Operating System Chapter6 并发控制:同步
Operating System
$Nanjing\ University\rightarrow Yanyan\ Jiang\newline$
Update in 2023-03-10 20:48
在洲的提醒下,✋才发现原来租国外电话号那个网站可以有访问ChatGPT的教程,之前首尔线和美国线都因为反IP给ban了,这网站都没仔细看,真是血亏
Overview
复习
- 互斥:自旋锁、互斥锁、futex
是时候面对真正的并发编程了
本次课回答的问题
- Q: 如何在多处理器上协同多个线程完成任务?
本次课主要内容
- 典型的同步问题:生产者-消费者;哲学家吃饭
- 同步的实现方法:信号量、条件变量
线程同步
同步 (Synchronization)
-
两个或两个以上随时间变化的量在变化过程中保持一定的相对关系
-
iPhone/iCloud 同步 (手机 vs 电脑 vs 云端)
-
变速箱同步器 (合并快慢速齿轮)
-
同步电机 (转子与磁场速度一致)
-
同步电路 (所有触发器在边沿同时触发)
- 异步 (Asynchronous) = 不同步
- 上述很多例子都有异步版本 (异步电机、异步电路、异步线程)
Update in 2023-03-11 14:00
乌班图打赢复活赛成功 $\Longrightarrow$ 大爹复活博客《GParted给ubuntu系统磁盘resize大小时候出现cannot resize read-only file system解决办法》
下午继续拿着乌班图听课
并发程序中的同步
-
并发程序的步调很难保持 “完全一致”
- 线程同步:在某个时间点共同达到互相已知的状态,(先整完的等另一个
-
再次把线程想象成我们自己
- NPY:等我洗个头就出门/等我打完这局游戏就来
- 舍友:等我修好这个 bug 就吃饭
- 导师:等我出差回来就讨论这个课题
- jyy:
等我成为卷王就躺平- “先到先等”
-
目标:写线程模拟上面的过程,比如A线程代表你打游戏,B线程代表你舍友修bug,这两个线程要做的是在你打完游戏,舍友修完bug之后一起去干饭
生产者-消费者问题:学废你就赢了
99% 的实际并发问题都可以用生产者-消费者解决。
|
|
在 printf 前后增加代码,使得打印的括号序列满足
- 一定是某个合法括号序列的前缀
- 括号嵌套的深度不超过$n$
- $n=3$,
((())())(((合法 - $n=3$,
(((()))),(()))不合法
- $n=3$,
- 同步
- 等到有空位(嵌套层数不多)再打印左括号
- 等到能配对时再打印右括号
生产者-消费者问题:分析
-
为什么叫 “生产者-消费者” 而不是 “括号问题”?
-
左括号:生产资源 (任务)、放入队列
-
右括号:从队列取出资源 (任务) 执行
-
-
能否用互斥锁实现括号问题?
- 左括号:嵌套深度 (队列) 不足$n$时才能打印
- 右括号:嵌套深度 (队列) > 1时才能打印
-
当然是等到满足条件时再打印了:pc.c
- 用互斥锁保持条件成立
|
|
- 压力测试的检查当然不能少:pc-check.py $\Longrightarrow$ 学一门脚本语言来做自动化检测(很重要!),总比$OJ$给你报错你不知道错在哪里好很多
- 少面向OJ编程(真正的project没有这玩意儿)
|
|
-
Model checker 当然也不能少 (留作习题)
-
管道通信+自动化脚本检测
|
|
补充:利用Rust的自旋锁实现上述问题
lib.rs
|
|
main.rs
|
|
- 压力测试
|
|
- 互斥锁太难了(
Rust写着就很难),有时间再看吧😭
条件变量:万能同步方法
同步问题:分析
任何同步问题都有先来先等待的条件
-
- 等所有线程结束后继续执行,否则等待
-
NPY 的例子
- 打完游戏且洗完头后继续执行
date(),否则等待
- 打完游戏且洗完头后继续执行
-
生产者/消费者问题
- 左括号:深度$k < n$时
printf,否则等待 - 右括号:$k > 0$时
printf,否则等待- 再看一眼 pc.c $\Longrightarrow$ thread每次停下来都要执行“上🔒 $\rightarrow$ 让我看看!(资源,好康的东西) $\rightarrow$ 执行或解🔒”(代码:
retry:mutex_lock(&lk);if (count == 0) {mutex_unlock(&lk);goto retry;})浪费了时间,能不能优化掉“上🔒 $\rightarrow$ 让我看看!$\rightarrow$ 执行或解🔒”的时间?
- 再看一眼 pc.c $\Longrightarrow$ thread每次停下来都要执行“上🔒 $\rightarrow$ 让我看看!(资源,好康的东西) $\rightarrow$ 执行或解🔒”(代码:
- 左括号:深度$k < n$时


-
目前理解:
join() = while(!terminated_all); -
我们想要做的:将“上🔒 $\rightarrow$ 让我看看!$\rightarrow$ 执行或解🔒”变成“看完了,资源不对,那就睡觉(悲”(代码:
mutex_lock(&lk);if (count == 0){mutex_unlock_and_sleep(&lk);}),也就是“半自旋”$\Longrightarrow$ 休眠- 同时,另一个thread在执行完该做的任务后要叫醒休眠的线程
|
|
Conditional Variables (条件变量, CV)
-
条件变量 API
- wait(cv, mutex) 💤
- 调用时必须保证已经获得 mutex
- 释放 mutex、进入睡眠状态
- wait(cv, mutex) 💤
-
signal/notify(cv) 💬 私信:走起
- 如果有线程正在等待 cv,则唤醒其中一个线程
-
broadcast/notifyAll(cv) 📣 所有人:走起
- 唤醒全部正在等待 cv 的线程(呃呃呃,原来去年cyd的Java教的就是这玩意啊,🐮魔差点写死✌)
条件变量:实现生产者-消费者
- 改良代码
|
|
- (Small scope hypothesis)



|
|
- 观察
|
|
-
i < 1的时候没问题,而i < 8的时候就出了问题
|
|
- 过程解读(上面的pc-cv.c)
-
从生成者开始往下走,一个生成材料生成成功,而消费过程执行了两次 $\Longrightarrow$ 寄了!
