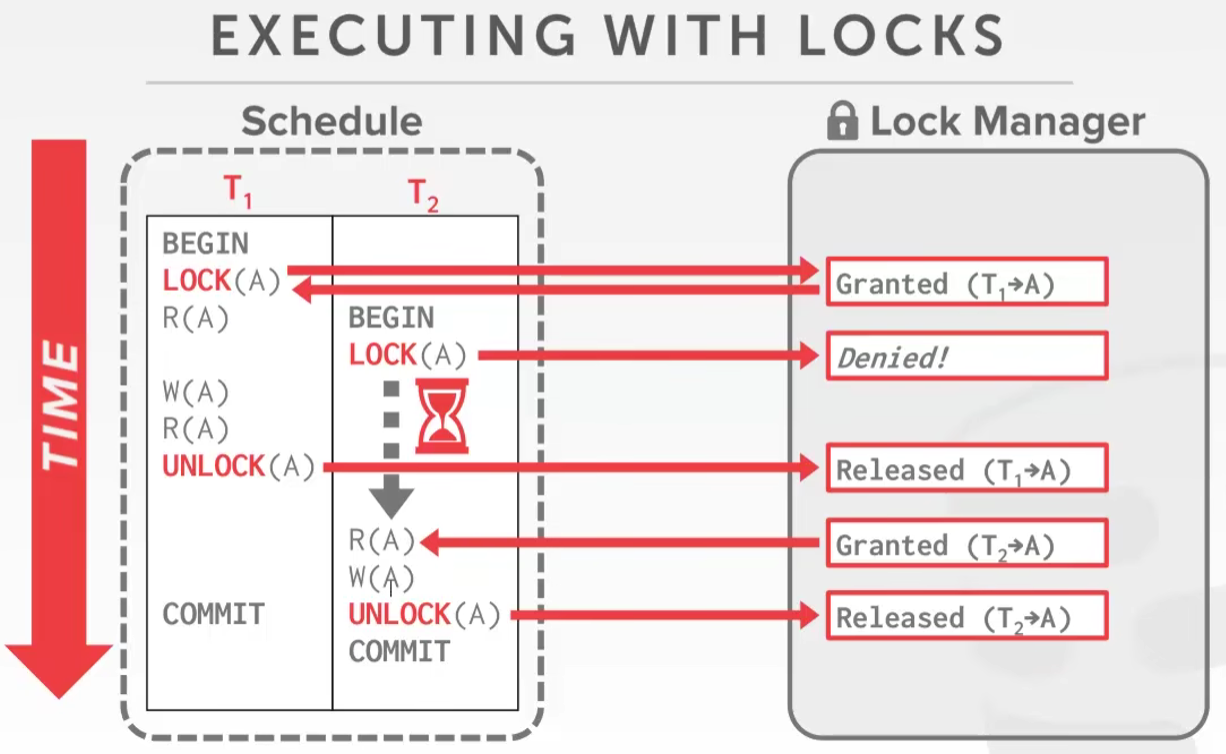
-
Lock Types
- S-LOCK: Shared locks for reading(Reading Lock)
- X-LOCK: Exclusive locks for writing(Writing Lock)
-
仅仅W(R)的时候上锁,修改完了解锁是无法修复串行化带来的问题,因为这个操作在一个事务里面只是一段,没有锁这个事务
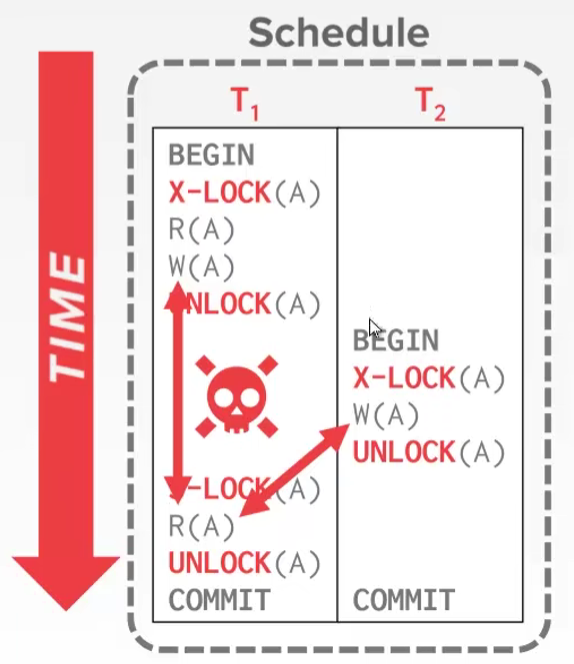
Two-Phase Locking(2PL)
- 这个就是后面的研究人员为了避免上面加锁还是没有解决并发问题提出来的一个理论,这个加锁的理论和上面最大的不同就是不用预先知道整个事务的全貌(前面的加锁方案好多都是事后诸葛亮,但是放在真实场景下你又不可能回滚去干这玩意)
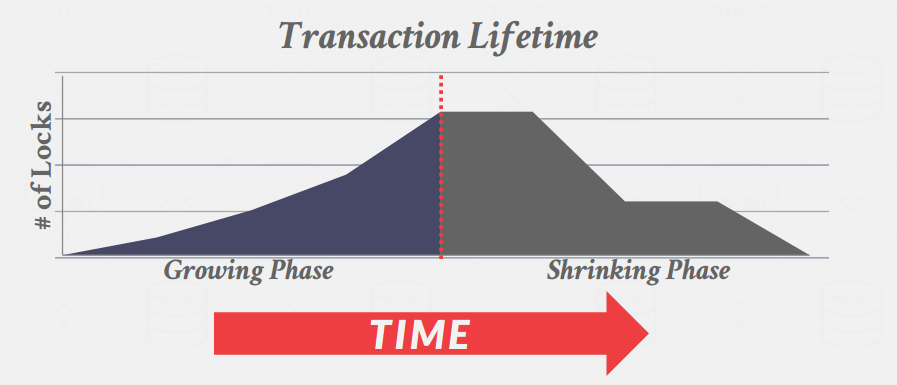
- 2PL分为两个阶段
- Phase #1– Growing: In the growing phase, each transaction requests the locks that it needs from the DBMS’s lock manager. The lock manager grants/denies these lock requests.
- Phase #2– Shrinking: Transactions enter the shrinking phase immediately after they release their first lock. In the shrinking phase, transactions are only allowed to release locks. They are not allowed to acquire new ones.
