数据库SQL引擎基础(OceanBase-MiniOB)
目录
数据库SQL引擎基础$(OceanBase-MiniOB)$
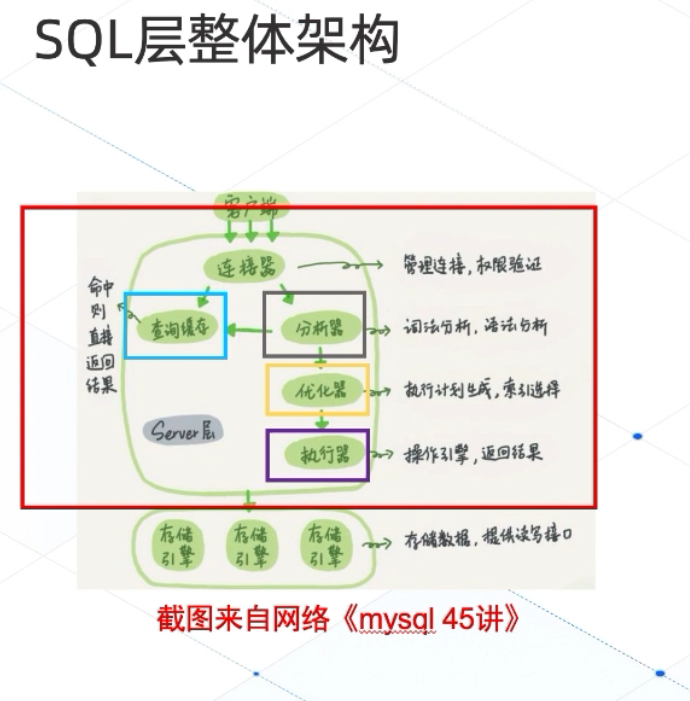
引擎架构概览
-

MySQL的引擎架构(红框) -
OceanBase引擎架构 -
一条SQL语句的常见结构
|
|
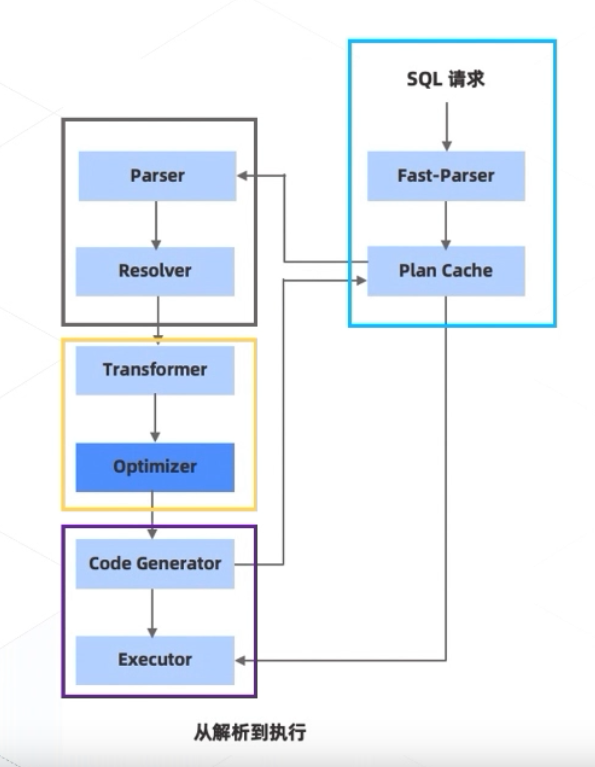
解析 & 执行SQL
Parser
-
将SQL转化为数据库能识别的数据结构