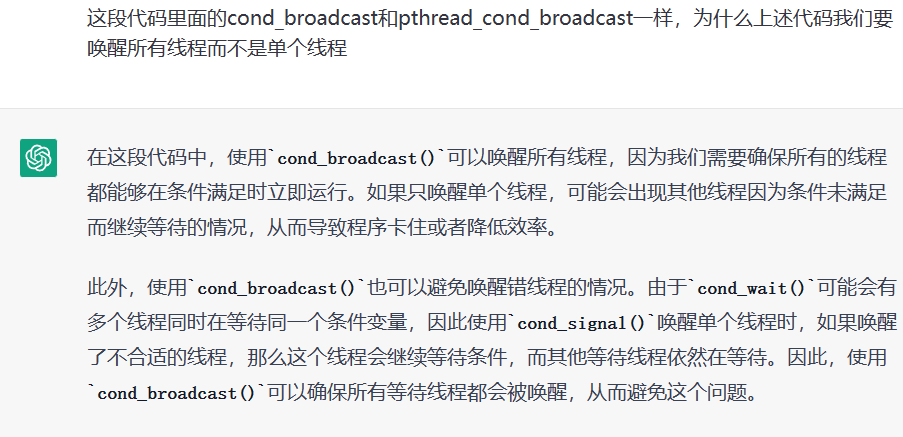
- 为什么呢:同类唤醒了同类,这是错误的
- 需要两个条件变量,保证只能唤醒异类,课后自己阅读相关材料
条件变量:正确的打开方式
- 需要等待条件满足时
|
|
- 其他线程条件可能被满足时
|
|

|
|
- 运行成功!
- 问大爹ChatGPT
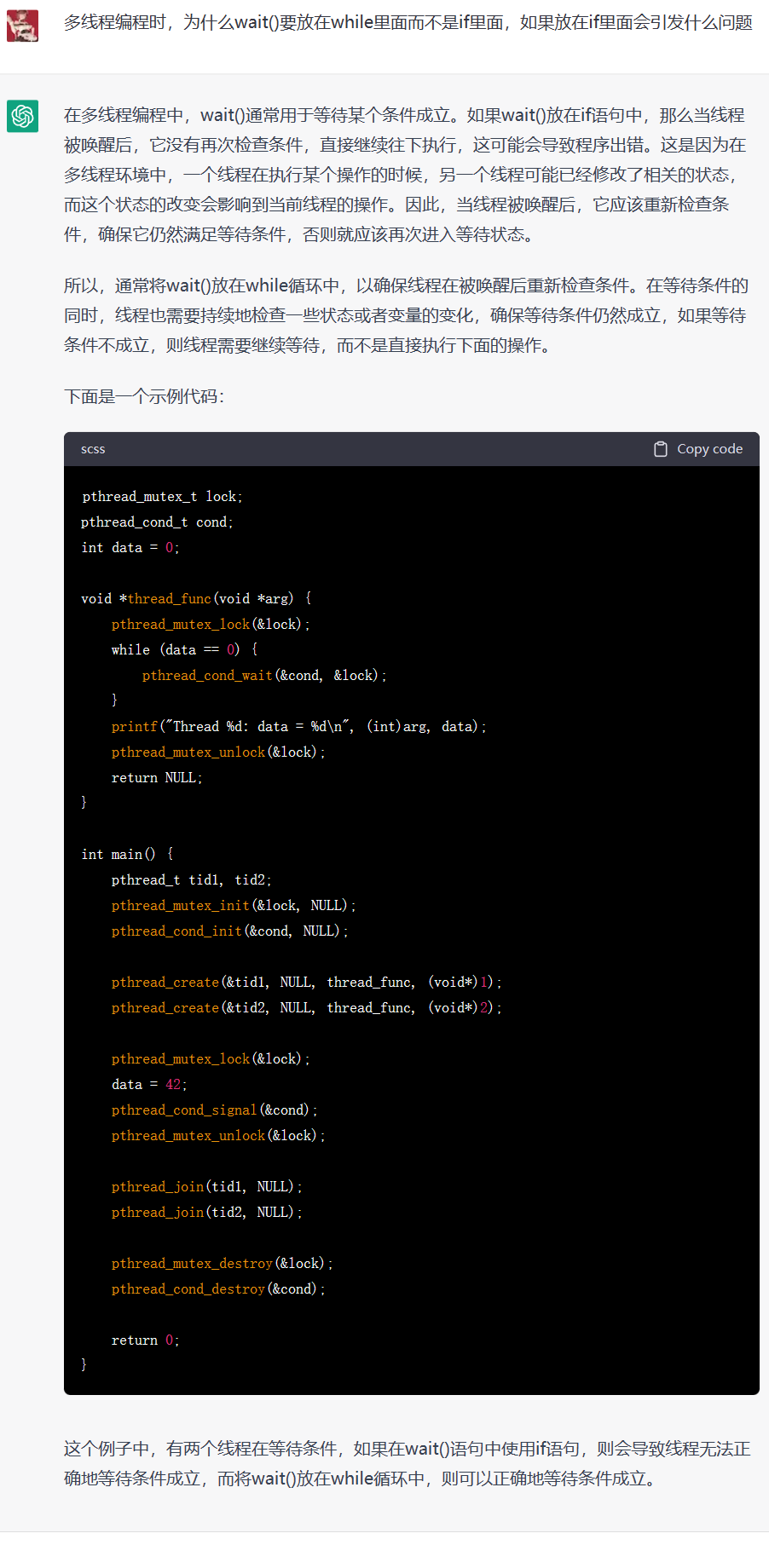
if是假睡眠,只能睡一次,下一次就会苏醒,而while才是真睡眠,只有条件满足时才苏醒
|
|
条件变量:实现并行计算
|
|
- 下面开始将最长公共子串的dp算法,视频断了,这个之前博客里面有《Dynamic Programming》回去复习
- 视频中断,但是大致听出来优化的方法,因为上面的最长公共子串的计算是有一定顺序的,我们需要先算$depth$比较浅的,然后再算$depth$比较浅的 $\Longrightarrow$ 是不是和上面的生成者,消费者问题有着相似的地方?我们可以将这个想法分配给不同的线程,利用sleep和notify来保持相对的一个顺序来对我们之前的算法做优化!(注意利用上面的job库)
- 研究这道题$H_20$生成
Pause in 2023-03-11 21:30
感觉这节课内容好™️的多,已经不是仅仅就限制于一个一个算法了
去年cyd的Java上面讲的Thread那些东西终于开始理解了,而不是像当时那样在宿舍瞎🐔8️⃣写Thread
感谢Dereck Chen推荐的两篇有关xv6锁的文章《Chapter 6: Locking》和《Chapter 6.5: More Tools, Examples and Deadlocks》,一定找时间好好看
感谢洲帮我找到了用台湾线上ChatGPT的方法
Update in 2023-03-12 11:30
👀✋今天薄纱你这章
条件变量:更古怪的习题/面试题
有三种线程,分别打印 <, >, 和 _
- 对这些线程进行同步,使得打印出的序列总是
<><_和><>_组合
使用条件变量,只要回答三个问题:
- 打印 “
<” 的条件? - 打印 “
>” 的条件? - 打印 “
_” 的条件?