- 2PL的问题: cascading aborts
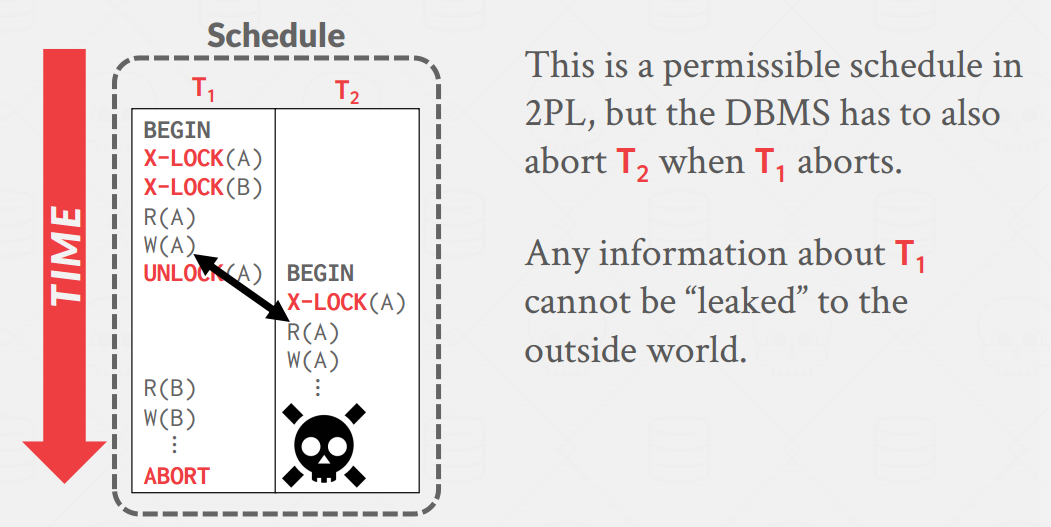
- Solution: Strong Strict 2PL (aka Rigorous 2PL)
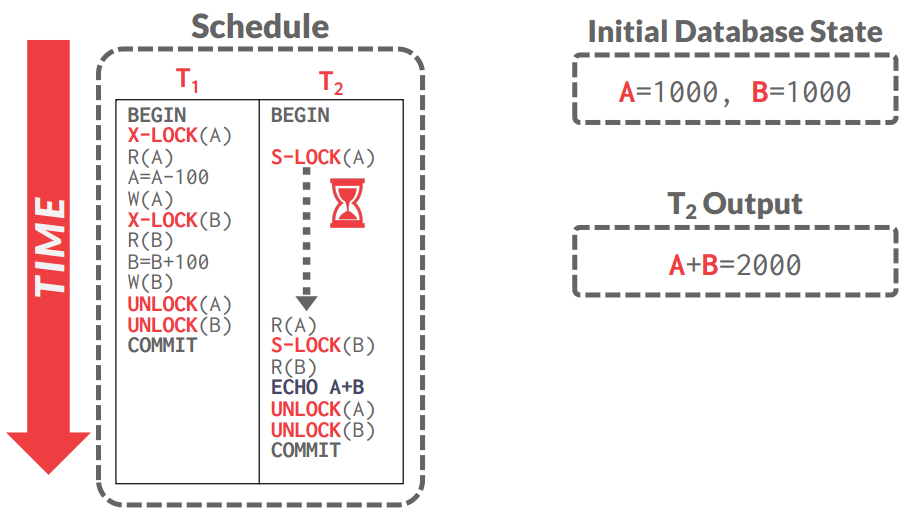
Deadlock Handling
- 2PL的另一个问题: Dead-Locks
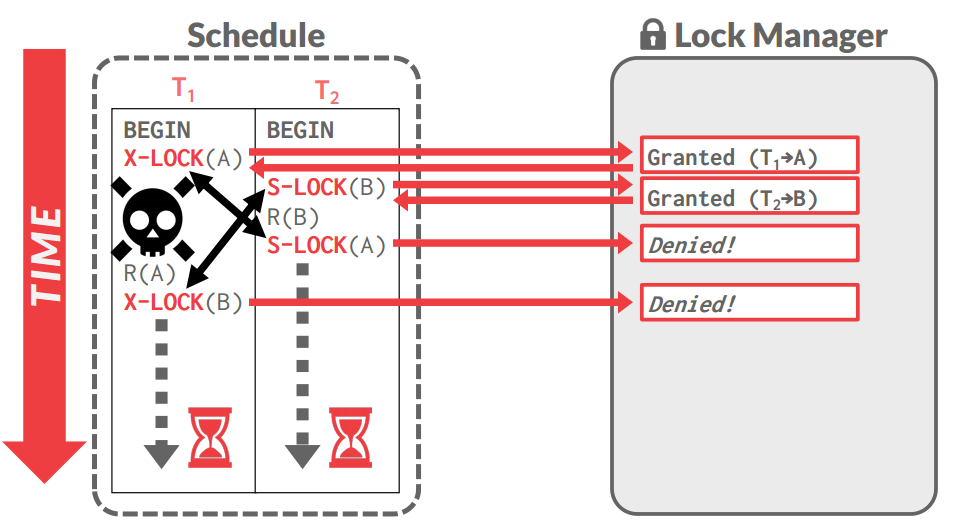
-
Two ways of dealing with deadlocks:
-
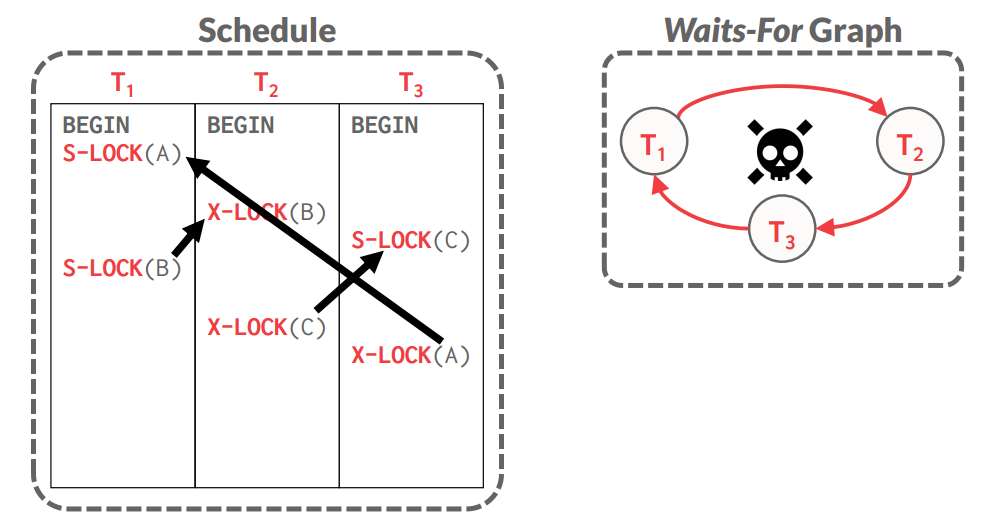
→ Approach #1: Deadlock Detection:DBMS会维护一个waits-for graph来描述所有并发的事务谁在等谁的锁
- Nodes are transactions
- Edge from $T_i$ to $T_j$ if $T_i$ is waiting for $T_j$ to release a lock.

The system periodically checks for cycles in waits-for graph and then decides how to break it. - When the DBMS detects a deadlock, it will select a “victim” transaction to rollback(rollback or restart) to break the cycle.
