CMU 15-445 Lecture #06: Buffer Pools
CMU 15-445 Database Systems
Lecture #06: Buffer Pools
Introduction
- DBMS需要负责管理数据在内存和磁盘之间移动,大多数情况下数据不能在磁盘中被处理,而是需要加载到内存中,处理完成后再写回磁盘,这个过程就需要Buffer Pools来进行管理,使得DBMS的其他部分可以像在内存中处理所有数据那样进行操作
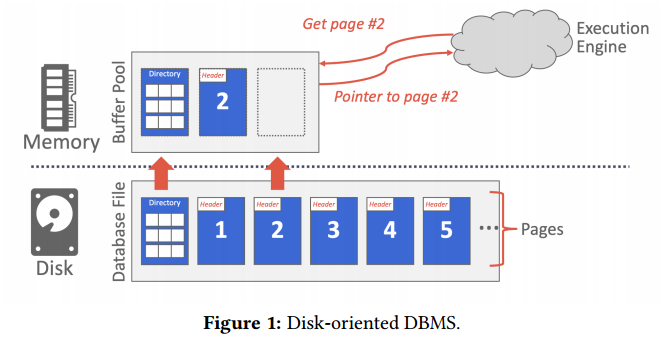
- 一个DBMS需要考虑下面的两个方面
- Spatial Control: refers to where pages are physically written on disk. The goal of spatial control is to keep pages that are used together often as physically close together as possible on disk to possibly help with prefetching and other optimizations.(写磁盘的时候把需要经常一起用的页尽量写到磁盘的一块地方,这样下次用也能够一把加载到Buffer Pool里面)
- Temporal Control: is deciding when to read pages into memory and when to write them to disk. Temporal control aims to minimize the number of stalls from having to read data from disk.(何时写回磁盘,对于一些热点写数据没有必要写一次刷一次盘,完全可以写好多次刷一次磁盘,因为刷盘的代价太大了)
Locks vs. Latches
-
英语和概念性的问题
-
Locks: A lock is a higher-level, logical primitive that protects the contents of a database (e.g., tuples, tables, databases) from other transactions. Database systems can expose to the user which locks are being held as queries are run. Locks need to be able to roll back changes.(逻辑上面的锁,比如行锁/表锁/库锁,不关心底层实现,用于理论上面的讨论,为了防止死锁,一般这种锁都可以回滚)
-
Latches: A latch is a low-level protection primitive that the DBMS uses for the critical sections in its internal data structures (e.g., hash tables, regions of memory). Latches are held for only the duration of the operation being made. Latches do not need to be able to roll back changes. This is often implemented by simple language primitives like mutexs and/or conditional variables.(Locks的具体实现,比如数据竞争的区域是哪,用互斥锁还是信号量,悲观锁还是乐观锁)
Buffer Pool
-
It is organized as an array of fixed-size pages. Each array entry is called a frame. 缓存池的本质就是内存里面的一块固定的数组,这个里面的一个元素就叫frame了,但是其实和page是一个东西
-
page directory:在数据库的磁盘上还维护了一个page directory,这个东西存的就是页id到页在磁盘物理位置的映射,所以说这个如果修改了必须写回到磁盘上,这样DBMS重新启动的时候才能找到,他也通常回一直在内存里面,因为你找页必须要先通过page directory去找页的物理位置
-
Buffer Pool Meta-data:缓存池必须要存储一些meta-data,从而保证正确性和提高缓存池的效率,常见的一些meta-data
-
page table:这个是内存中的一个hash表,它的映射是页面id $\rightarrow$ 这个页在缓存池中的帧位置,因为页在缓存池里面的顺序和磁盘中的顺序往往不一致,所以需要page table来做这个额外的间接层,除了页在缓存池中的位置,page table还维护了其他meta-data,比如一个脏标志(说明这个页是不是脏页),引用计数器(有哪几个事务在用它),这个和page directory的一个大的区别就是他不用记在磁盘上
-
dirty-flag:这个就是上面page table维护的一个页的meta-data之一,当有线程对buffer pool中的某个页面进行修改的时候这个标志会被设置,这提醒这个页在被踢出buffer pool的时候必须要刷盘
-
Pin/reference counter:这个也是上面page table维护的一个页的meta-data之一,主要是记录有几个线程正在访问该页,线程必须在访问该页之前增加counter,如果counter > 0,那么该页就无法被驱逐,counter不会管理并发事务那些东西,如果当前缓冲池的所有页都无法被踢,而且已经满了,就会抛出OOM(out-of-memory)的错误
-
-
Memory Allocation Policies
-
Memory in the database is allocated for the buffer pool according to two policies
-
Global policies: 考虑所有事务,来找到分配内存的最佳决策
-
local policies:做出决策的时候只考虑单个事务,即使他不适合整个工作负载,本地策略将帧分配给特定的事务,而不考虑并发事务的行为。但是,它仍然支持事务之间共享帧
-
Most systems use a combination of both global and local policies.