|
|
信号量
复习:互斥锁和更衣室管理
操作系统 = 更衣室管理员
- 先到的人 (线程)
- 成功获得手环,进入游泳馆
*lk = 🔒,系统调用直接返回
- 后到的人 (线程)
- 不能进入游泳馆,排队等待
- 线程放入等待队列,执行线程切换 (yield)
- 洗完澡出来的人 (线程)
- 交还手环给管理员;管理员把手环再交给排队的人
- 如果等待队列不空,从等待队列中取出一个线程允许执行
- 如果等待队列为空,
*lk = ✅
- 管理员 (OS) 使用自旋锁确保自己处理手环的过程是原子的
更衣室管理
完全没有必要限制手环的数量——让更多同学可以进入更衣室
- 管理员可以持有任意数量的手环 (更衣室容量上限)
- 先进入更衣室的同学先得到
- 手环用完后才需要等同学出来
更衣室管理 (by E.W. Dijkstra)
做一点扩展——线程可以任意 “变出” 一个手环
- 把手环看成是令牌
- 得到令牌的可以进入执行
- 可以随时创建令牌

“手环” = “令牌” = “一个资源” = “信号量” (semaphore)
- P(&sem) - prolaag = try + decrease; wait; down; in
- 等待一个手环后返回
- 如果此时管理员手上有空闲的手环,立即返回
- V(&sem) - verhoog = increase; post; up; out
- 变出一个手环,送给管理员
- 信号量的行为建模: sem.py
|
|
信号量:实现生产者-消费者
信号量设计的重点
- 考虑 “手环” (每一单位的 “资源”) 是什么,谁创造?谁获取?
|
|
- 在 “一单位资源” 明确的问题上更好用
- ”凭空创造🔑“而不是像之前那样使用”配对的手环“,程序的正确性更加危险。。。

csappChatGPT生成的一些代码
生产者-消费者问题是一个经典的并发问题,描述了一个生产者和一个消费者在共享资源的环境中的互动。生产者生成一些产品并将它们放入一个共享缓冲区,消费者从共享缓冲区中取出产品并将其消费。为了确保生产者和消费者之间的正确互动,需要使用信号量来实现同步和互斥。
C++实现
|
|

例子1
例子2哲♂️学家吃饭问题(E. W. Dijkstra, 1960)
哲学家 (线程) 有时思考,有时吃饭
- 吃饭需要同时得到左手和右手的叉子
- 当叉子被其他人占有时,必须等待,如何完成同步?

失败与成功的尝试
失败的尝试
- philosopher.c (如何解决?)
- 这里面使用了信号量
|
|
- 上面的程序会卡死(都拿左叉子的时候执行拿右叉子的动作的时候会一直
wait直到有人notify它,可是这个场景下没人notify它 $\Longrightarrow$ 程序死锁)
这段代码实现了经典的哲学家就餐问题(Dining Philosophers Problem)。在这个问题中,有 $N$ 个哲学家和 $N$ 个叉子,每个哲学家需要同时拿到两个相邻的叉子才能吃饭,但是叉子一次只能被一个哲学家拿走,因此当所有哲学家都拿起一个叉子时,就会出现死锁。这段代码使用信号量来避免死锁,具体来说,每个叉子对应一个信号量,哲学家先尝试获取左边的叉子,如果获取不到则等待,否则再尝试获取右边的叉子。获取到两个叉子后,哲学家吃完后将两个叉子都放回原处,再次尝试获取叉子。由于每个哲学家只允许同时持有一个叉子,因此不会出现死锁。
在代码中,首先使用
SEM_INIT函数将所有锁初始化为1,表示所有叉子都没有被占用。然后使用create函数创建 $N$ 个哲学家线程,每个线程执行Tphilosopher函数,即尝试获取叉子。在Tphilosopher函数中,首先获取左边的叉子,然后获取右边的叉子,如果两个叉子都获取到了,就吃饭,并将两个叉子都放回原处,再次循环。在获取和放回叉子时,使用P和V函数操作信号量,其中P表示获取锁,如果锁已经被占用,则阻塞等待,直到锁被释放;V表示释放锁,将锁的值加1,唤醒一个等待锁的线程。
上面的代码存在死锁的问题,原因是当所有的哲学家同时拿起自己左边的叉子后,会发生死锁。
具体来说,假设当前所有的哲学家都拿起了自己左边的叉子,那么每个哲学家都在等待自己的右边的叉子被释放,以便拿起右边的叉子。但是右边的叉子已经被邻座的哲学家拿走了,他们也在等待他们左边的叉子被释放。这种情况下,所有哲学家都无法继续执行,进入了死锁状态。
为了避免死锁,可以使用以下方法之一:
- 将某个哲学家的左右叉子同时拿起来,这样他就可以开始进餐了,避免了所有哲学家都拿起自己左边的叉子导致的死锁。
- 改变某些哲学家的拿叉子顺序,例如先拿右边的叉子再拿左边的叉子,避免了所有哲学家都拿起自己左边的叉子导致的死锁。
来自带爹ChatGPT
- 成功的尝试 (万能的方法)
- OS哲学:通用 $>$ 小聪明(⬛✋:别装🅱️!)
|
|
- 与上面那个失败的例子相比,这个程序里面的哲♂️学家一看看左右两边的叉子,拿取和归还也是按双,不会再像前面那样一个一个拿,最后造成死锁的情况。
忘了信号量,让一个人集中管理叉子吧!
“Leader/follower” - 生产者/消费者
- 分布式系统中非常常见的解决思路 (HDFS, …)
|
|
和上面的例子很像,用一个服务员做总管理- 这个是一个集中式算法,要比分布式算法更容易整对,
Twaiter是一个调度器
忘了那些复杂的同步算法吧!