- 权衡: 检测周期和死锁解开时间反相关,和开销正相关,还有就是干掉那个事务(执行时间,young还是old,执行了几条SQL,加了几个锁)
- Deadlock handling: rollback length
- Approach #1: Completely → Rollback entire txn and tell the application it was aborted.
- Approach #2: Partial (Savepoints) → DBMS rolls back a portion of a txn (to break deadlock) and then attempts to re-execute the undone queries.
-
→ Approach #2: Deadlock Prevention
-
给每个事务加上时间戳,越靠前的事务越老,越靠后的事务越年轻
-
Older Timestamp = Higher Priority (e.g., T1 > T2)
-
Wait-Die (“Old Waits for Young”):
- If requesting txn has higher priority than holding txn, then requesting txn waits for holding txn. (老事务碰到年轻的事务占有锁,就等到年轻的事务解锁)
- Otherwise requesting txn aborts.(反之年轻的事务等老事务的锁,直接rollback自杀)
-
Wound-Wait (“Young Waits for Old”)
- If requesting txn has higher priority than holding txn, then holding txn aborts and releases lock(老的事务要锁,发现整个锁被年轻的事务持有,直接rollback年轻的事务然后抢锁)
- Otherwise requesting txn waits.(年轻的事务发现锁在老的事务哪里,那就等老的事务解锁)
-
这个主要的思路就是解决了构成死锁条件里面“持有并等待”的条件,冲突了直接开抢
-
注意: restart的txn的时间戳用上次的时间戳,不然可能会造成饥饿
-
-
Lock Granularities
-
获取锁的时候是获取属性锁,行锁,表锁,还是库锁?整个需要DBMS来负责,需要保证你加锁的数量尽可能小(10亿行锁 vs 一张表锁),也需要考虑对并发度的影响
-
Intention Lock:高层级的锁会有标记来判断下面有没有加锁的(比如表锁会记录下面的行有没有加锁的),节省了向下检索的效率
- 意向锁也有S锁和X锁
-
分层的锁在实际工程中相当好用
-
LOCK ESCALATION
- 如果下层的锁过多了,那么DBMS就会自动升级成高层的锁(怎么和JVM的锁升级机制的思想很像?)
-
一般加锁都是DBMS自动负责的,但是用户可以用SQL手动来加锁
|
|
CONCLUSION
-
2PL is used in almost every DBMS.
-
Automatically generates correct interleaving:
- Locks + protocol (2PL, SS2PL …)
- Deadlock detection + handling
- Deadlock prevention