CMU 15-445 Lecture #22: Introduction to Distributed Databases
CMU 15-445 Database Systems
Lecture #22: Introduction to Distributed Databases
Introduction Distributed DBMSs
-
辨析概念:Parallel DBMSs vs Distributed DBMSs
-
Parallel DBMSs:
- Nodes are physically close to each other.
- Nodes connected with high-speed LAN(Local Area Network).
- Communication cost is assumed to be small.
-
Distributed DBMSs:
- Nodes can be far from each other.
- Nodes connected using public network.
- Communication cost and problems cannot be ignored
-
主要的差别是通信代价,前者可以忽略,后者无法忽略
- Single node -> Distributed DBMSs
- Questions to consider
- Optimization & Planning
- Concurrency Control
- Logging & Recovery
System Architectures
-
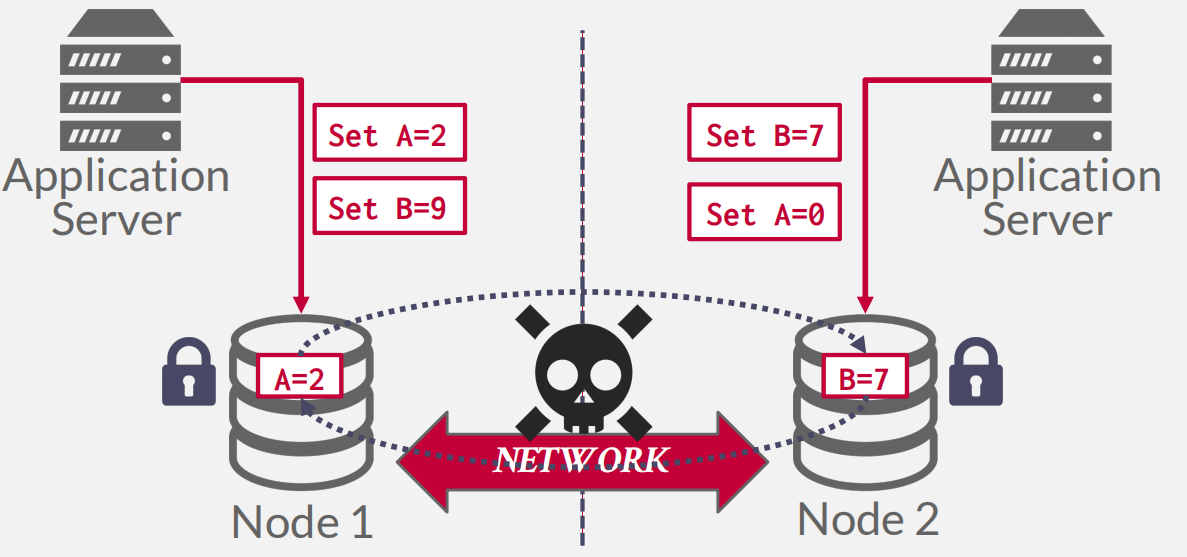
A distributed DBMS’s system architecture specifies what shared resources are directly accessible to CPUs.
-
This affects how CPUs coordinate with each other and where they retrieve/store objects in the database.
- 注意上面图片不是被许多XXX共享就证明其他的机器就那一个组件,为了跑起来基本的OS, CPU, memory和disk都要有,不过是那些部分参与到这个分布式的系统中
-
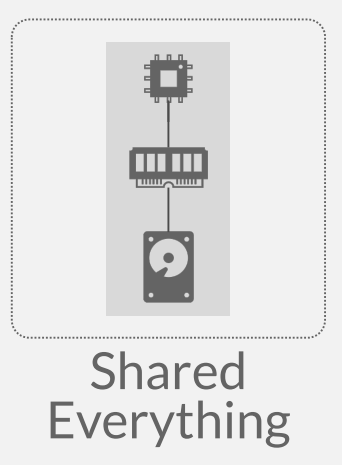
shared memory
-

A large memory and a large disk, both of them are shared by many cpus by network -
Nodes access a common memory address space via a fast interconnect.