-
你可能会觉得,管叉子的人是性能瓶颈
-
一大桌人吃饭,每个人都叫服务员的感觉
-
$Premature\ optimization\ is\ the\ root\ of\ all\ evil\ (D. E. Knuth)\newline$
-
与数据结构不同,OS更多考虑现实情况
-
-
抛开 workload 谈优化就是耍流氓
-
吃饭的时间通常远远大于请求服务员的时间
-
如果一个 manager 搞不定,可以分多个 (fast/slow path)(多个服务员+总服务员,每个服务员都有一把叉子)
- 把系统设计好,使集中管理不成为瓶颈
- Millions of tiny databases (NSDI'20)
- 把系统设计好,使集中管理不成为瓶颈
-
总结
本次课回答的问题
- Q: 如何在多处理器上协同多个线程完成任务?
Take-away message
- 实现同步的方法
- 条件变量、信号量;生产者-消费者问题
- Job queue 可以实现几乎任何并行算法
- 不要 “自作聪明” 设计算法,小心求证
in 2023-03-12 15:30
这章好™️的难,感觉是本门课听到目前为止除了第三章以外最吃力的一节课之一了,可能也和前置知识缺失有关(毕竟不是南大✋)
-
而且发现有很多东西要看了
-
《CSAPP》第12章
-
《UNIX环境高级编程》第15章(之前z217学长就推荐了这本书)
-
C++多线程部分的标准库,不然力扣的题做不了,而且后面这个还要用
-
有时间赶紧看(bushi
补充:进程调度$(Scheduling)$
参考清华大学$rCore$课程资料——进程调度——补充于2023-4-15
导读
-
计算机内存中可执行的程序个数大于处理器个数时,这些程序可通过共享处理器来完成各自的任务。而操作系统负责让它们能够高效合理地共享处理器资源,这就引入了调度(
scheduling)这个概念。进程调度(也称处理器调度)是进程管理的重要组成部分。 -
调度的一般定义
- 在一定的约束条件下,把有限的资源在时间上分配给若干个任务,以满足或优化一个或多个性能指标。
- 对于计算机系统而言,就是在一台计算机中运行了多个进程,操作系统把有限的处理器在时间上分配给各个进程,以满足或优化进程执行的性能指标。
-
核心问题:操作系统如何通过进程调度来提高进程和系统的性能
-
细化为子问题
- 运行进程的约束条件是啥?
- 有哪些调度策略和算法?
- 调度的性能指标是啥?
- 如何评价调度策略和算法?
批处理系统的调度
- 在批处理系统下,应用以科学计算为主,I/O操作较少,且I/O操作主要集中在应用开始和结束的一小段时间,应用的执行时间主要消耗在占用处理器进行计算上,且应用的大致执行时间一般可以预估到。
约束条件
- 批处理系统中的进程有如下一些约束/前提条件:
- 每个进程同时到达。
- 每个进程的执行时间相同。(为了贴合实际也可以改变一些约束条件,比如将条件2改为:
每个进程的执行时间不同) - 进程的执行时间是已知的。
- 进程在整个执行过程期间很少执行I/O操作。(可理解为在操作系统调度过程中,可以忽略进程执行I/O操作的开销)
- 进程在执行过程中不会被抢占。
性能指标
-
我们还需给出性能指标,用于衡量,比较和评价不同的调度策略。对于批处理系统中的一般应用而言,可以只有一个性能指标:周转时间(
turn around time),即进程完成时间与进程到达时间的差值:$T_{周转时间}=T_{完成时间}-T_{到达时间}$ -
由于前提条件1 明确指出所有进程在同一时间到达, 所以$T_{到达时间}=0$,因此$T_{周转时间}=T_{完成时间}-T_{到达时间}=T_{完成时间}$。除了总的周转时间,我们还需要关注平均周转时间这样的统计值:
$$ T_{平均周转时间}=\frac{\sum_{i=1}^{就绪进程个数} T_{周转时间_i}}{就绪进程个数} $$
- 对于单个进程而言,平均周转时间是一个更值得关注的性能指标
先来先服务
-
先来先服务(
first-come first-severd,也称First-in first-out,先进先出)调度策略的基本思路就是按进程请求处理器的先后顺序来使用处理器。在具体实现上,操作系统首先会建立一个就绪调度队列(简称就绪队列)和一个等待队列(也称阻塞队列)。 -
大致的调度过程如下
- 操作系统每次执行调度时,都是从就绪队列的队头取出一个进程来执行
- 当一个应用被加载到内存,并创建对应的进程,设置进程为就绪进程,按进程到达的先后顺序,把进程放入就绪调度队列的队尾
- 当正在运行的进程主动放弃处理器时,操作系统会把该进程放到就绪队列末尾,并从就绪队列头取出一个进程执行
- 当正在运行的进程执行完毕时,操作系统会回收该进程所在资源,并从就绪队列头取出一个进程执行
- 当正在运行的进程需要等待某个事件或资源时,操作系统会把该进程从就绪队列中移出,放到等待队列中(此时这个进程从就绪进程变成等待进程),并从就绪队列头取出下一个进程执行
- 当等待进程所等待的某个事件出现或等待的资源得到满足时,操作系统会把该进程转为就绪进程,并会把该进程从等待队列中移出,并放到就绪队列末尾
-
该调度策略的优点是简单,容易实现。对于满足1~5约束条件的执行环境,用这个调度策略的平均周转时间性能指标也很好。如果在一个在较长的时间段内,每个进程都能结束,那么公平性这个指标也是能得到保证的
-
操作系统不会主动打断进程的运行
最短作业优先
-
