CMU 15-445 Lecture #20: Database Logging
CMU 15-445 Database Systems
Lecture #20: Database Logging
Crash Recovery
- Recovery algorithms are techniques to ensure database consistency(C), transaction atomicity(A), and durability(D) despite failures(example no power)
- The key primitives that used in recovery algorithms are UNDO and REDO. Not all algorithms use both primitives.
- UNDO: The process of removing the effects of an incomplete or aborted transaction.
- REDO: The process of re-applying the effects of a committed transaction for durability.
FAILURE CLASSIFICATION
-
Type #1 – Transaction Failures
- Logical Errors:→ Transaction cannot complete due to some internal error condition (e.g., integrity constraint violation).
- Internal State Errors:→ DBMS must terminate an active transaction due to an error condition (e.g., deadlock).
-
Type #2 – System Failures
-
Software Failure:→ Problem with the OS or DBMS implementation (e.g., uncaught divide-by-zero exception).
-
Hardware Failure:
- → The computer hosting the DBMS crashes (e.g., power plug gets pulled).
- → Fail-stop Assumption: Non-volatile storage contents are assumed to not be corrupted by system crash.
-
-
Type #3 – Storage Media Failures
- Non-Repairable Hardware Failure:
- → A head crash or similar disk failure destroys all or part of non-volatile storage.
- → Destruction is assumed to be detectable (e.g., disk controller use checksums to detect failures).