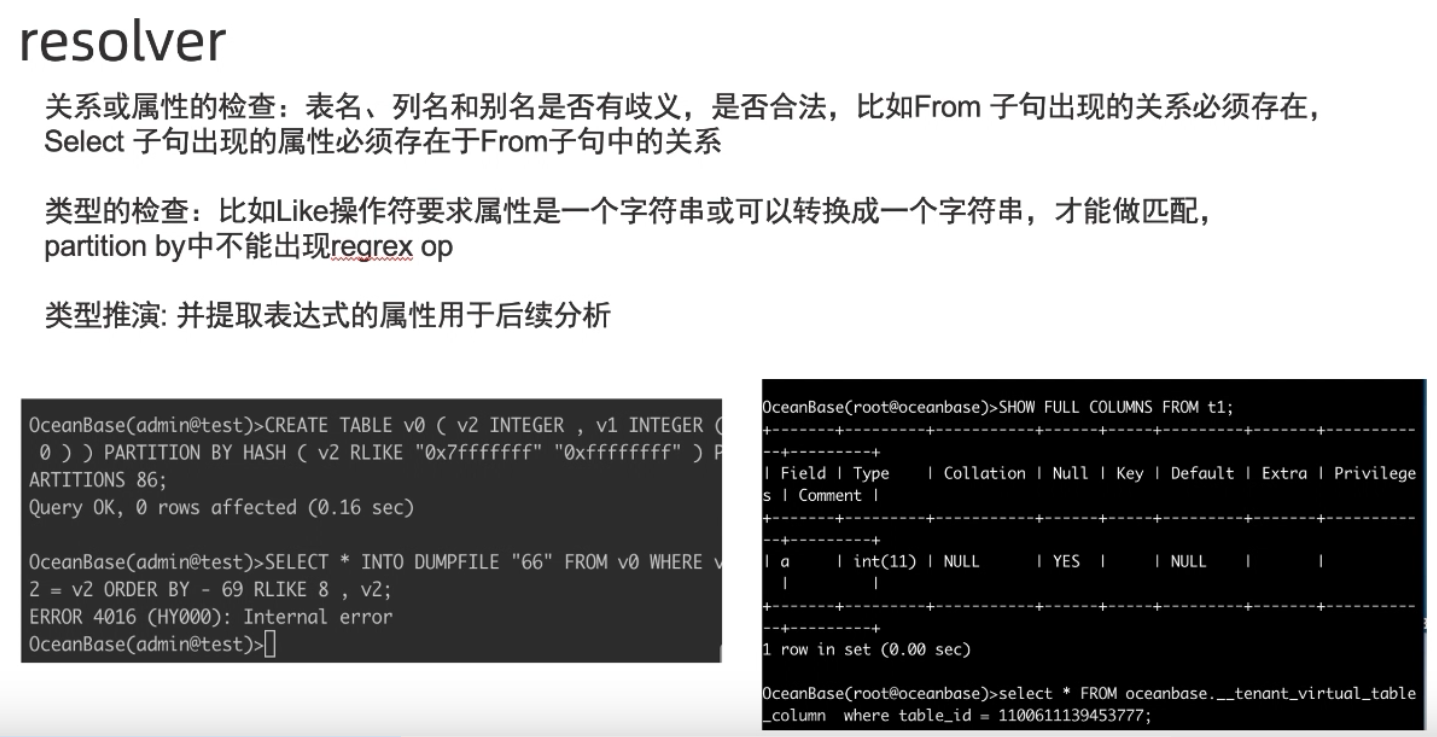
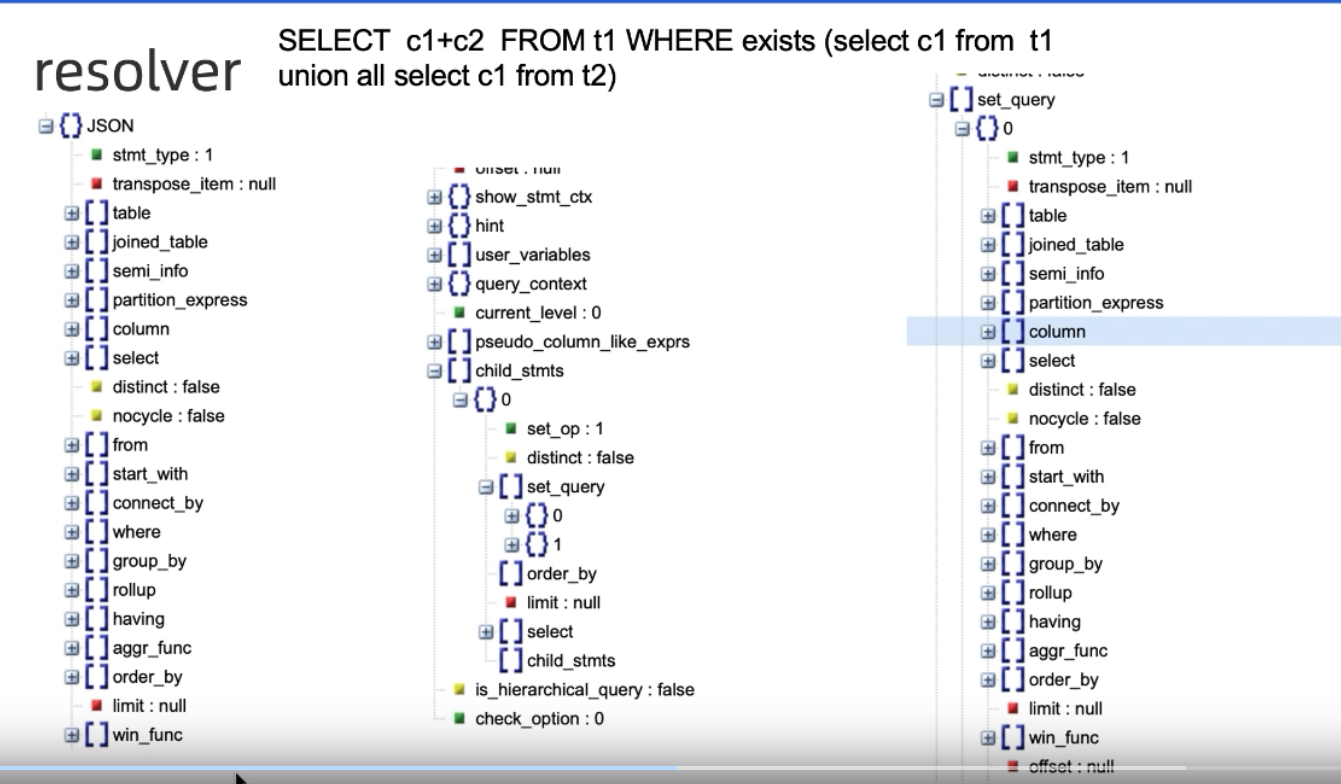
Resolver
-
-
同时也会将SQL转化为一个新的数据工程性的数据结构
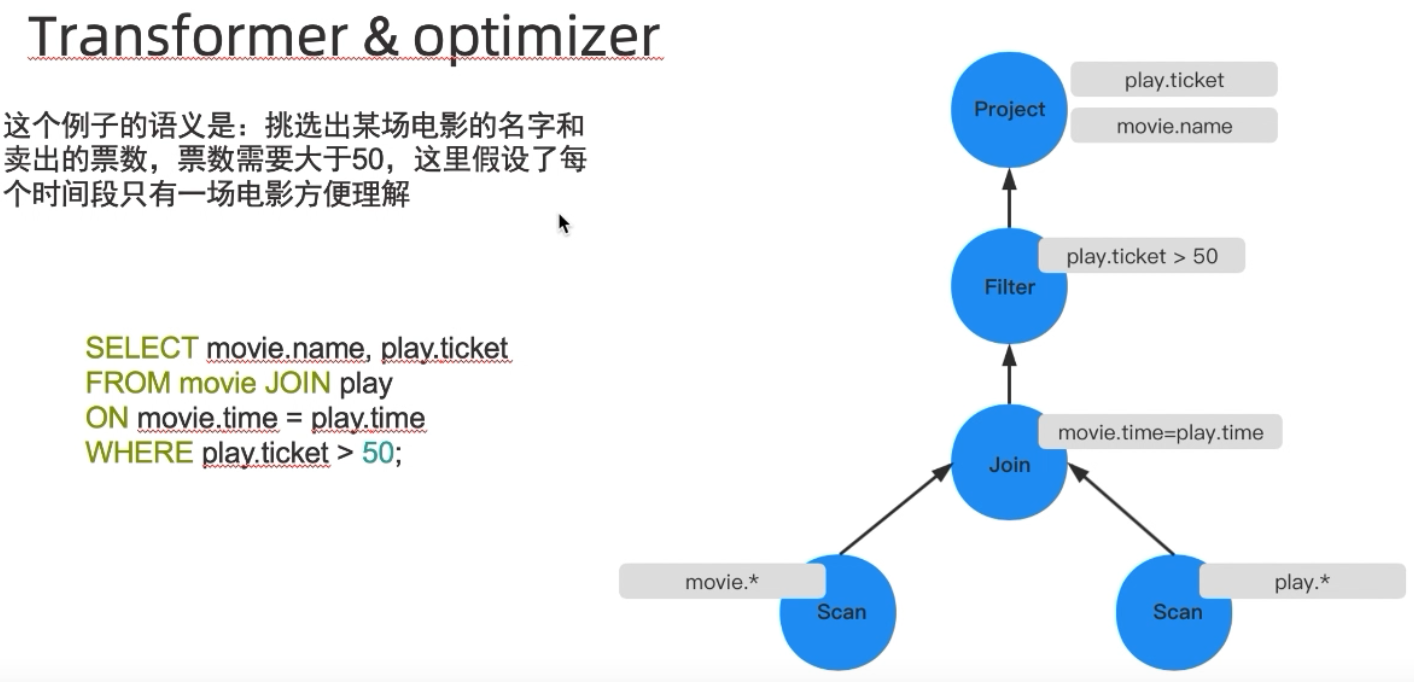
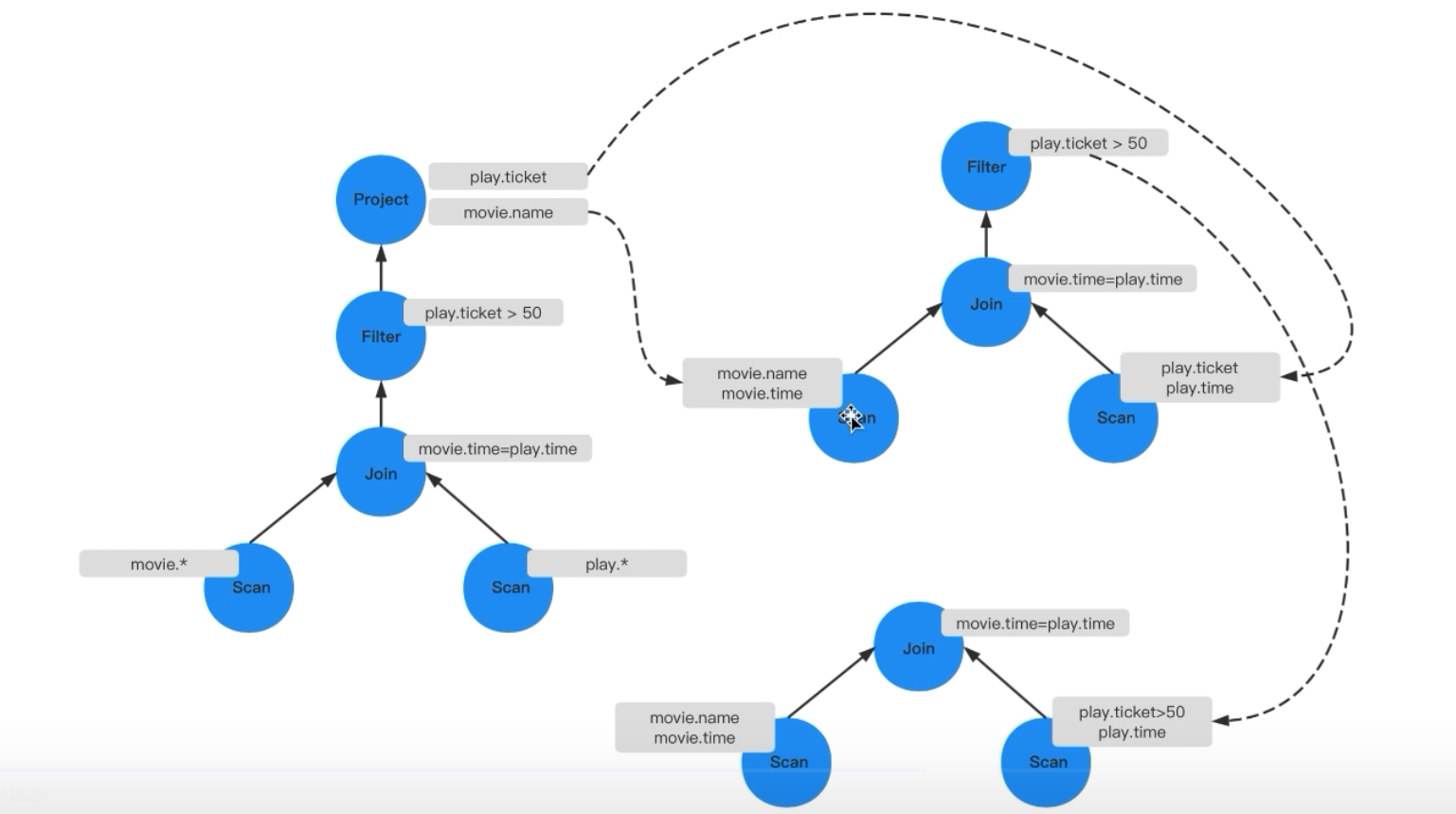
Transformer & Optimizer
- 在这两层主要是要把上一层的结构转化为火山模型中的“算子树(自己造的词,方便理解)”,同时对查询计划进行优化
-