满足1~5的约束条件的执行环境太简化和理想化了,在实际系统中,每个应用的执行时间很可能不同,所以约束条件2“每个进程的执行时间相同”就不合适了。如果把约束条件2改为 “每个进程的执行时间不同”,那么在采用先来先服务调度策略的系统中,可能就会出现短进程不得不等长进程结束后才能运行的现象,导致短进程的等待时间太长,且系统的平均周转时间也变长了
-
假设有两个进程$P_A、P_B$,它们大致同时到达,但$P_A$稍微快一点,进程$P_A$执行时间为100,进程$P_B$的执行时间为20。如果操作系统采用先来先服务的调度策略,进程的平均周转时间为:$\frac{P_A周转时间+P_B周转时间}{2}=\frac {100+120}{2} = 110$
-
但如果操作系统先调度进程$P_B$,那么进程的平均周转时间为:$\frac{P_B周转时间+P_A周转时间}{2}=\frac {20+120}{2} = 70$
-
可以看到,如果采用先来先服务调度策略,执行时间短的进程(简称短进程)可被排在执行时间长的进程(长进程)后面,导致进程的平均周转时间变长(长进程首先执行导致了后面的进程等待时间过长)
-
为应对短进程不得不等长进程结束后才能运行的问题,我们可以想到一个调度的方法:优先让短进程执行。这就是最短作业优先(
Shortest Job First,简称SJF)调度策略。其实上面让PB先执行的调度方法,就是采用了最短作业优先策略。 -
在更新约束条件2的前提下,如果我们把平均周转时间作为唯一的性能指标,那么SJF是一个最优调度算法
-
虽然SJF调度策略在理论上表现很不错,但在具体实现中,需要对处于就绪队列上的进程按执行时间进行排序,这会引入一定的调度执行开销。而且如果进一步放宽约束,贴近实际情况,SJF就会显现出它的
不足。如果我们放宽约束条件1:
- 每个进程可以在不同时间到达
那么可能会发生一种情况,当前正在运行的进程还需 $k$ 执行时间才能完成,这时来了一个执行时间为 $h$ 的进程,且 $h < K$ ,但根据
约束条件5,操作系统不能强制切换正在运行的进程。所以,在这种情况下,最短作业优先的含义就不是那么确切了,而且在理论上,SJF也就不是最优调度算法了
- 例如,操作系统采用SJF调度策略(不支持抢占进程),有两个进程,$P_A$在时间0到达,执行时间为100, $P_B$在时间20到达,执行时间为20,那么周转时间为
$$ (P_A执行结束-P_A开始执行)+(P_B执行结束-P_B开始执行)=(100-0)+(120-20)=200 $$
平均周转时间:$\frac{200}{2}=100$
交互式系统的调度
- 交互式系统是指支持人机交互和各种$I/O$交互的计算机系统。可抢占任务执行的分时多任务操作系统对人机交互性和$I/O$及时响应更加友好,对进程特征的约束条件进一步放宽,进程的可抢占特性需要我们重新思考如何调度
约束条件
- 交互式系统中的进程有如下一些约束/前提条件:
- 每个进程可不同时间到达
- 每个进程的执行时间不同
- 进程的执行时间是已知的
- 进程在整个执行过程期间会执行$I/O$操作
- 进程在执行过程中会被抢占
- 相对于批处理操作系统,约束条件4发生了变化,这意味着在进程执行过程中,操作系统不能忽视其I/O操作。约束条件5也发生了改变,即进程可以被操作系统随时打断和抢占
性能指标
- 操作系统支持任务/进程被抢占的一个重要目标是提高用户的交互性体验和减少$I/O$响应时间。用户希望计算机系统能及时响应他发出的$I/O$请求(如键盘、鼠标等),但平均周转时间这个性能指标不足以反映人机交互或$I/O$响应的性能。所以,我们需要定义新的性能指标 – 响应时间(
response time):
$$ T_{响应时间}=T_{首次执行}-T_{到达时间} $$
- 而对应的平均响应时间是:
$$ T_{平均响应时间}=\frac{T_{响应时间}}{就绪进程个数} $$
例如,操作系统采用
SJF调度策略(不支持抢占进程),有两个进程,$P_A$在时间0到达,执行时间为100, $P_B$在时间20到达,执行时间为20,那么$P_A$的响应时间为0,$P_B$为80,平均响应时间为 40 。
最短完成时间优先(STCF)
-
由于约束条件5表示了操作系统允许抢占,那么我们就可以实现一种支持进程抢占的改进型
SJF调度策略,即最短完成时间优先(Shortest Time to Complet First)调度策略。 -
基于前述的例子,操作系统采用STCF调度策略,有两个进程,PA在时间0到达,执行时间为100, PB在时间20到达,执行时间为20,那么周转时间为(注意这里面PB可以抢占PA了,所以PA的完成时间变成了$100+20=120$):
$$ \begin{align} &(120 - 0) + (40 - 20) = 140\newline &T_{平均周转时间}=\frac{140}{2}=70\newline \end{align} $$
-
平均周转时间为 70 。可以看到,如果采用
STCF调度策略,相比于SJF调度策略,在周转时间这个性能指标上得到了改善 -
但对于响应时间而言,可能就不这么好了。考虑一个例子,有两个用户发出了执行两个进程的请求,且两个进程大约同时到达,PA和PB的执行时间都为20。我们发现,无论操作系统采用FIFO/SJF/STCF中的哪一种调度策略,某一个用户不得不等待20个时间单位后,才能让他的进程开始执行,这是一个非常不好的交互体验。从性能指标上看,响应时间比较差。 这就引入了新的问题:操作系统如何支持看重响应时间这一指标的应用程序?
