CMU 15-445 Lecture #21: Database Crash Recovery
CMU 15-445 Database Systems
Lecture #21: Database Crash Recovery
Crash Recovery
-
The DBMS relies on its recovery algorithms to ensure database consistency(C), transaction atomicity(A), and durability(D) despite failures.
-
Each recovery algorithm is comprised of two parts:
- Actions during normal transaction processing to ensure that the DBMS can recover from a failure
- Actions after a failure to recover the database to a state that ensures the atomicity, consistency, and durability of transactions.
-
Check Point的问题
- 性能问题:刷盘的时候整个DBMS都停住了
- 扫描的时候Check Point前后都要看,也很浪费效率
- 没有特别合适的刷盘频率,高了频繁小卡,低了定时大卡
-
Algorithms for Recovery and Isolation Exploiting Semantics(ARIES)
-
Developed at IBM Research in early 1990s for the DB2 DBMS
-
There are three key concepts in the ARIES recovery protocol:
-
Write Ahead Logging(WAL): Any change is recorded in log on stable storage before the database change is written to disk (STEAL + NO-FORCE). 写盘策略
-
Repeating History During Redo: On restart, retrace actions and restore database to exact state before crash.
-
Logging Changes During Undo: Record undo actions to log to ensure action is not repeated in the event of repeated failures.
-
-
WAL Records
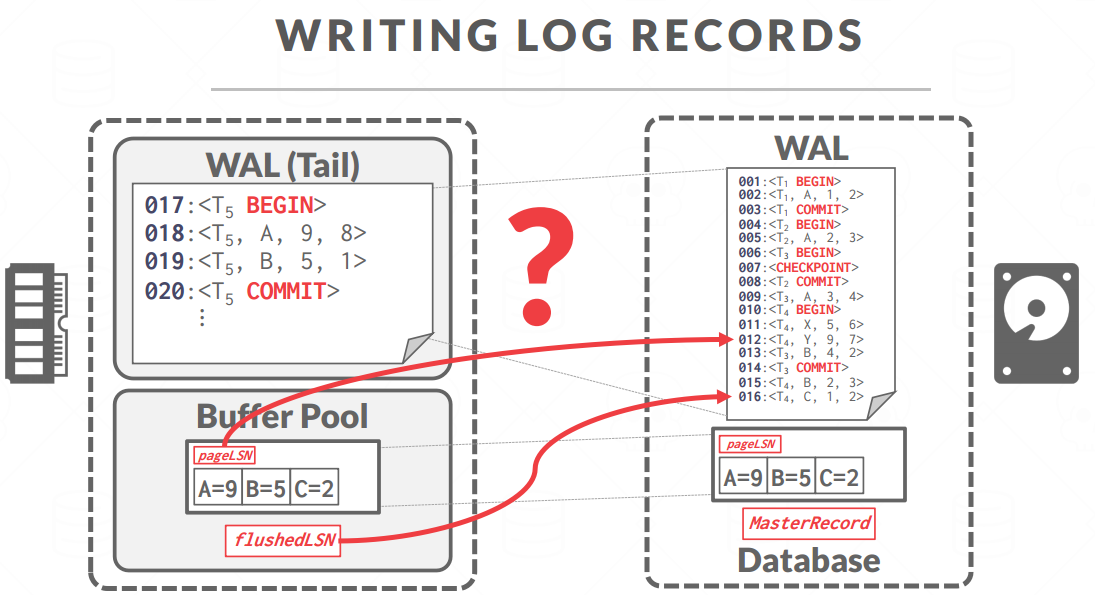
- Every log record now includes a globally unique log sequence number (LSN).日志的序列号

-
每个数据页会有一个pageLSN,记录这一页最新的修改
-
每个系统会有一个flushedLSN,前面的进了磁盘,后面的都在内存没有刷盘
-
脏页写回到磁盘的必要条件 $pageLST\le flushedLSN$,这个脏页之前所作的修改必须先要刷到磁盘里面去,它才能刷回到盘里面去
-

-
每次刷盘的时候要更新flushedLSN
Normal Execution
-
情景:每个事务都会读和写数据,结果有commit和rollback
-
假设
- 所有的log都在一页里面
- 写磁盘是原子操作
- 使用严格2PL
- 窃取式+非强制
-
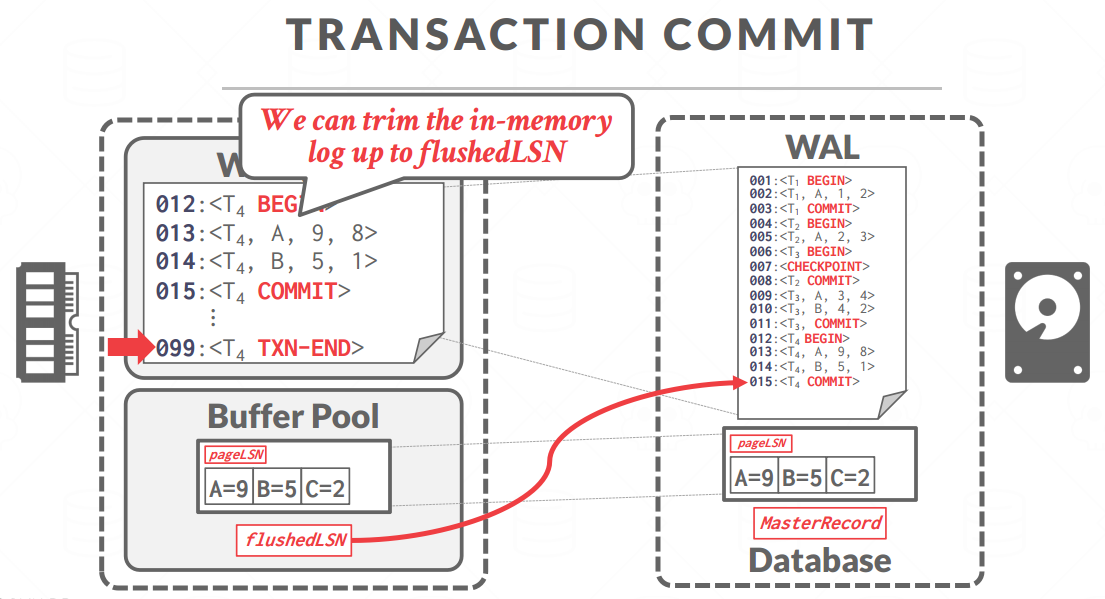
COMMIT
- log上面加一条COMMIT
- COMMIT之前有关这个事务的所有日志都要刷盘,刷盘是连续写+同步
- 后面刷脏页的时候会追加一句TXN-END
- 刷完盘之后的数据在内存里面就可以干掉了
-
COMMIT证明提交成功,TXN-END代表脏页被刷回去了
-
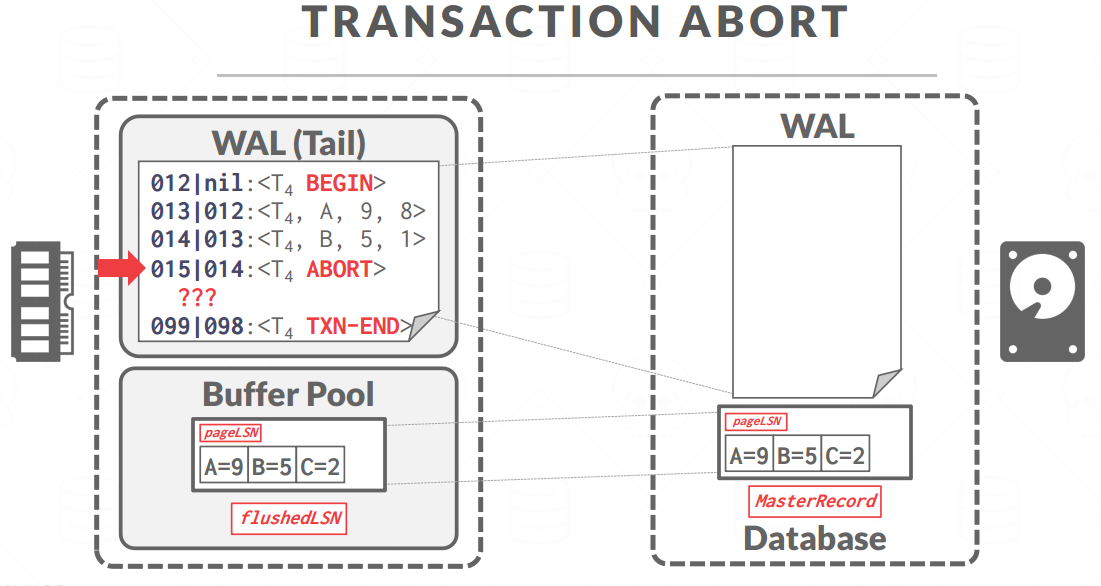
ROLLBACK
-
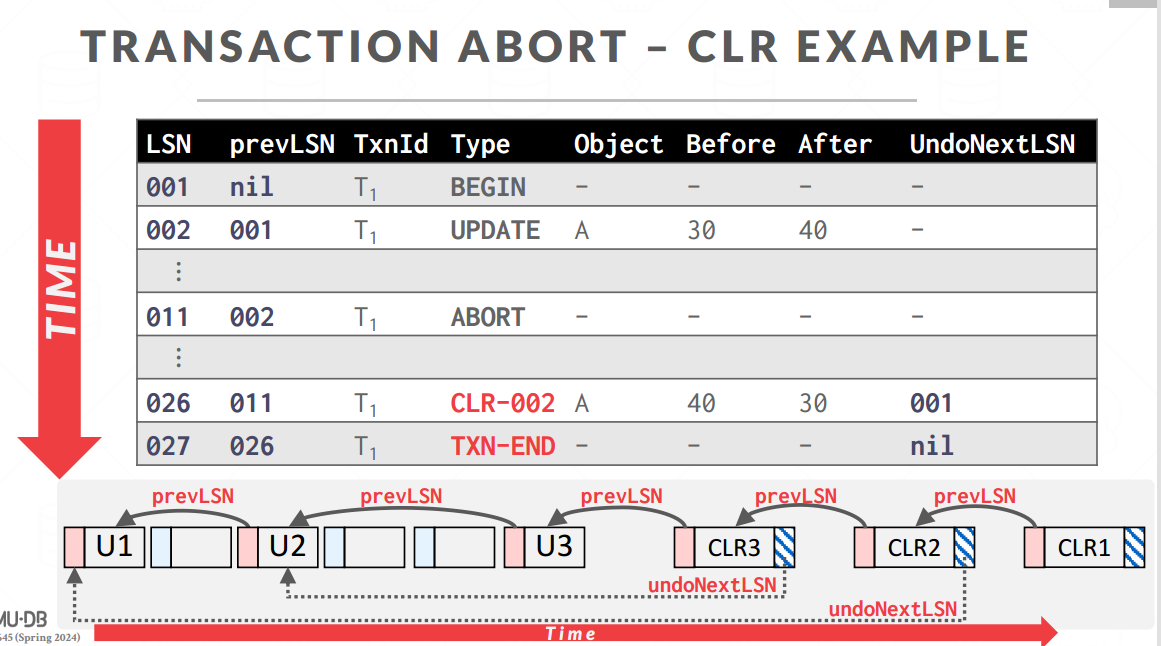
加上prevLSN字段:记录这个事务的上一条日志的地点(类比双链表中的prev指针)
-
-
回滚就是记录相反的日志 -
具体操作:
-
加上ABORT
-
撤销修改,同时追加对应的回滚日志
-
清理做完了加上TXN-END的标志
-
注意:清理的过程是不可能回滚的
-
-
Checkpointing
-
检查点的问题
- 要停止处理新事务,同时所有正在运行的事务都要做完才能刷盘,这个对效率的影响很大
- 改进:让所有进行中的事务暂停/给所有需要刷盘的数据加锁,而不是等他们做完
-
Active Transaction Table (ATT)
- Checkpointing的时候还在活动的事务的表