-
Can still use local memory / disk for intermediate results
-
-
This looks a lot like shared everything. Nobody does this.(我认为原因是CPU要通过网络来访问内存,内存最大的优势”高速“直接没了)
-
在单体架构上面有使用,多路服务器(多个CPU,每个CPU多核来提高并发能力,中间是通过高速总线相连的)
-
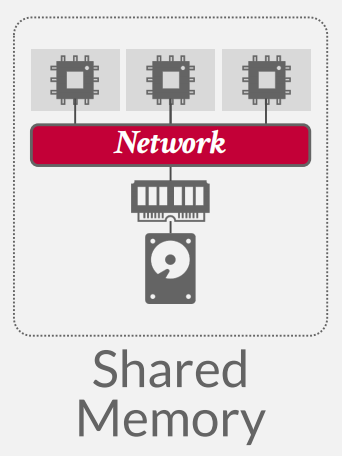
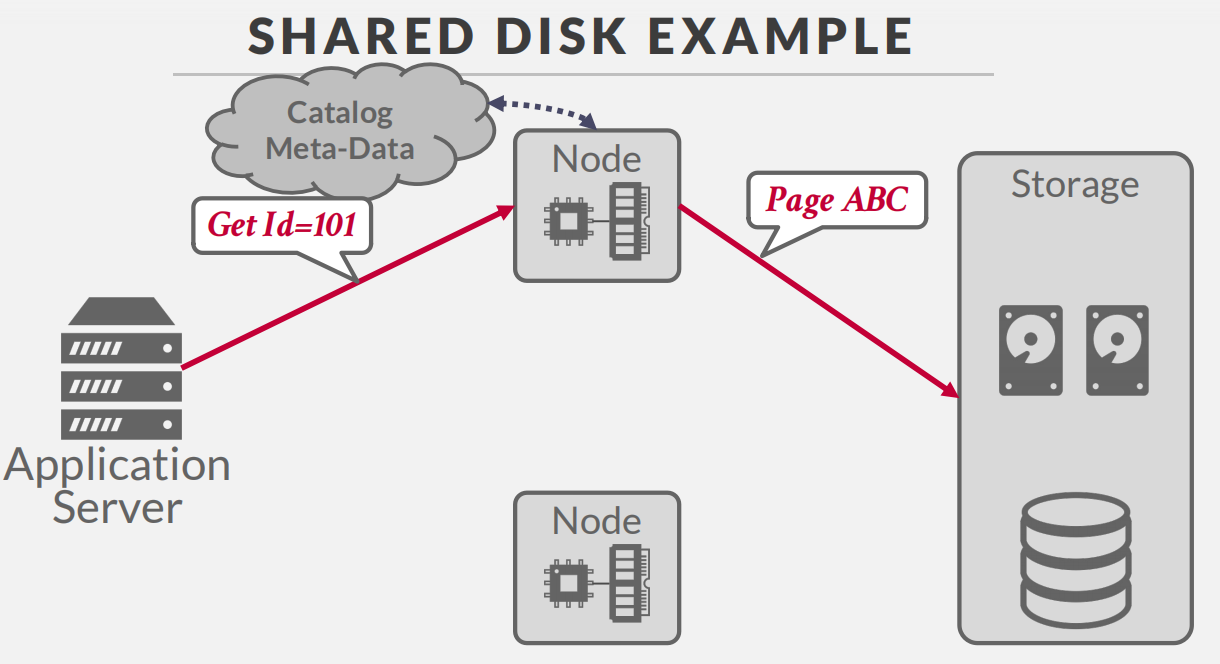
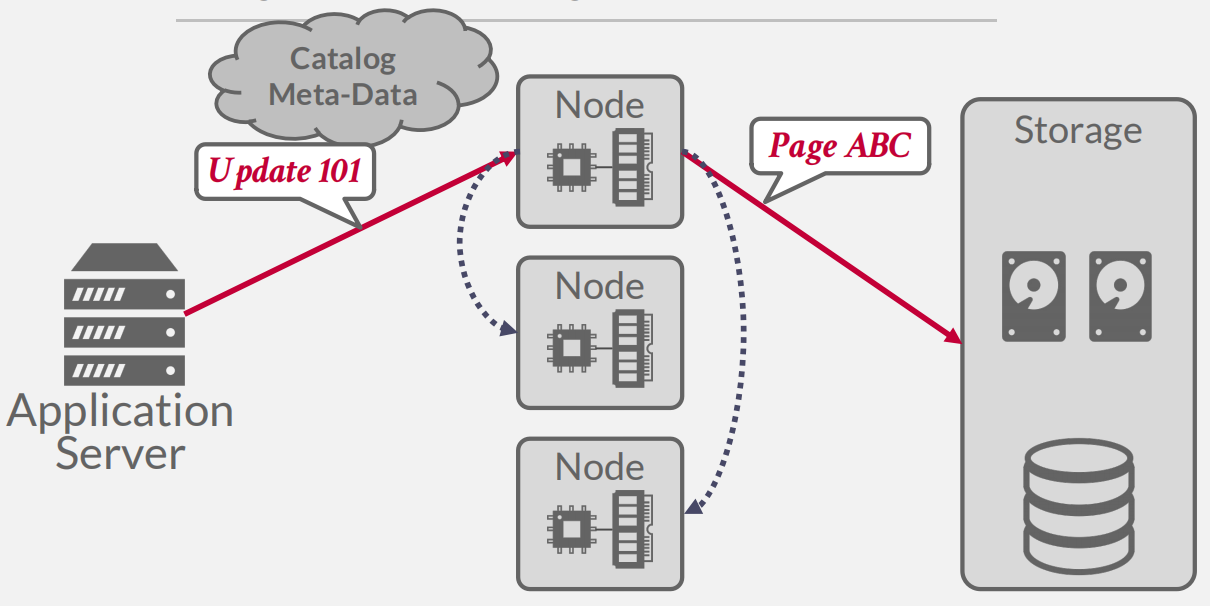
shared disk
-
large disk, shared by many cpus and memories -
Nodes access a single logical disk via an interconnect, but each have their own private memories.
