CMU 15-445 Lecture #03: Database Storage (Part I)
CMU 15-445 Database Systems
Lecture #03: Database Storage (Part I)
Storage
-
本课程讨论的都是存储在磁盘上的数据库,不考虑后期出现的内存数据库
-
补充计组的知识:设备离CPU越近,存储速度越快,内存越小,价格越贵
-
Volatile Devices
- 断了电就没有数据了
- 可以通过字节寻址快速随机访问,程序可以随机获取数据
- 这个地方基本就叫内存
-
Non-Volatile Devices
- 断了电也不怕
- 也是块/页可寻址的,但是如果程序要读取需要先load到内存
- 更适合顺序访问(加载到内存+局部性原理)
- 一般叫磁盘,这个课不区分机械盘和SSD
-
部分公司后面为了获取两个设备的长处推出了“持久内存”,但是本课程不会讨论,而且从Intel 2022开始逐步停产该系列产品来看,它没有想象中那么好
-
本课程主要是磁盘存储的数据库,我们必须明白一点,磁盘上面的数据必须要先load到内存中才能操作
Disk-Oriented DBMS Overview
-
数据库全部存储在磁盘上,数据库文件被数据组织成页,第一页是目录页
-
为了对数据库进行操作,DBMS需要将数据放入内存,这个时候会使用一个缓冲池来管理在磁盘和内存之间移动的数据
-
例子:以DBMS中的查询为例,执行引擎会让缓冲池请求特定的页面,缓冲池将该页加载到内存,然后返回给执行引擎目前内存中该页的指针,使得执行引擎可以进行下一步的工作
DBMS vs. OS
-
DBMS和OS的虚拟内存都涉及到了cache和disk调用的问题,那么是否可以在DBMS中使用mmap呢
- 不可以
- mmap一旦出现地址错误会block,这对于DBMS的性能来说是不能接收的
- mmap是为OS设计的,对于cache和disk的调用,DBMS其实更应该根据自己的情况来定制化其他方案
-
但是我们和disk交互的时候仍然可以使用下面的OS调用,这些是符合我们期望的
• madvise: Tells the OS know when you are planning on reading certain pages.
• mlock: Tells the OS to not swap memory ranges out to disk.
• msync: Tells the OS to flush memory ranges out to disk.
- 对于DBMS这种如此吃性能的设施,很多解决方案还是需要手搓定制化,而不是依赖OS的调用
File Storage
-
DBMS将数据库作为文件存储在磁盘上,有些使用文件层次结构,有些使用单个文件(比如SQLite)
-
OS是不知道这些文件存储的是什么,只有DBMS才能读懂和操作它们(有特定的编码)
-
DBMS的存储管理器负责管理数据库的文件。它将文件表示为页面的集合,它还跟踪哪些数据被读取和写入到页面,以及这些页面中有多少空闲空间
Database Pages
-
DBMS会将多个文件组织成固定大小的数据块,这个东西就叫页
-
页面可以包含不同的数据类型,但是大多数系统是不会在页面中混合使用这些类型的
-
有些系统要求页面是自包含的,这意味着读取每个页面所需的所有信息都在页面本身上
-
每个页面都有一个唯一的标识符
-
如果数据库是单个文件,那么页id可以只是文件偏移量。大多数DBMS都有一个间接层,它将页id映射到文件路径和偏移量。系统的上层将要求提供特定的页码。然后,存储管理器必须将该页码转换为文件和偏移量以查找该页
-
大多数的页大小都是固定的,不然难以管理内存(内存碎片)
-
DBMS中的三种页面
- Hardware page (usually 4 KB).
-
OS page (4 KB).
-
Database page (1-16 KB).
-
硬件页设计的小是为了能够利用硬件的条件原子性写入,但是到了数据库的页就无法保证了,所以需要使用额外的措施保证原子性
Database Heap
- 数据库的页“堆”成一个文件的方式
- 也要能够有创建页,遍历页,删除页的操作,那么页之间怎么组织?
- Linked List
- Page Directory
Page Layout
-
Every page includes a header that records meta-data about the page’s contents:
-
Page size.
-
Checksum.
-
DBMS version.
-
Transaction visibility.
-
Self-containment. (Some systems like Oracle require this.)
-
-
数据的存储方案
-
Tuple-oriented:按照真实数据一行一行存
-
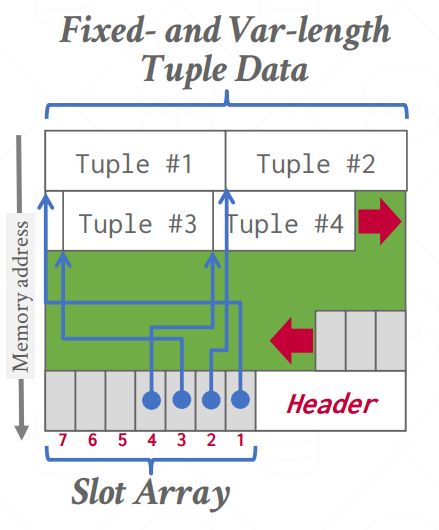
如何避免内存碎片化问题:Slotted Page结构,索引在一个区,剩下的空间存储数据

Slotted Page -
定位:page_id + offset/slot
-
-
Log-Structured:存操作日志
-
Tuple Layout
- 一组数据存储在磁盘上面就是bytes,需要我们附加其他的信息进行解析

-
Tuple Header: Contains meta-data about the tuple.
-
并发控制信息(为了事务安全)
-
NULL值的Bit映射(解析Tuple需要的信息)
-
注:不需要存结构信息(每一个Header都存一下内存浪费太多了)
-
属性通常按照创建表的时候指定的数据存储
-
大多数DBMS不允许一个元组超过一个页面的大小
-
-
Unique Identifier
- 最常见的是page_id+offset
- 应用程序不能直接用这些,只能用主键这类的属性(因为这个东西会因为内存整理而更改,程序员只能和DBMS这部分的管理系统用主键交流,由这个系统进行映射)
-
Denormalized Tuple Data: If two tables are related, the DBMS can “pre-join” them, so the tables end up on the same page. This makes reads faster since the DBMS only has to load in one page rather than two separate pages. However, it makes updates more expensive since the DBMS needs more space for each tuple.
- 两个表如果总是需要JOIN,那我提前给你在内存中连好
- 理论上可行,现实中会让插入等的复杂度变的很高,目前这种方案已经被废止