- The recovery protocol can’t recover from this! Database must be restored from an archived version.
- Non-Repairable Hardware Failure:
-
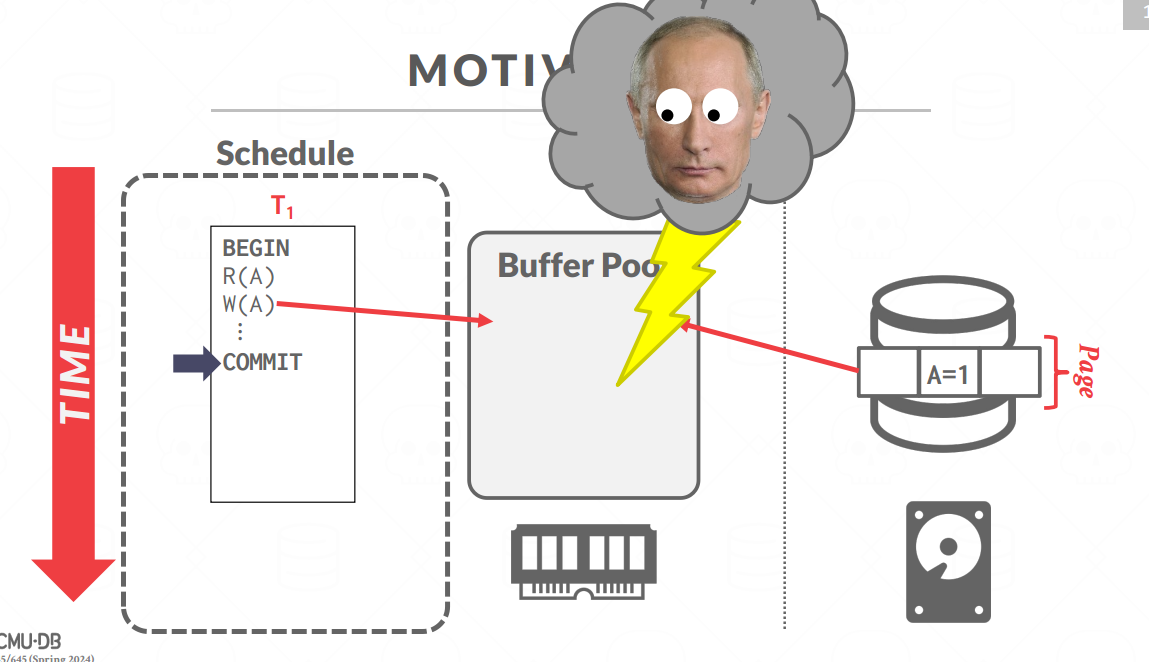
考虑:磁盘比内存慢的多,所以DBMS的模式是load到内存池后修改,最后刷盘
- 保证的点:只要commit成功,数据永远不会丢(除了硬盘爆炸),如果事务中间失败了,那么这个事务应该就和没发生一样
-
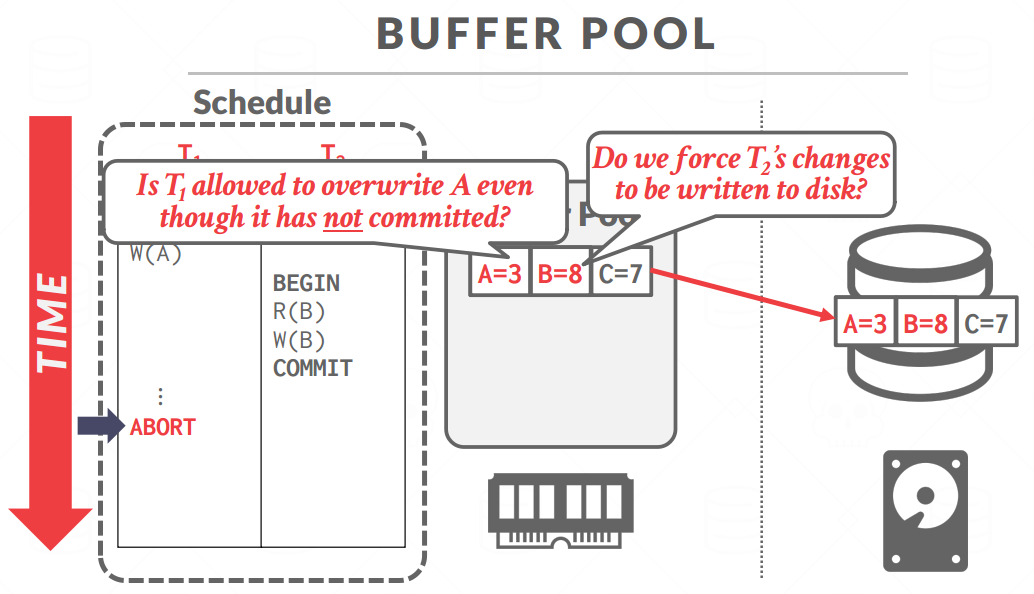
STEAL POLICY
- STEAL: Is allowed.(别人没提交的数据我也刷)
- NO-STEAL: Is not allowed.(别人没提交我就不能刷到磁盘)
-
FORCE POLICY
- FORCE: Is required.(commit后立即刷)
- NO-FORCE: Is not required.(不强制要求)
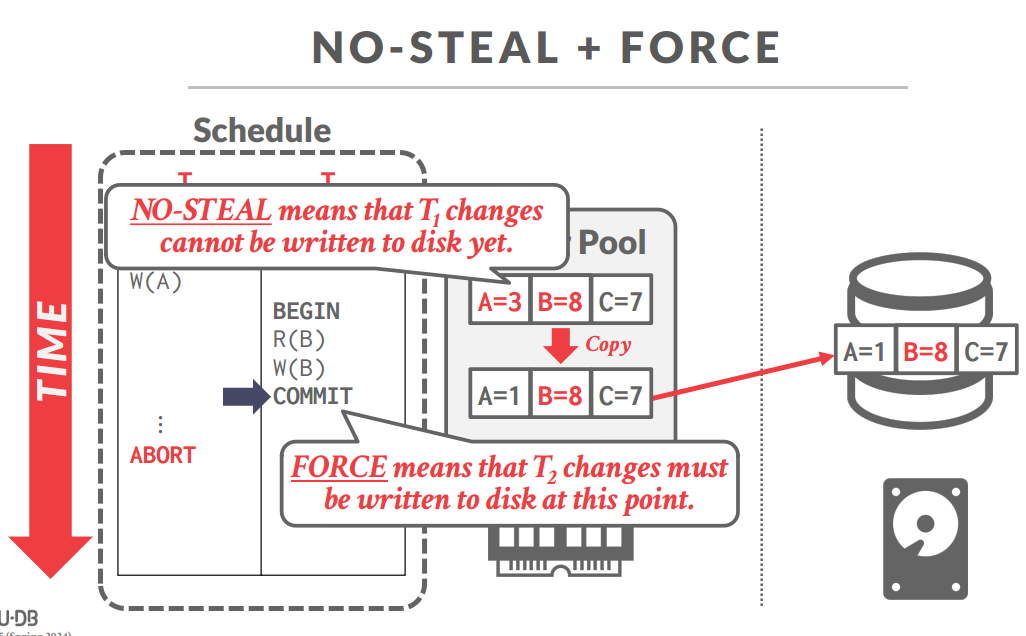
- NO-STEAL FORCE
- 优点:好实现,不需要undo和redo的操作
- 缺点:效率低,刷盘频率太高,没有undo和redo那所有的东西都要load到内存池,也很伤害效率,能够修改数据的量收到缓存池大小的限制(缓存池就用来做的数据备份,没有写进磁盘的数据需要全部暂存在缓存池)
Shadow Paging
-
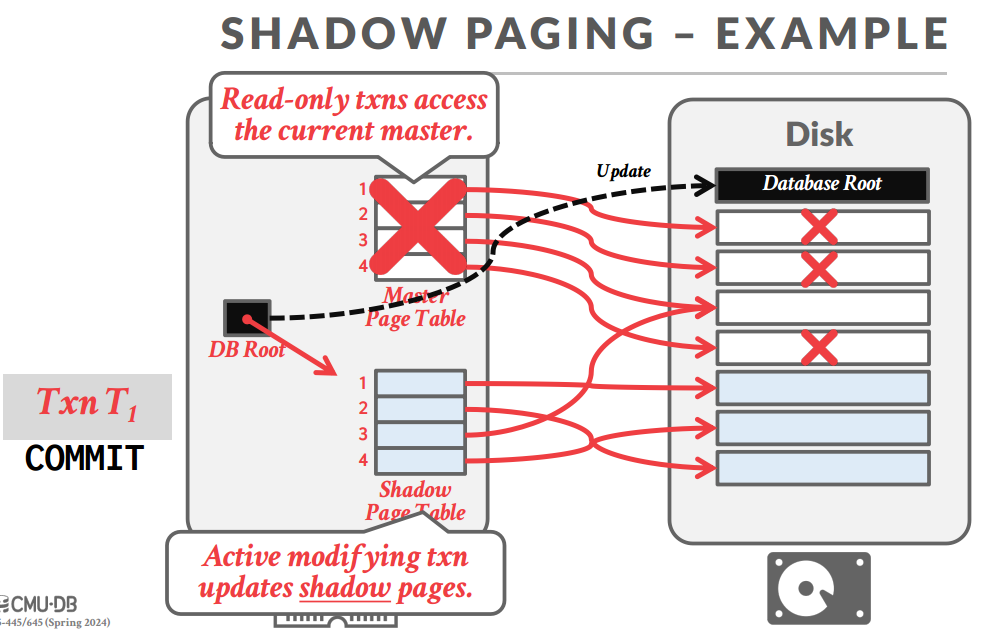
具体实现:SHADOW PAGING
-