-
Scale execution layer independently from the storage layer.(解耦了执行层和存储层,可以独立拓展来加强单个层的性能)
-
This architecture facilitates data lakes and serverless systems.???没太懂
-
-
该架构在近年新的数据库产品中使用的及其广泛,原因就是近些年云技术的兴起,大多数公司都趋向于购买云数据库,而在云厂商的机房中很容易就能做到这种架构(云计算在设计的时候就把计算和存储分开了,所以机房往往是计算服务器和磁盘集群式分开的,每个部分取一些就是这个架构)
-
国内该架构的代表:PolarDB
-
查询过程,可以看到执行层和存储层分开了,Node数量决定计算能力,存储大小决定存储能力 -
这个架构面临的一个最大的问题就是缓存同步的问题,Node1进行了数据的更新,如果马上不刷盘(因为耗时太长),那么就需要将更新数据的信息同步到其他节点的缓存,其实无论解决那种方案,都要面临这类问题
-
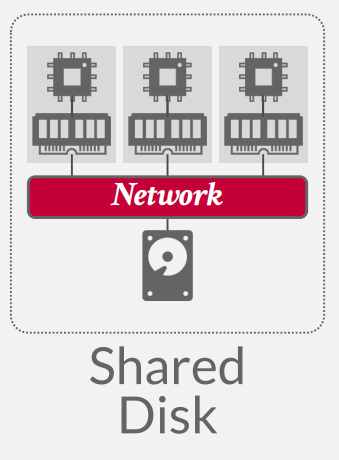
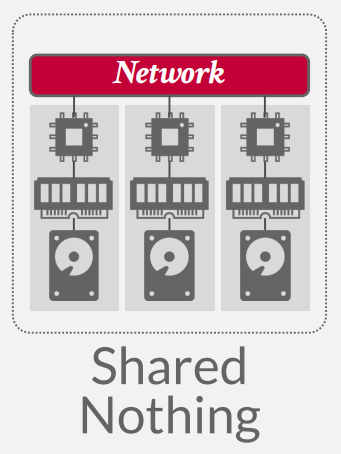
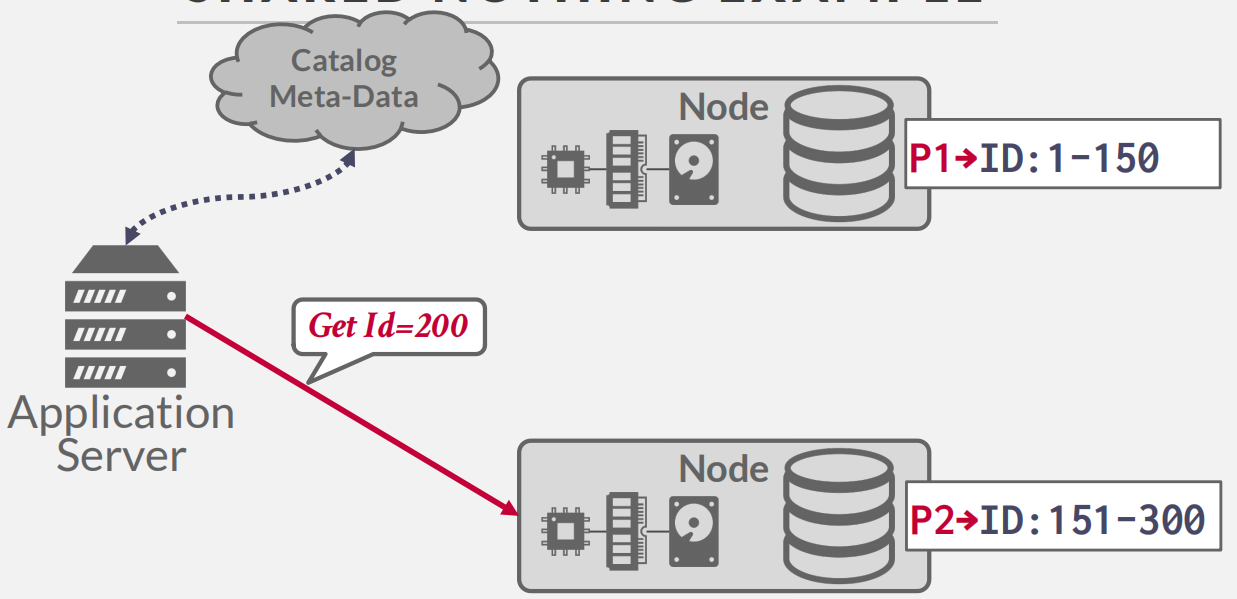
shared nothing
-
Most common situations -
Each DBMS node has its own CPU, memory, and local disk.
-
Nodes only communicate with each other via network
-
Better performance & efficiency.
-
Harder to scale capacity.
-
Harder to ensure consistency.