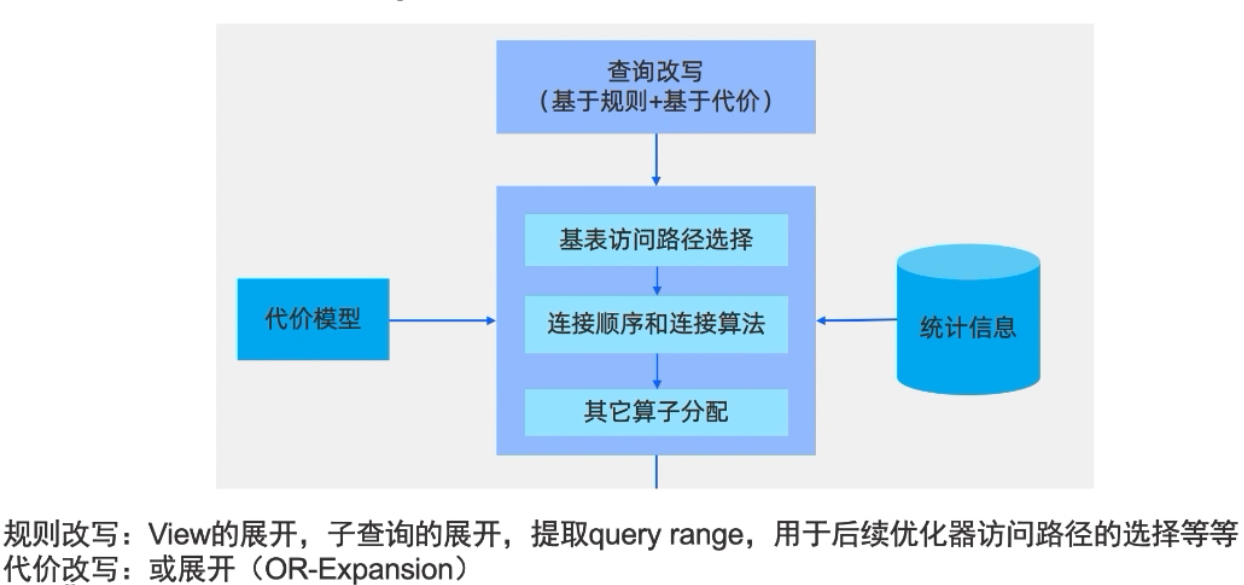
生成查询计划 -
优化查询计划 -
OceanBase的优化计划部分
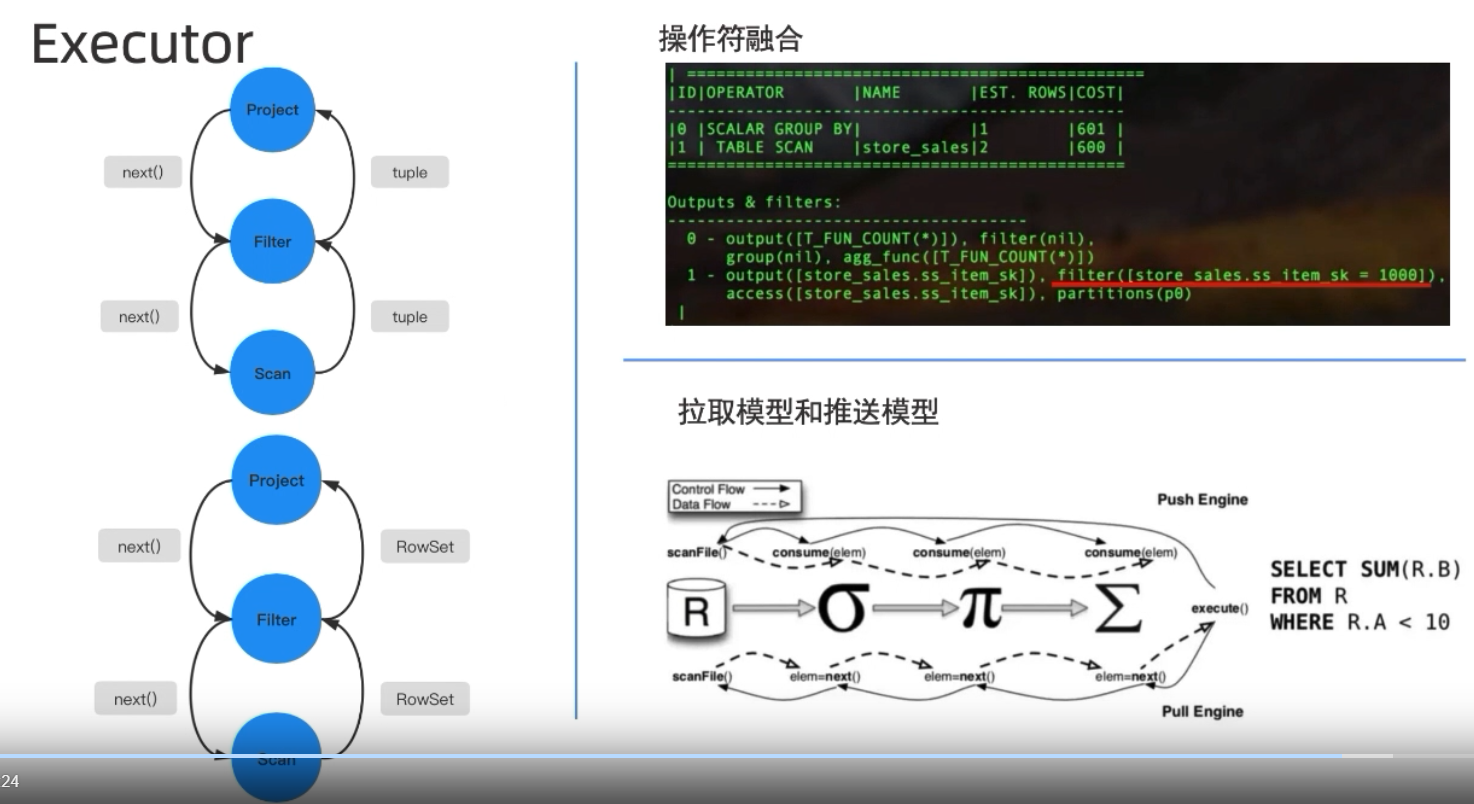
Executor
-
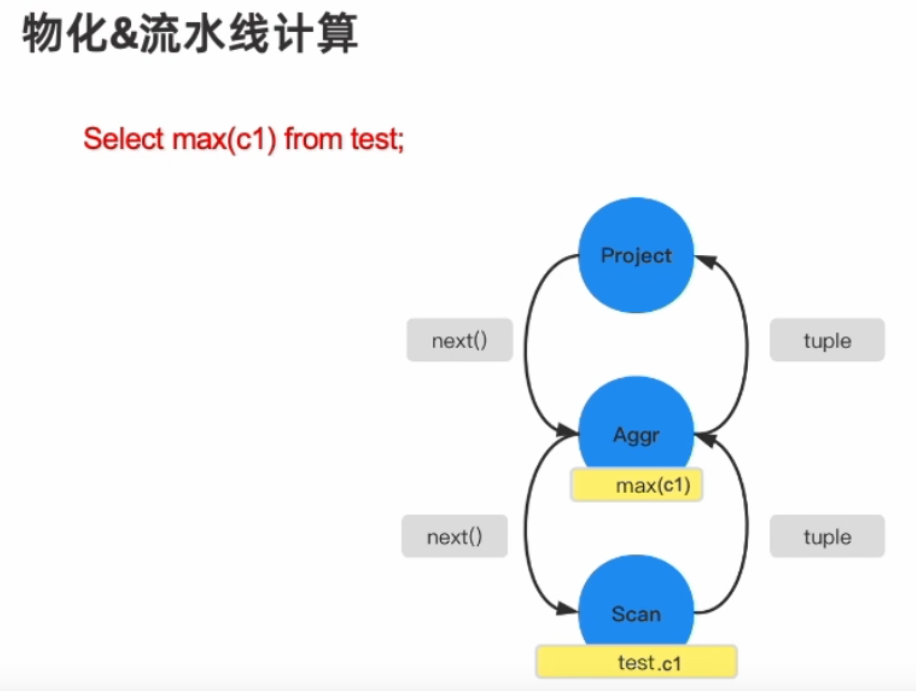
常见的就是火山模型
-
所有的代数运算都被看成了operator(也就是图里面的一个节点)
-
每一层的operator都将下一层的operator看成一张表,每次调用next()都是获取表中的一张数据