把需要的数据Copy一份再改,改的时候也刷盘,commit之后改指针指向,最后清除原有页 - Undo: 把本地复制出来的页全部干掉
- Redo: 不需要,commit必须刷盘
-
实际应用:SQLITE (PRE-2010)
-
在硬盘上面留原始版本(undo),commit的时候刷盘
-
缺点:对磁盘有大量的随机读写,性能不好
-
思路:随机写=>顺序写:WAL
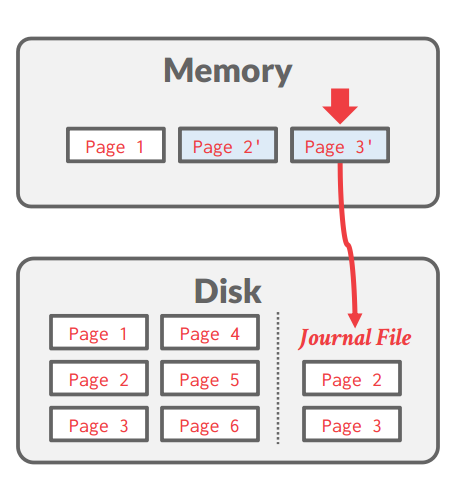
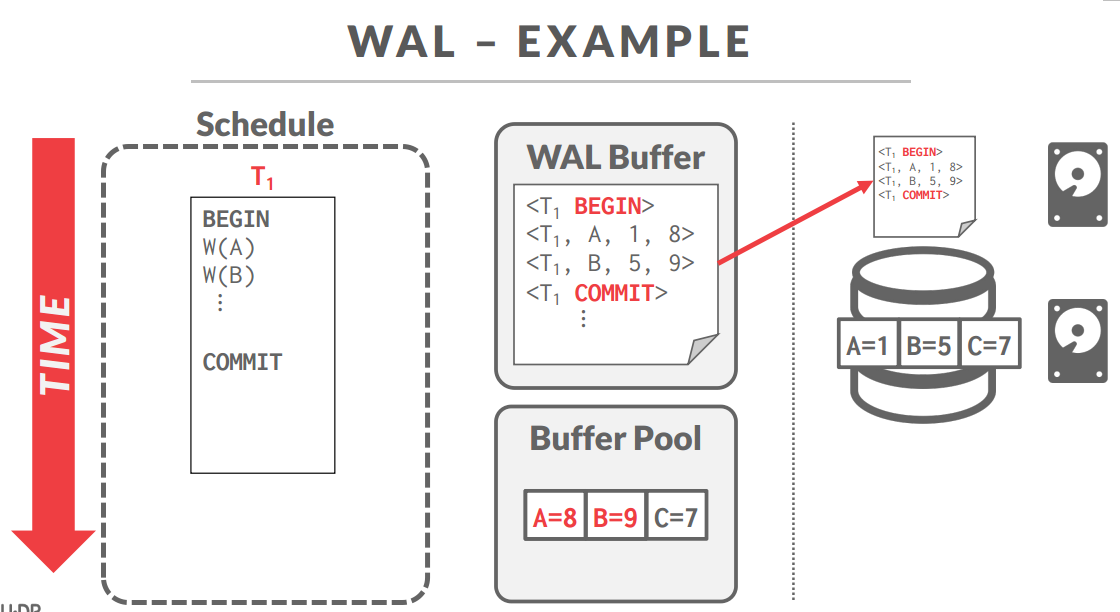
Write-Ahead Logging(WAL)
-
With write-ahead logging, the DBMS records all the changes made to the database in a log file (on stable storage) before the change is made to a disk page
-
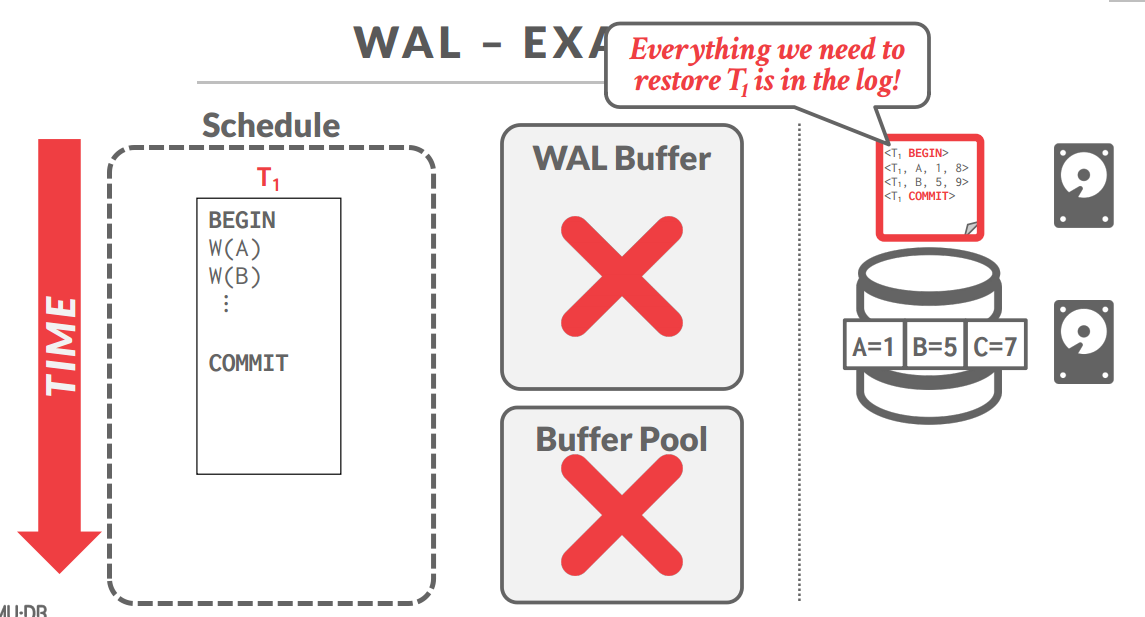
The log contains sufficient information to perform the necessary undo and redo actions to restore the database after a crash.
-
The DBMS must write to disk the log file records that correspond to changes made to a database object before it can flush that object to disk.