-
单层扩容(加一台机器所有能力都上去了,其他性能提示的效果因为短板效应被浪费了)和保证一致性都做的不好(数据不在同一块盘上面)
-
好处:和上面shared disk相比把盘肢解了并放在本地,提升了部分性能
-
-
这类架构也在现在的分布式数据库产品中大量使用,代表产品是Redis
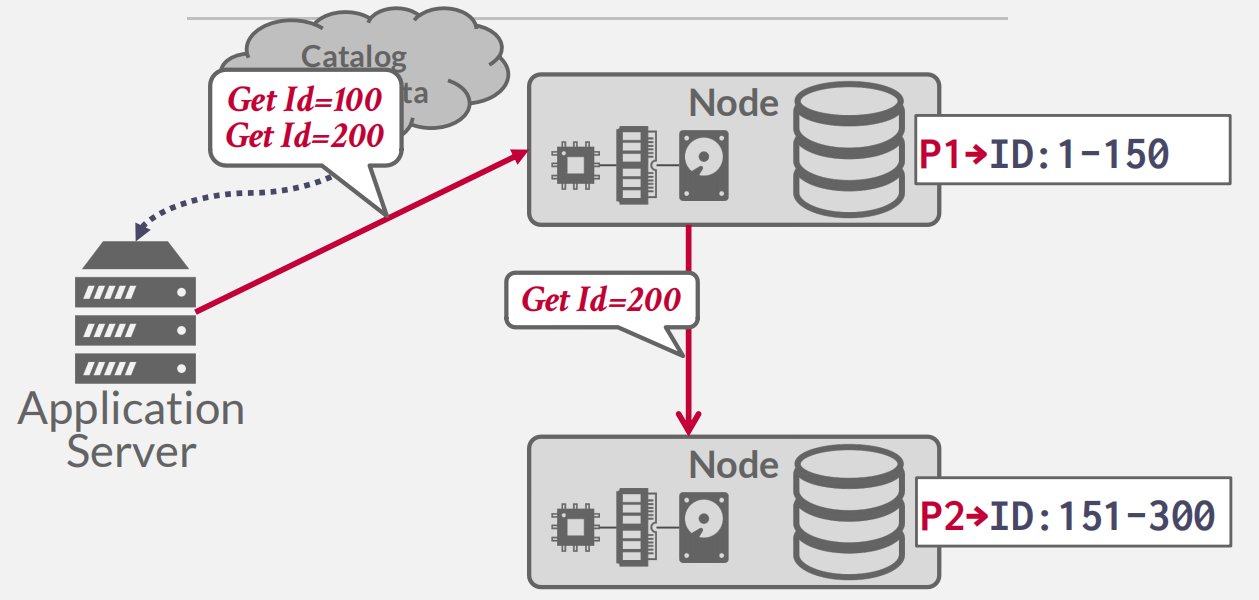
Design Issues
Homogeneous Nodes vs. Heterogeneous Nodes:
-
Homogeneous Nodes
-
Every node in the cluster can perform the same set of tasks (albeit on potentially different partitions of data).
-
Makes provisioning and failover “easier”.
-
- Heterogenous Nodes
- Nodes are assigned specific tasks.
- Can allow a single physical node to host multiple “virtual” node types for dedicated tasks.
-
DATA TRANSPARENCY
-
Applications should not be required to know where data is physically located in a distributed DBMS
-
Any query that run on a single-node DBMS should produce the same result on a distributed DBMS.
-
-
! In practice, developers need to be aware of the communication costs of queries to avoid excessively “expensive” data movement.
-
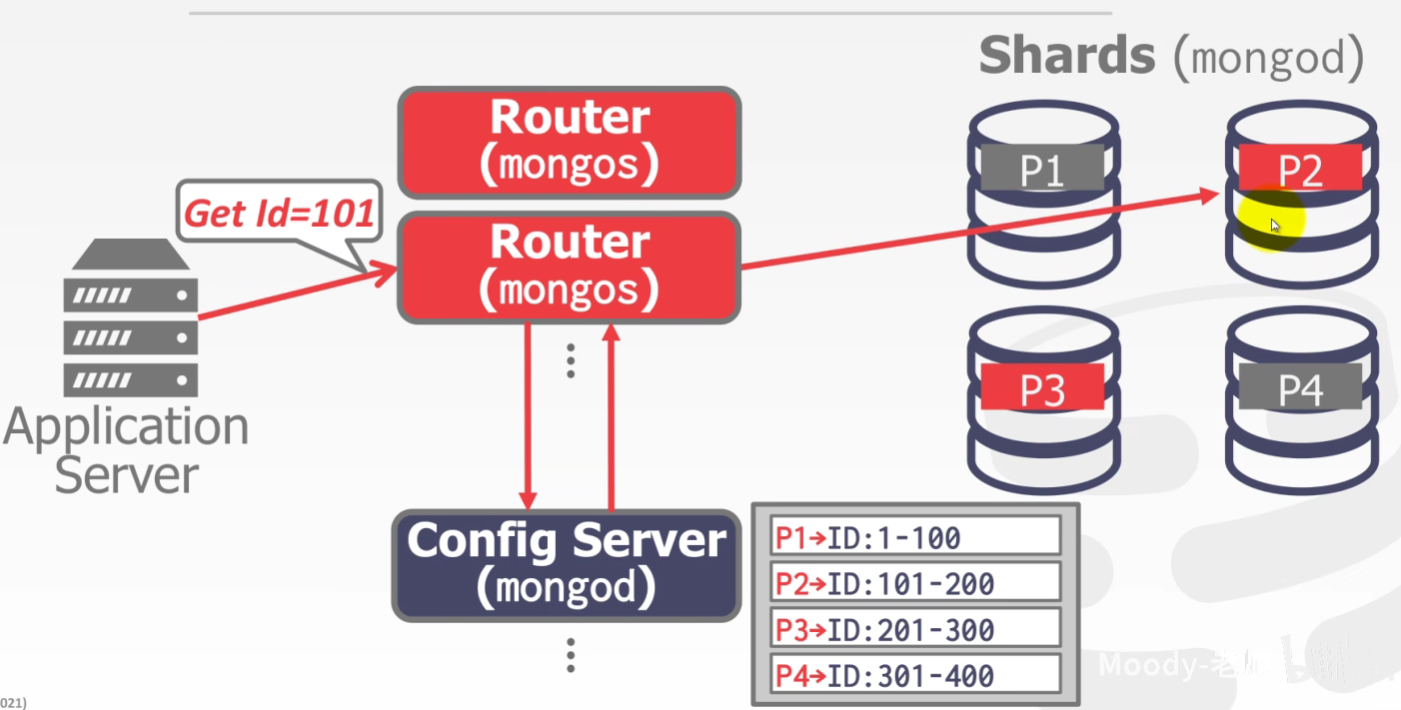
DATABASE PARTITIONING
-
Split database across multiple resources:
-
Disks, nodes, processors.