-
优点:简单,让查询计划变得富有弹性,使其便于优化
-
缺点:大量的虚函数调用,流水线模型的破坏,不能让CPU乱序执行带来的效率低下(但是这个模型在90年代诞生,当时I/O的问题远比CPU的问题要重要的多)
-
关于火山模型的问题和向量化|类JIT代码动态编译/生成,比较好的两篇文章,读完收获很大
-
其他优化的点
- 操作符融合:比如把Scan和Fillter融合在一块执行
- 拉取模型和推送模型:火山模型中应该是上层的算子来进行推动,但是推送模型希望是下面的算子往上推,而不是从上面拉取
-
-
下推引擎中,下层的operator拿到了上层的要求后直接带着要求返回结果,而不是想上拉引擎那样只是傻傻的返回tuple

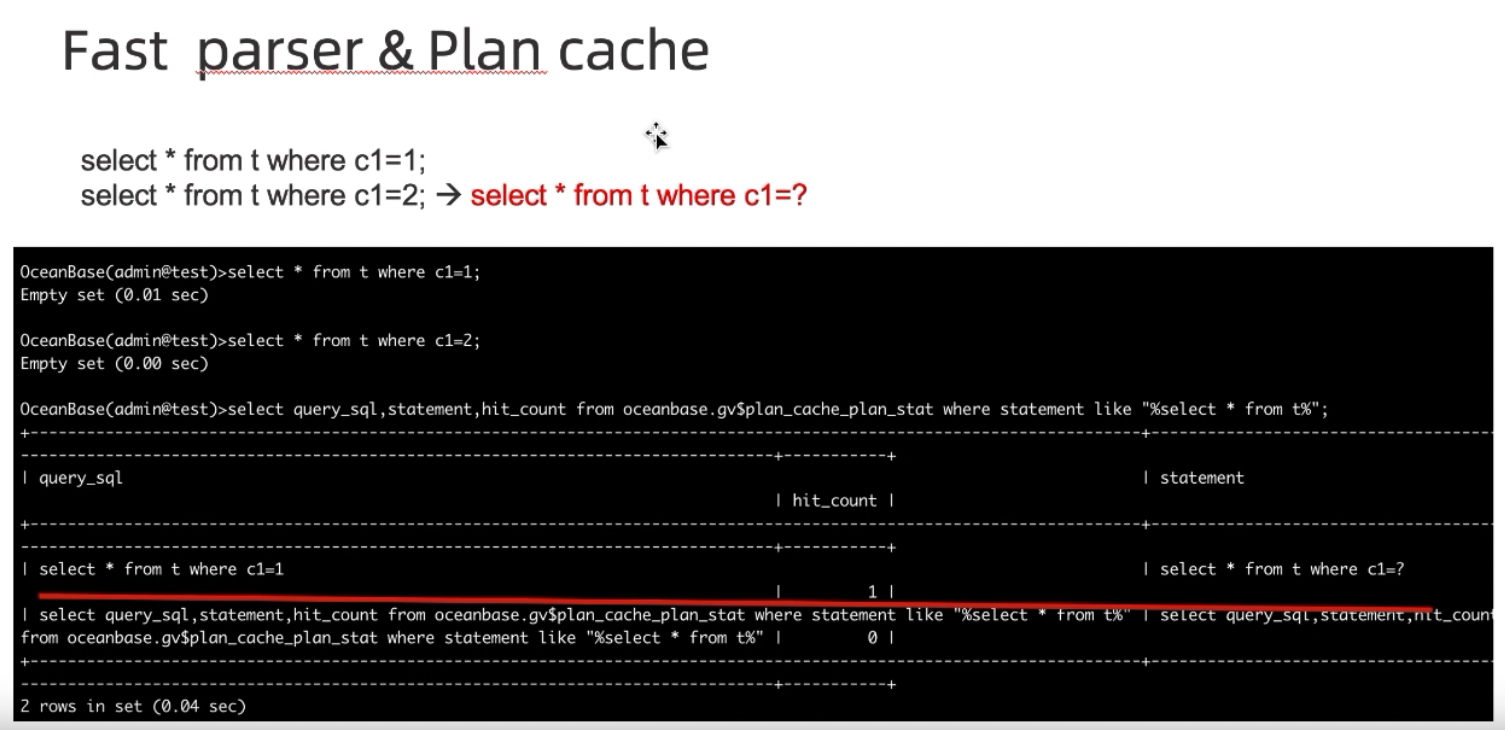
Fast Parser & Plan Cache
-
把之前SQL解析出来的Plan给进行缓存,这样就可以避免大的,频繁调用的SQL不停的被解析造成的效率低下 -
OceanBase的优化:SQL可以先找到和自己相似的SQL进行数值上的替换,这样自己的查询计划也就出来了
常见名词
- 一个高效的SQL有很多考虑因素
- disk