基于时间片的轮转
-
如果操作系统分给每个运行的进程的运行时间是一个足够小的时间片(
time slice,quantum),时间片一到,就抢占当前进程并切换到另外一个进程执行。 -
这样进程以时间片为单位轮流占用处理器执行。对于交互式进程而言,就有比较大的机会在较短的时间内执行,从而有助于减少响应时间。
-
这种调度策略称为轮转(
Round-Robin,简称RR)调度,即基本思路就是从就绪队列头取出一个进程,让它运行一个时间片,然后把它放回到队列尾,再从队列头取下一个进程执行,周而复始
- 在具体实现上,需要考虑时间片的大小,一般时间片的大小会设置为时钟中断的时间间隔的整数倍。比如,时钟中断间隔为1ms,时间片可设置为10ms,两个用户发出了执行两个进程的请求,且两个进程大约同时到达,PA和PB的执行时间都为20s(即20,000ms)。如果采用轮转调度,那么进程的响应时间为
0+10 = 10ms
- 平均响应时间为:
$\frac{0+10}{2} = 5ms$
- 这两个值都远小于采用之前介绍的三种调度策略的结果
- 直观上可以进一步发现,如果我们进一步减少时间片的大小,那么采用轮转调度策略会得到更好的响应时间。但其实这是有潜在问题的,因为每次进程切换是有切换代价的,参考之前介绍的进程切换的实现,可以看到,进程切换涉及多个寄存器的保存和回复操作,页表的切换操作等。
如果进程切换的时间开销是0.5ms,时间片设置为1ms,那么会有大约50%的时间用于进程切换,这样进程实际的整体执行时间就大大减少了
-
所以,我们需要通过在响应时间和进程切换开销之间进行权衡。不能把时间片设置得太小,且让响应时间在用户可以接受的范围内
-
看来轮转调度对于响应时间这个指标很友好。但如果用户也要考虑周转时间这个指标,那轮转调度就变得不行了
还是上面的例子,我们可以看到,PA和PB两个进程几乎都在40s左右才结束,这意味着平均周转时间为:
$\frac{40+40}{2}=40s$
- 这大于基于
SJF的平均周转时间:
$\frac{(20 - 0) + (40 - 0)}{2} = 30s$
-
如果活跃进程的数量增加,我们会发现轮转调度的平均周转时间会进一步加强。也许有同学会说,那我们可以通过调整时间片,把时间片拉长,这样就会减少平均周转时间了。但这样又会把响应时间也给增大了。而且如果把时间片无限拉长,轮转调度就变成了
FCFS调度了。 -
到目前为止,我们看到以
SJF为代表的调度策略对周转时间这个性能指标很友好,而以轮转调度为代表的调度策略对响应时间这个性能指标很友好。但鱼和熊掌难以兼得。
通用计算机系统的调度
个人计算机和互联网的发展推动了计算机的广泛使用,并出现了新的特点,内存越来越大,各种I/O设备成为计算机系统的基本配置,一般用户经常和随时使用交互式应用(如字处理、上网等),驻留在内存中的应用越来越多,应用的启动时间和执行时间无法提前知道。而且很多情况下,处理器大部分时间处于空闲状态,在等待用户或其它各种外设的输入输出操作。
约束条件
- 这样,我们的约束条件也随之发生了新的变化:
- 每个进程可不同时间到达
- 每个进程的执行时间不同
- 进程的启动时间和执行时间是未知的
- 进程在整个执行过程期间会执行I/O操作
- 进程在执行过程中会被抢占
- 可以看到,其中的第3点改变了,导致进程的特点也发生了变化。有些进程为I/O密集型的进程,大多数时间用于等待外设I/O操作的完成,需要进程能及时响应。有些进程是CPU密集型的,大部分时间占用处理器进行各种计算,不需要及时响应。还有一类混合型特点的进程,它在不同的执行阶段有I/O密集型或CPU密集型的特点。这使得我们的调度策略需要能够根据进程的动态运行状态进行调整,以应对各种复杂的情况。
性能指标
-
如果把各个进程运行时间的公平性考虑也作为性能指标,那么我们就需要定义何为公平。我们先给出一个公平的描述性定义:在一个时间段内,操作系统对每个处于就绪状态的进程均匀分配占用处理器的时间
-
这里需要注意,为了提高一个性能指标,可能会以牺牲其他性能指标作为代价。所以,调度策略需要综合考虑和权衡各个性能指标。在其中找到一个折衷或者平衡
多级反馈队列调度
-
在无法提前知道进程执行时间的前提下,如何设计一个能同时减少响应时间和周转时间的调度策略是一个挑战
-
不过计算机科学家早就对此进行深入分析并提出了了解决方案
-
在1962年,
MIT的计算机系教授$Fernando\ Jose\ Corbato$(1990年图灵奖获得者)首次提出多级反馈队列($Multi-level\ Feedback\ Queue$,简称MLFQ)调度策略,并用于当时的CTSS(兼容时分共享系统)操作系统中 -
Corbato教授的思路很巧妙,用四个字来总结,就是以史为鉴- 根据进程过去一段的执行特征来预测其未来一段时间的执行情况,并以此假设为依据来动态设置进程的优先级,调度子系统选择优先级最高的进程执行。这里可以看出,进程有了优先级的属性,而且进程的优先级是可以根据过去行为的反馈来动态调整的,不同优先级的进程位于不同的就绪队列中
固定优先级的多级无反馈队列
-
MLFQ调度策略的关键在于如何设置优先级。一旦设置进程的好优先级,MLFQ总是优先执行唯有高优先级就绪队列中的进程。对于挂在同一优先级就绪队列中的进程,采用轮转调度策略 -
先考虑简单情况下,如果我们提前知道某些进程是
I/O密集型的,某些进程是CPU密集型的,那么我们可以给I/O密集型设置高优先级,而CPU密集型进程设置低优先级。这样就绪队列就变成了两个,一个包含I/O密集型进程的高优先级队列,一个是处理器密集型的低优先级队列 -
那我们如何调度呢?MLFQ调度策略是先查看高优先级队列中是否有就绪进程,如果有,就执行它,然后基于时间片进行轮转。由于位于此高优先级队列中的进程都是I/O密集型进程,所以它们很快就会处于阻塞状态(进入阻塞队列),等待I/O设备的操作完成,这就会导致高优先级队列中没有就绪进程
-
在高优先级队列没有就绪进程的情况下,
MLFQ调度策略就会从低优先级队列中选择CPU密集型就绪进程,同样按照时间片轮转的方式进行调度-
如果在
CPU密集型进程执行过程中,某个I/O密集型进程所等待的I/O设备的操作完成了,那么操作系统会打断CPU密集型进程的执行,以及时响应该中断,并让此I/O密集型进程从阻塞状态变成就绪态,重新接入到高优先级队列的尾部 -
这时调度子系统会优先选择高优先级队列中的进程执行,从而抢占了
CPU密集型进程的执行
-
-
这样,我们就得到了
MLFQ的基本设计规则
- 如果进程
PA的优先级 >PB的优先级,抢占并运行PA - 如果进程
PA的优先级 =PB的优先级,轮转运行PA和PB
- 但还是有些假设过于简单化了,比如:
- 通常情况下,操作系统并不能提前知道进程是
I/O密集型还是CPU密集型的 I/O密集型进程的密集程度不一定一样,所以把它们放在一个高优先级队列中体现不出差异- 进程在不同的执行阶段会有不同的特征,可能前一阶段是
I/O密集型,后一阶段又变成了CPU密集型
- 而在进程执行过程中固定进程的优先级,将难以应对上述情况
可降低优先级的多级反馈队列
-
改进的MLFQ调度策略需要感知进程的过去执行特征,并根据这种特征来预测进程的未来特征
- 如果进程在过去一段时间是
I/O密集型特征,就调高进程的优先级 - 如果进程在过去一段时间是
CPU密集型特征,就降低进程的优先级
- 如果进程在过去一段时间是
-
由于会动态调整进程的优先级,所以,操作系统首先需要以优先级的数量来建立多个队列
- 这个数量是一个经验值,比如
Linux操作系统设置了140个优先级
- 这个数量是一个经验值,比如
-
如何动态调整进程的优先级?