-
Buffer Pool Optimizations
-
Multiple Buffer Pools
- DBMS可以开好多个缓冲池,比如按照类型分(索引缓冲池,数据缓冲池),同一类似使用hash再分到不同的区域,这样每个缓冲池都可以选择适合自己的存储策略,同时分成多个缓存池也避免了一个缓冲池频繁的锁竞争问题
- Object IDs and hashing are two approaches to mapping desired pages to a buffer pool.
- Object IDs:维护一个id到缓存池区域的映射,这样根据页的id就能分配到对应的缓存池中,而且这个映射自己维护,你可以把分配的策略做的更细更智能,代价就是这个映射也是额外的内存开销
- hashing:对页的id做hash来确定到那块缓存池
-
Pre-fetching: 根据查询计划来对预取页面进行优化,比如处理第一组页面的时候把第二组页面给预提取到缓冲池中(这个在顺序扫描的时候常用),在索引扫描的时候处理某个叶子页的时候可以把这个叶子页的下一页也预提取到缓冲池中,这都提高了效率(这个下一页都是逻辑上的,不是物理上的)
-
Scan Sharing (Synchronized Scans):尽量复用缓冲池里面的数据,比如第一个事务是SELECT ALL FROM A,第二个事务也是SELECT ALL FROM A,这个时候第一个事务把页3~6加载到缓冲池里面了,那第二个事务可以从这个地方跟着第一个事务开始扫,等把后面那些跟着第一个事务扫完之后再去扫前面的表,或者说这个时候有SELECT ALL FROM A LIMIT 100这种事务,可以直接到缓冲池里面找一张表拿100条数据就走(这也是为什么每次查询结果不一样的原因)
-
Buffer Pool Bypass:全表扫描(可能加SORT),大型JOIN这种东西大概率这次查询完了之后近期不会再差,这种数据除了查询时加载到内存中查询完了就扔出去,来节约缓冲池的资源
Buffer Replacement Policies
-
要求是准确+快+开销小
-
COLCK:时钟轮询,如果有frame被访问过给打上标记,时钟循环看每一帧,有标记的清空标记,没有标记证明最近没人访问你,给踢出
-
LRU/LRU-K:看这两篇就够了
-
localization per query:驱逐页只驱逐自己事务相关的,防止把其他事务的页给驱逐
-
priority hints:给一些页上标记,告诉缓存池这页不要随便清理,比如索引的根节点,这种东西轻易不会清理
-
Dirty Pages:踢出页的时候页是否是脏页对于踢出页时候的处理不一样
- 非脏页:直接删除就行
- 脏页:要刷回磁盘,当然能写不回去就尽量先不写回去(后面会讲WAL,redo-log),一定要先写回再踢出
Disk I/O and OS Cache
- 操作系统本身也有cache的管理,但是和DBMS要求的差的很多,所以DBMS的缓存管理都是定制化的,不依赖操作系统的调用
Other Memory Pools
-
除了缓存页还会缓存别的数据(比如热点查询数据,这里有点像NoSQL的一些功能了)
-
Sorting + Join Buffers
-
Query Caches
-
Maintenance Buffers
-
Log Buffers
-
Dictionary Caches
-