- memory
- cpu
- SQL计划是否更优,选择的算法是否合理
基础关系代数符号 & 优化操作


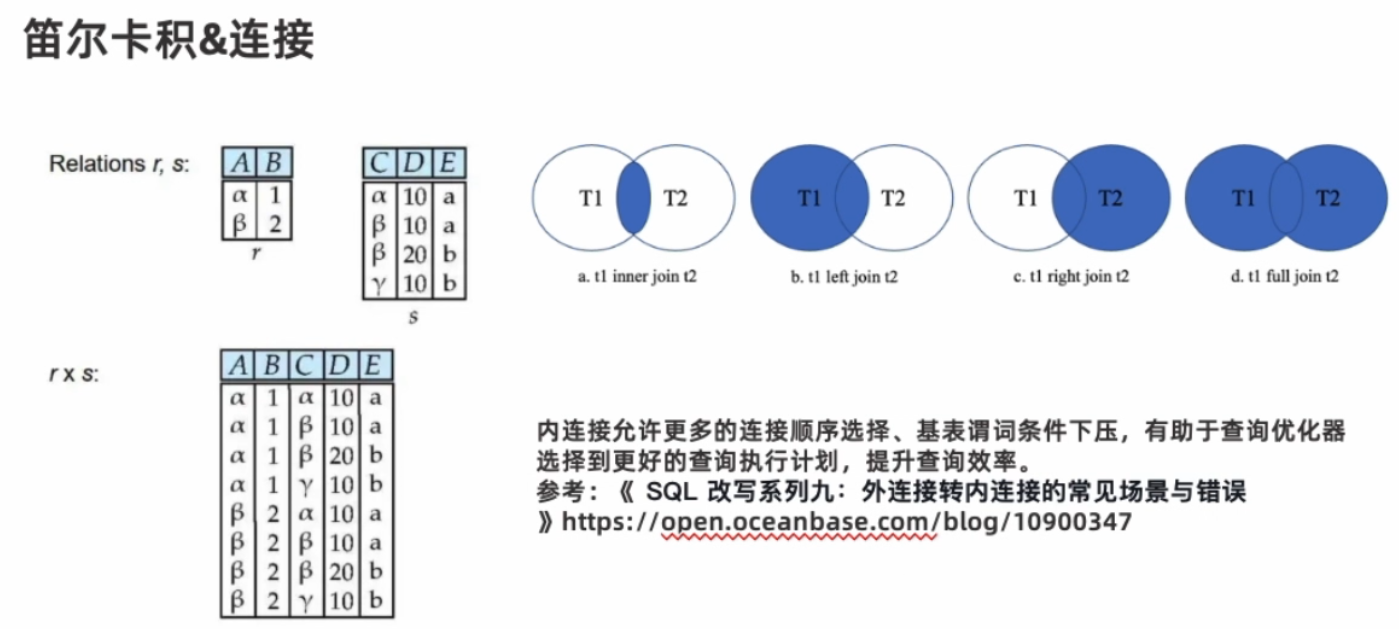
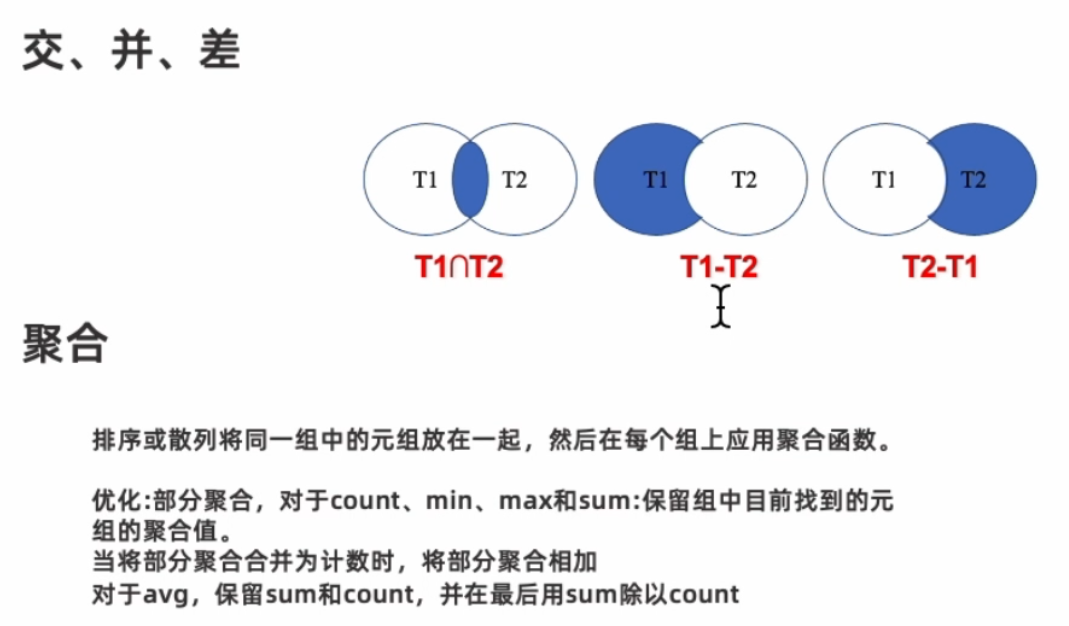
关系表达式的等价规则转换(当成工具字典就行)
-
-
-
运算律优化的例子,选择下推,连接变小 -
由于连接有交换律,根据排列组合,极少的连接就会造出来非常多的计划,但是实际上数据库不可能挨个去算每个计划的代价
-