-
Often called “sharding” in NoSQL systems.
-
-
-
The DBMS executes query fragments on each partition and then combines the results to produce a single answer.
-
The DBMS can partition a database physically(shared nothing) or logically (shared disk).
-
NAÏVE TABLE PARTITIONING
-
Assign an entire table to a single node.
-
Assumes that each node has enough storage space for an entire table.
-
Ideal if queries never join data across tables stored on different nodes and access patterns are uniform.
-
主要弱点是JOIN
-
-
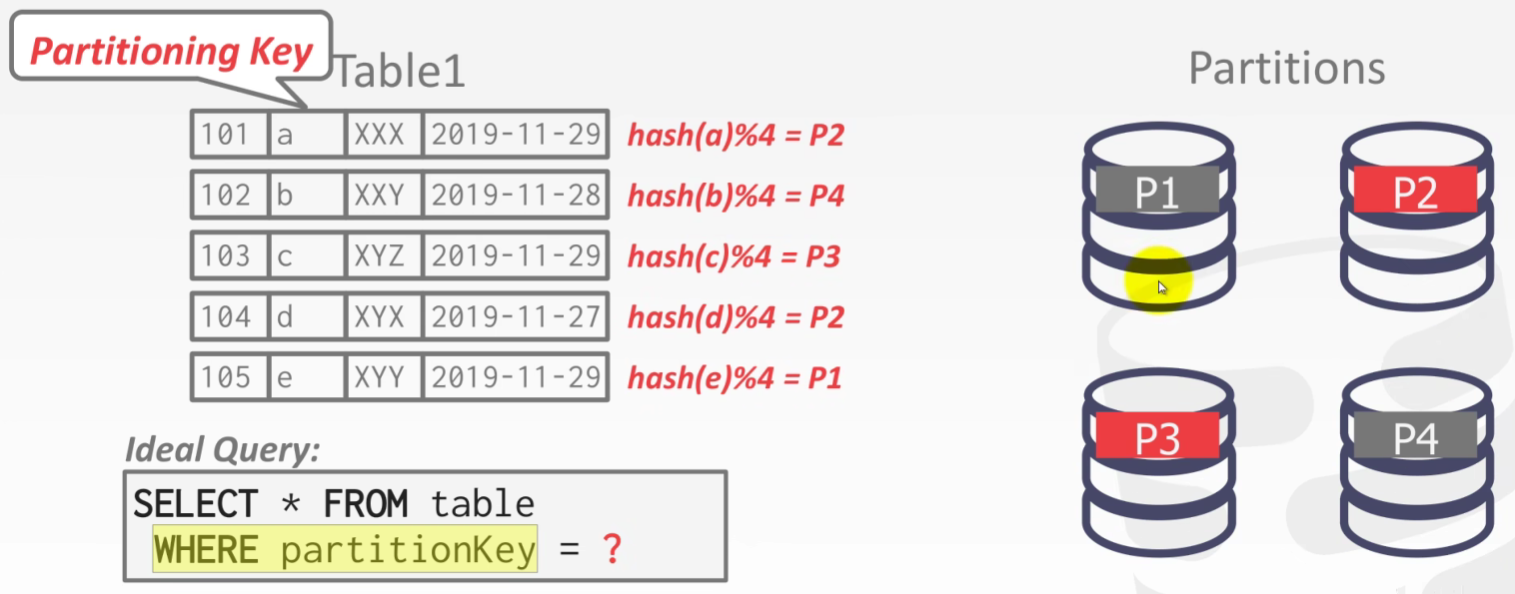
HORIZONTAL PARTITIONING
- Split a table’s tuples into disjoint subsets based on some partitioning key and scheme.
- Choose column(s) that divides the database equally in terms of size, load, or usage.
-
Partitioning Schemes:
→ Hashing
→ Ranges
→ Predicates

-
CONSISTENT HASHING
-
分布式系统常见的问题
-
八股:什么是一致性哈希?