-
Buffer Pool Policy: STEAL + NO-FORCE
-
一般是<BEGIN>打头,<COMMIT>结尾,COMMIT必须是要把所有数据都刷到磁盘里面
-
日志格式
-
Transaction Id
-
Object Id
-
Before Value (UNDO)
-
After Value (REDO)
-
Not necessary for Before Value and After Value if using append-only MVCC
-
先刷日志再刷盘,commit代表刷日志成功 -
crash之后靠日志恢复
-
-
问题:用户commit你就要把日志刷到盘里面,但是刷盘频率高了又破坏效率
- 优化: group commit: commit的时候卡住,凑够了几个事务再一起刷
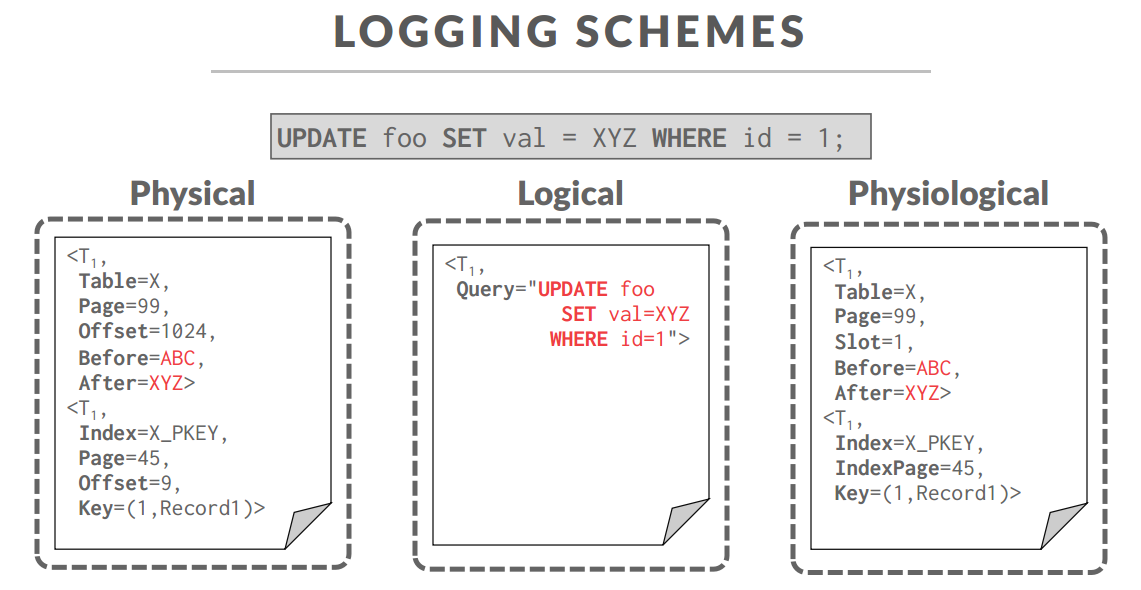
Logging Schemes
-
Physical Logging:
-
Record the byte-level changes made to a specific location in the database.
-
Example: git diff
-
缺点:会被写放大(UPDATE ALL FRO A TABLE => BIG Physical Log)
-
-
Logical Logging:
- SQL
- 缺点:恢复的时候慢,还有SQL自己的缺陷(NOW()函数不能重放,LIMIT不保证次次相同,备库没有主库的索引)
-
Physiological Logging
- 基础是物理日志,混合SQL,偏移量换成槽
-
三种日志 -
MYSQL为什么undo和redo分开:安全,还有就是undo log可以用来做mvcc
Checkpoints
-
Blocking / Consistent Checkpoint Protocol:
- → Pause all queries.
- → Flush all WAL records in memory to disk.
- → Flush all modified pages in the buffer pool to disk.
- → Write a <CHECKPOINT> entry to WAL and flush to disk.
- → Resume queries
-
日志不清理也会爆磁盘
-
crash之后你要知道从哪恢复,类比游戏存档(坐佛/坐火)
-
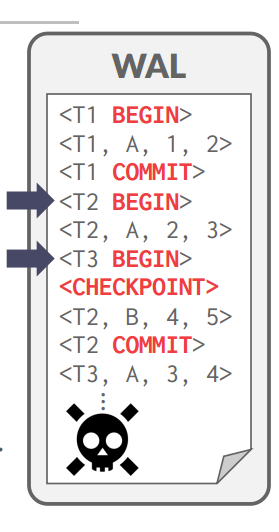
缓存点停住,把日志和脏页全刷回去,然后在日志里面记上一个<CHECKPOINT>,表示上面的数据都刷盘了
-
注意CHECKPOINT上面有完全提交的和半提交的, T2用redo,T3用undo -
T1在检查点之前全刷,不用管,T2检查点前有BEGIN,检查点后COMMIT,用REDO恢复,T3检查点之前有BEGIN,检查点后没有COMMIT,用UNDO恢复
CONCLUSION
- Write-Ahead Logging is (almost) always the best approach to handle loss of volatile storage.
- Use incremental updates (STEAL + NO-FORCE) with checkpoints.
- On Recovery: undo uncommitted txns + redo committed txns.