-
首先,我们假设新创建的进程是
I/O密集型的,可以把它设置为最高优先级 -
接下来根据它的执行表现来调整其优先级。如果在分配给它的时间配额内,它睡眠或等待
I/O事件完成而主动放弃了处理器,操作系统预测它接下来的时间配额阶段很大可能还是具有I/O密集型特征,所以就保持其优先级不变 -
如果进程用完了分配给它的时间配额,操作系统预测它接下来有很大可能还是具有
CPU密集型特征,就会降低其优先级- 这里的时间配额的具体值是一个经验值,一般是时间片的整数倍
-
-
如果一个进程的执行时间小于分配给它的一个或几个时间配额,我们把这样的进程称为短进程。那么这个短进程会以比较高的优先级迅速地结束
-
而如果一个进程有大量的
I/O操作,那么一般情况下,它会在时间配额结束前主动放弃处理器,进入等待状态,一旦被唤醒,会以原有的高优先级继续执行 -
如果一个进程的执行时间远大于几个时间配额,我们把这样的进程称为长进程。那么这个常进程经过一段时间后,会处于优先级最底部的队列,只有在没有高优先级进程就绪的情况下,它才会继续执行,从而不会影响交互式进程的响应时间
- 这样,我们进一步扩展了
MLFQ的基本规则
-
创建进程并让进程首次进入就绪队列时,设置进程的优先级为最高优先级
-
进程用完其时间配额后,就会降低其优先级
- 虽然这样的调度看起来对短进程、
I/O密集型进程或长进程的支持都还不错。但这样的调度只有降低优先级的操作,对于某些情况还是会应对不足
-
一个进程先执行了一段比较长时间的
CPU密集型任务,导致它到了底部优先级队列,然后它在下一阶段执行I/O密集型任务,但被其他高优先级任务阻挡了,难以减少响应时间 -
在计算机系统中有大量的交互型进程,虽然每个进程执行时间短,但它们还是会持续地占用处理器,追导致位于低优先级的长进程一直无法执行,出现饥饿(
starvation)现象
- 这主要是调度策略还缺少提升优先级的灵活规则
可提升/降低优先级的多级反馈队列
-
对于可降低优先级的多级反馈队列调度策略难以解决的上述情况1和2,我们需要考虑如何提升某些进程的优先级
-
一个可以简单实现的优化思路是,每过一段时间,周期性地把所有进程的优先级都设置为最高优先级
-
这样长进程不会饿死
-
而被降到最低优先级的进程,如果当前处于I/O密集型任务,至少在一段时间后,会重新减少其响应时间
-
-
不过这个“一段时间”的具体值如何设置?看起来又是一个经验值。这样,我们又扩展了
MLFQ的基本规则
- 经过一段时间,把所有就绪进程重新加入最高优先级队列
-
但这样就彻底解决问题了吗?其实还不够,比如对于优先级低且处于I/O密集型任务的进程,必须等待一段时间后,才能重新加入到最高优先级,才能减少响应时间。难道这样的进程不能不用等待一段时间吗?
-
而对于长进程,如果有不少长进程位于最低优先级,一下子把它们都提升为最高优先级,就可能影响本来处于最高优先级的交互式进程的响应时间。看来,第5条规则还有进一步改进的空间,提升优先级的方法可以更灵活一些
-
先看长进程,可以发现,所谓长进程“饥饿”,是指它有很长时间没有得到执行了
-
如果我们能够统计其在就绪态没有被执行的等待时间长度,就可以基于这个动态变量来逐步提升其优先级
- 比如每过一段时间,查看就绪进程的等待时间(进程在就绪态的等待时间)长度,让其等待时间长度与其优先级成反比,从而能够逐步第动态提升长进程的优先级
-
再看优先级低且处于
I/O密集型任务的进程,可以发现,它也有很长时间没有得到执行的特点,这可以通过上面的逐步提升优先级的方法获得执行的机会,并在执行I/O操作并处于等待状态,但此时的优先级还不够高 -
但操作系统在
I/O操作完成的中断处理过程中,统计其I/O等待时间(进程在阻塞态下的等待时间),该进程的I/O等待时间越长,那么其优先级的提升度就越高,这可以使其尽快到达最高优先级
- 这样根据就绪等待时间和阻塞等待时间来提升进程的优先级,可以比较好第应对上面的问题。我们可以改进第5条规则:
- 定期统计进程在就绪态/阻塞态的等待时间,等待时间越长,其优先级的提升度就越高
- 对于就绪态等待时间对应的优先级提升度一般时小于阻塞态等待时间对应的优先级提升度,从而让调度策略优先调度当前具有I/O密集型任务的进程
经过我们总结出来的
MLFQ调度规则,使得操作系统不需要对进程的运行方式有先验知识,而是通过观测和统计进程的运行特征来给出对应的优先级,使得操作系统能灵活支持各种运行特征的应用在计算机系统中高效执行
公平份额调度
在大公司的数据中心中有着大量的计算机服务器,给互联网上的人们提供各种各样的服务。在这样的服务器中,有着相对个人计算机而言更加巨大的内存和强大的计算处理能力,给不同用户提供服务的各种进程的数量也越来越多。这个时候,面向用户或进程相对的公平性就是不得不考虑的一个问题,甚至时要优先考虑的性能指标。比如,在提供云主机的数据中心中,用户可能会希望分配20%的处理器时间给
Windows虚拟机,80%的处理器时间给Linux系统,如果采用公平份额调度的方式可以更简单高效
- 从某种程度上看,
MLFQ调度策略总提到的优先级就是对公平性的一种划分方式,有些进程优先级高,会更快地得到处理器执行,所分配到的处理器时间也多一些。但MLFQ并不是把公平性放在第一位
-
我们就可以设计出另外一类调度策略 – 公平份额($Fair\ Share$,又称为 比例份额,$Proportional\ Share$)调度。其基本思路是基于每个进程的重要性(即优先级)的比例关系,分配给该进程同比例的处理器执行时间
-
在1993~1994年,
MIT的计算机系博士生$Carl\ A.\ Waldspurger$ 和他的导师$ William\ E.\ Weihl$提出了与众不同的调度策略:彩票调度($Lottery\ Scheduling$)和步长调度($Stride\ Scheduling$)。它们都属于公平份额调度策略。彩票调度很有意思,它是从经济学的的彩票行为中吸取营养,模拟了购买彩票和中奖的随机性,给每个进程发彩票,进程优先级越高,所得到的彩票就越多;然后每隔一段时间(如,一个时间片),举行一次彩票抽奖,抽出来的号属于哪个进程,哪个进程就能运行。-
例如,计算机系统中有两个进程PA和PB,优先级分别为2和8,这样它们分别拥有2张(编号为0-1)和8张彩票(编号为2-9),按照彩票调度策略,操作系统会分配PA大约20%的处理器时间,而PB会分配到大约80%的处理器时间
-
这个彩票调度的优势有两点
- 第一点是可以解决饥饿问题,即使某个低优先级进程获得的彩票比较少,但经过比较长的时间,按照概率,会有获得处理器执行的时间片
- 第二点是调度策略的实现开销小,因为它不像之前的调度策略,还需要记录、统计、排序、查找历史信息(如统计就绪态等待时间等),彩票调度几乎不需要记录任何历史信息,只需生产一个随机数,然后查找该随机数应该属于那个进程即可
-
-
但彩票调度虽然想法新颖,但有一个问题:如何为进程分配彩票?