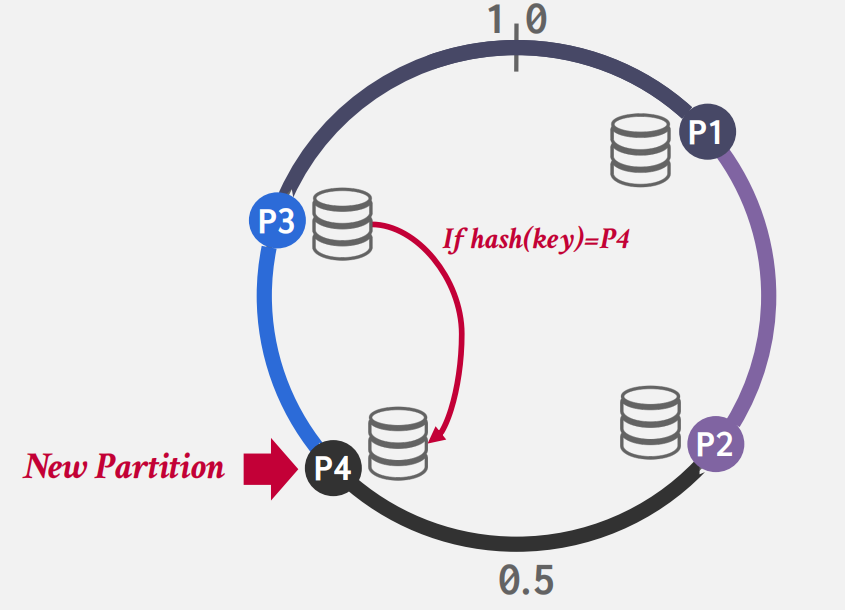
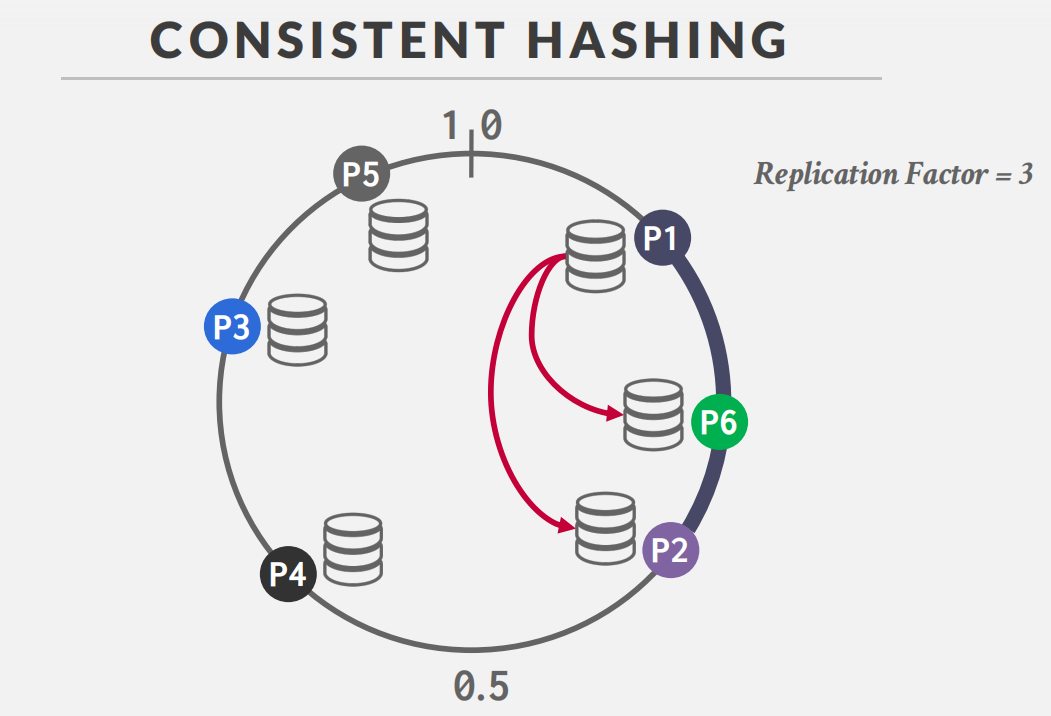
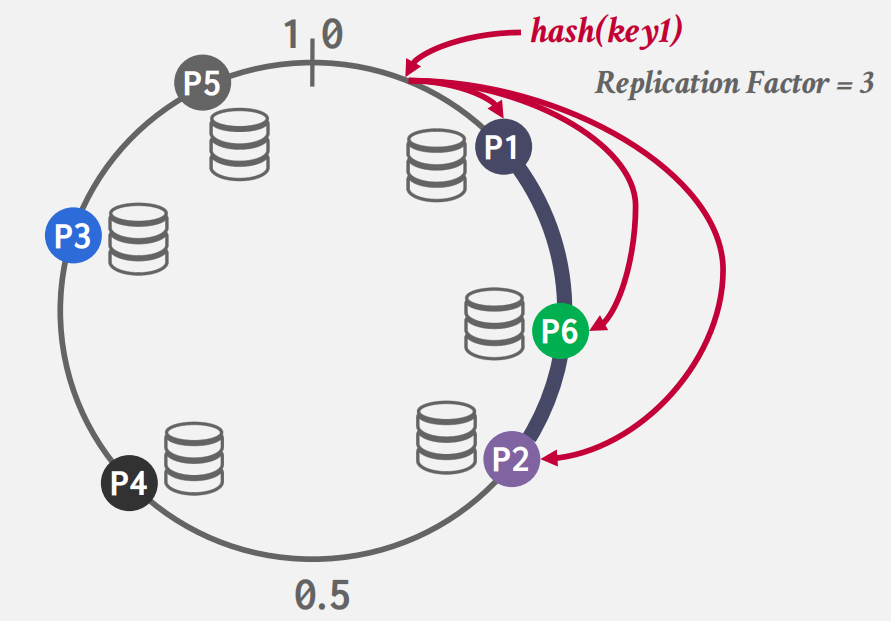
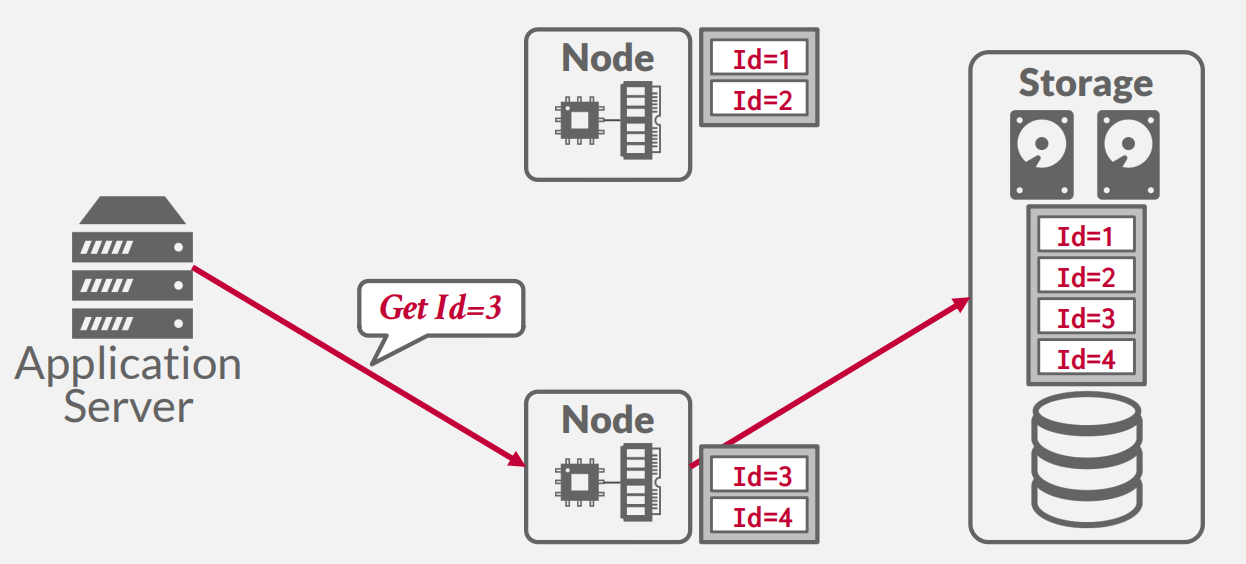
- 物理分区和逻辑分区
Distributed Concurrency Control
-
If our DBMS supports multi-operation and distributed txns, we need a way to coordinate their execution in the system.
-
Two different approaches:
-
→ Centralized: Global “traffic cop”(“交警”).