Interesting sort order(如果前面连接出来的结果有序,那么后面优先选择有序的表进行连接,这样可以使用sorted join来加快顺序)


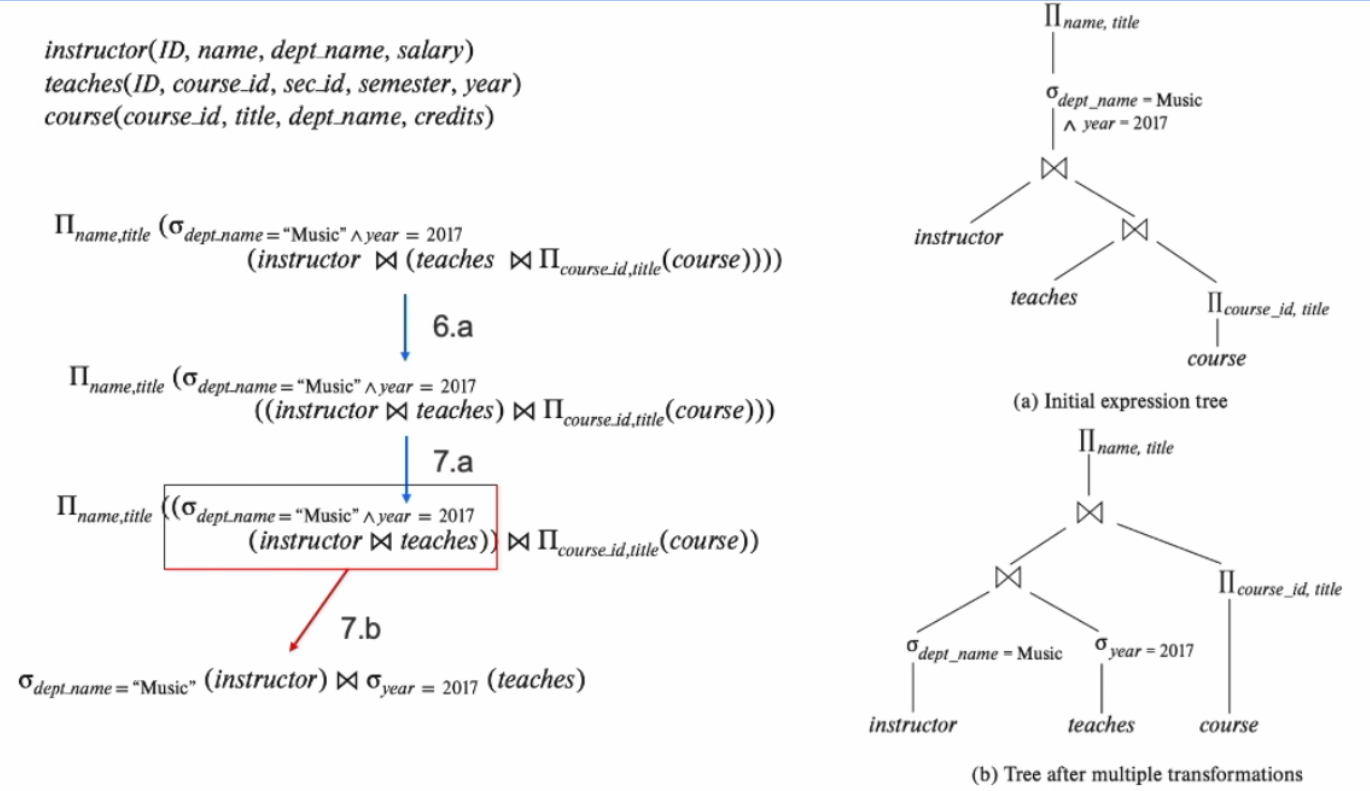
左深树
- 根据前面的优化,左深树比右深树更有优势
启发式规则
-
多年经验和论文总结而成
-

统计信息
-
-
根据选择率和基数和基数来决定是否使用索引还是用全表(不一定索引比全表扫描强,比如sex这种列)

尾巴
- 留一篇文章下周工位摸鱼读(又该申请权限力)
- 写到445的Lab3感觉需要拓展的知识点开始变得异常的多(因为这部分本身的比较广泛,前面的bpm和hash index都比较窄和单一),实验指导书看了一半就附带被推动着看了好几篇有关火山模型和向量化处理的文章(主要是工位上只能看这些,知乎那两篇确实质量很高,看完收获很大),和之前在牛客上认识,现在在2012实验室做db的朋友摸鱼聊天,看他解决bug的同时发现指令流水线,内存对齐,编译链接,并行计算这些计算机架构|操作系统的知识其实在这种底层的领域会不停的碰到,有一个扎实的基础会加快你发现bug原因的速度,看来当时的量化方法,csapp的知识不能再吃灰了,有时间还是得补一下自己的基础