- One entry per currently active txn.
- → txnId: Unique txn identifier.
- → status: The current “mode” of the txn.
- → lastLSN: Most recent LSN created by txn
- Remove entry after the TXN-END record.(TXN-END才算不活动)
- Txn Status Codes:
- R → Running
- C → Committing
- U → Candidate for Undo
-
Dirty Page Table (DPT)
- Checkpointing的时候的脏页
- One entry per dirty page in the buffer pool:
- → recLSN: The LSN of the log record that first caused the page to be dirty.
-
记录的时候标注更多信息

- Fuzzy Checkpoints
- Checkpointing的时候其他事务也继续运行
- 把checkpoint从一个时间点变成一个时间段(POINT -> BEGIN+END)
-
BEGIN+END
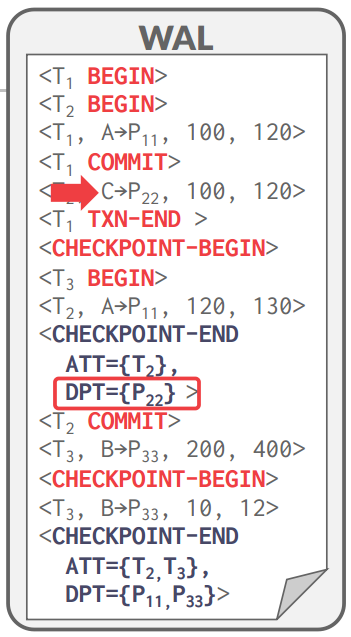
ARIES Recovery
- Analysis: Read the WAL to identify dirty pages in the buffer pool and active transactions at the time of the crash. At the end of the analysis phase the ATT tells the DBMS which transactions were active at the time of the crash. The DPT tells the DBMS which dirty pages might not have made it to disk.
- Redo: Repeat all actions starting from an appropriate point in the log (even txns that will abort).
- Undo: Reverse the actions of transactions that did not commit before the crash.
-
恢复的过程