-
→ Decentralized: Nodes organize themselves.
-
-
TP MONITORS
-
A TP Monitor is an example of a centralized coordinator for distributed DBMSs. Originally developed in the 1970-80s to provide txns between terminals and mainframe databases.
-
→ Examples: ATMs, Airline Reservations.
-
Standardized protocol from 1990s: X/Open XA
-
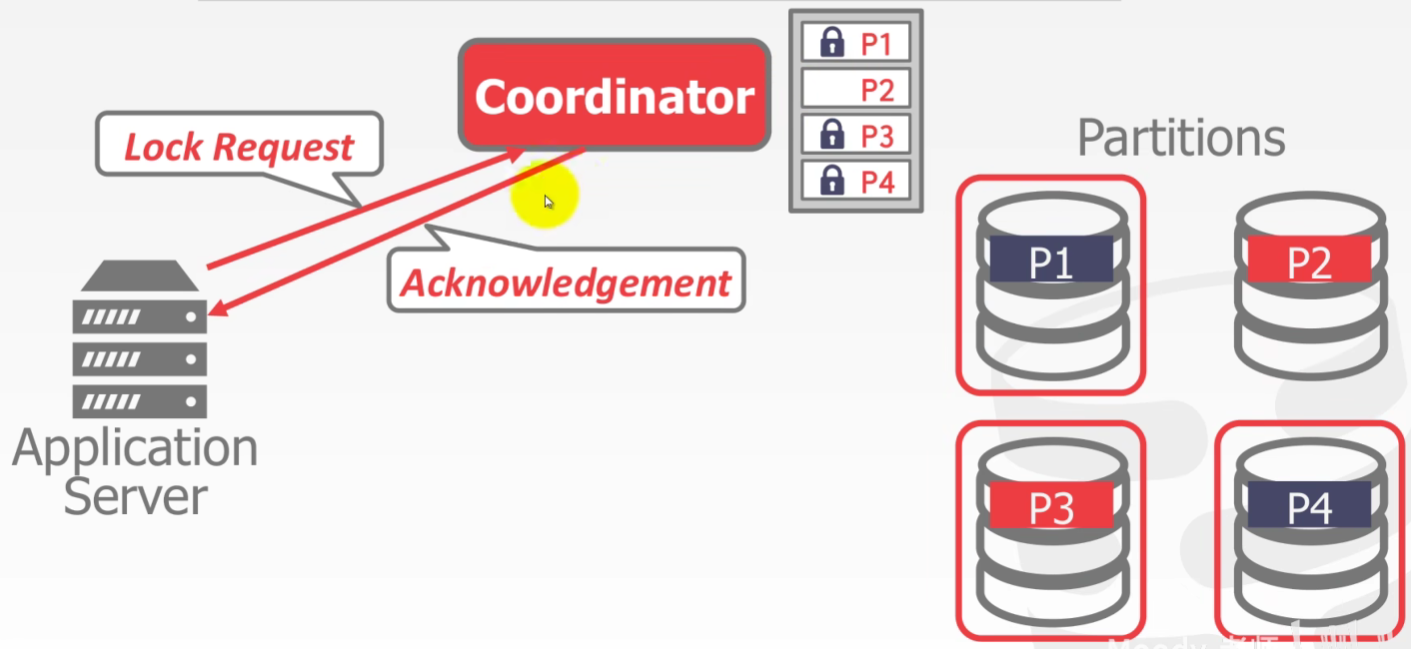
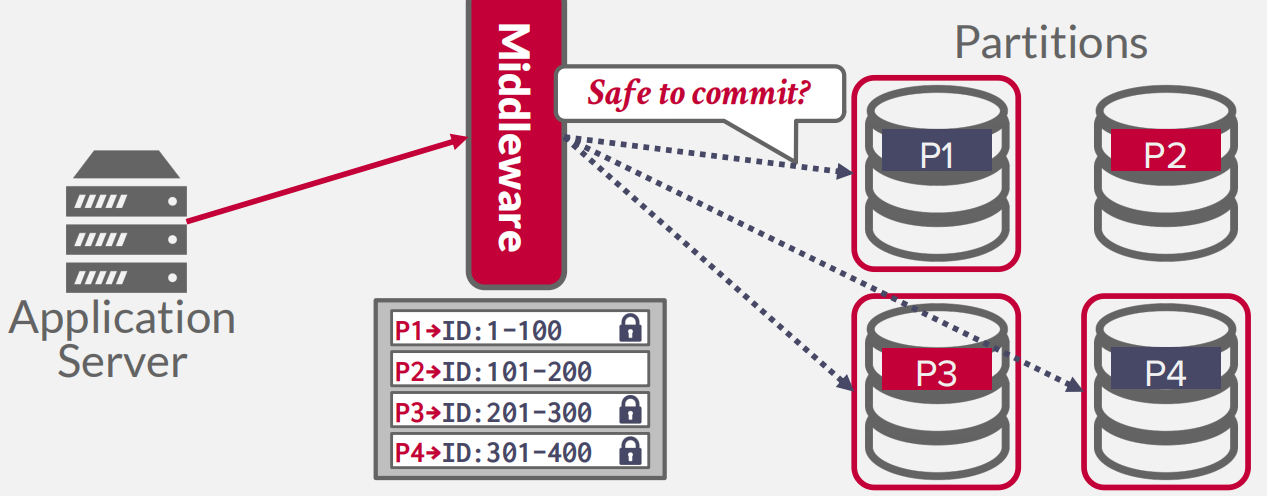
- 现在用的不多,单点很容易造成性能瓶颈
- DECENTRALIZED COORDINATOR
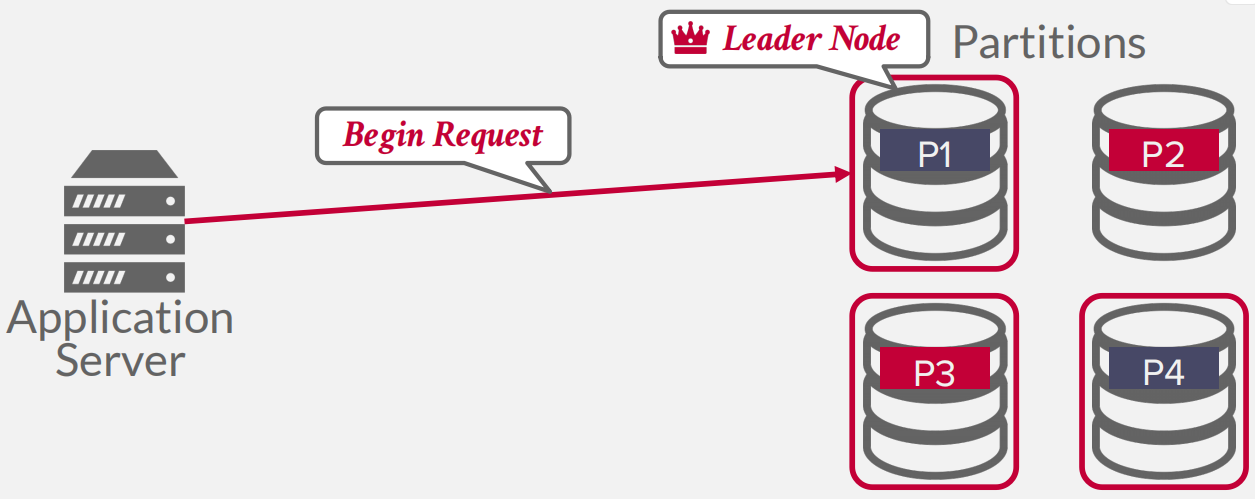
-
DISTRIBUTED CONCURRENCY CONTROL
-
Many of the same protocols from single-node DBMSs can be adapted.
-
This is harder because of:
- → Replication.
- → Network Communication Overhead.
- → Node Failures (Permanent + Ephemeral).
- → Clock Skew.(时钟不同步)
-