- 如果创建进程的用户清楚进程的优先级,并给进程分配对应比例的彩票,那么看起来这个问题就解决了
- 但彩票调度是在运行时的某个时刻产生一个随机值,并看这个随机值属于当前正在运行中的进程集合中的哪一个进程
- 而用户无法预知,未来的这个时刻,他创建的进程与当时的那些进程之间的优先级相对关系,这会导致公平性不一定能得到保证
-
另外一个问题是,基于概率的操作方法的随机性会带来不确定性,特别是在一个比较短的时间段里面,进程间的优先级比例关系与它们获得的处理器执行时间的比例关系之间有比较大的偏差,只有在执行时间很长的情况下,它们得到的处理器执行时间比例会比较接近优先级比例
能否用彩票来表示各种计算机资源的份额?
彩票调度中的彩票表示了进程所占处理器时间的相对比例,那么能否用彩票来表示进程占用内存或其他资源的相对比例?
- 为了解决彩票调度策略中的偶然出现不准确的进程执行时间比例的问题。
Waldspurger等进一步提出了步长调度(Stride Scheduling)。这是一个确定性的公平配额调度策略- 其基本思路是:每个进程有一个步长(
Stride)属性值,这个值与进程优先级成反比,操作系统会定期记录每个进程的总步长,即行程(pass),并选择拥有最小行程值的进程运行
- 其基本思路是:每个进程有一个步长(
- 例如,计算机系统中有两个进程PA和PB几乎同时到达,优先级分别为2和8,用一个预设的大整数(如1000)去除以优先级,就可获得对应的步长
- 这样它们的步长分别是500和125在具体执行时,先选择PA执行,它在执行了一个时间片后,其行程为500;在接下来的4个时间片,将选择执行行程少的PB执行,它在连续执行执行4个时间片后,其形成也达到了500
- 并这样周而复始地执行下去,直到进程执行结束。,按照步长调度调度策略,操作系统会分配PA大约20%的处理器时间,而PB会分配到大约80%的处理器时间
- 比较一下这两种调度策略,可以看出彩票调度算法只能在一段比较长的时间后,基于概率上实现优先级等比的时间分配,而步长调度算法可以在每个调度周期后做到准确的优先级等比的时间分配
- 但彩票算法的优势是几乎不需要全局信息,这在合理处理新加入的进程时很精炼
- 比如一个新进程开始执行时,按照步长调度策略,其行程值为0,那么该进程将在一段比较长的时间内一直占用处理器执行,这就有点不公平了
- 如果要设置一个合理的进程值,就需要全局地统计每个进程的行程值,这就带来了比较大的执行开销。但彩票调度策略不需要统计每个进程的彩票数,只需用新进程的票数更新全局的总票数即可
实时计算机系统的调度
计算机系统的应用领域非常广泛,如机器人、物联网、军事、工业控制等。在这些领域中,要求计算机系统能够实时响应,如果采用上述调度方式,不能满足这些需求,这对操作系统提出了新的挑战
-
这里,我们首先需要理解实时的含义。实时计算机系统通常可以分为硬实时(
Hard Real Time)和软实时(Soft Real Time)两类,硬实时是指任务完成时间必须在绝对的截止时间内,如果超过意味着错误和失败,可能导致严重后果。软实时是指任务完成时间尽量在绝对的截止时间内,偶尔超过可以接受 -
实时的任务是由一组进程来实现,其中每个进程的行为是可预测和提前确定的。这些进程称为实时进程,它们的执行时间一般较短。支持实时任务的操作系统称为实时操作系统
约束条件
-
实时计算机系统是一种以确定的时间范围起到主导作用的计算机系统,一旦外设发给计算机一个事件(如时钟中断、网络包到达等),计算机必须在一个确定时间范围内做出响应
-
实时计算机系统中的事件可以按照响应方式进一步分类为周期性(以规则的时间间隔发生)事件或非周期性(发生时间不可预知)事件。一个系统可能要响应多个周期性事件流。根据每个事件需要处理时间的长短,系统甚至有可能无法处理完所有的事件
-
这样,实时计算机系统的约束条件也随之发生了新的变化:
- 每个进程可不同时间到达
- 每个进程的执行时间不同
- 进程的启动时间和执行时间是未知的
- 进程在整个执行过程期间会执行I/O操作
- 进程在执行过程中会被抢占
- 进程的行为是可预测和提前确定的,即进程在独占处理器的情况下,执行时间的上限是可以提前确定的
- 触发进程运行的事件需要进程实时响应,即进程要在指定的绝对截止时间内完成对各种事件的处理
- 这里主要增加了第6和7点。第6点说明了实时进程的特点,第7点说明了操作系统调度的特点
性能指标
-
对于实时计算机系统而言,进程的周转时间快和响应时间低这样的性能指标并不是最主要的,进程要在指定的绝对的截止时间内完成是第一要务
-
这里首先需要理解实时计算机系统的可调度性。如果有$m$个周期事件,事件$i$以周期时间$P_i$ 发生,并需要$C_i$ 时间处理一个事件,那么计算机系统可以处理任务量(也称负载)的条件是:
$$ SUM(\frac{C_i}{P_i}) \le 1 $$
-
能满足这个条件的实时计算机系统是可实时调度的
-
满足这个条件的实时系统称为是可调度的。例如,一个具有两个周期性事件的计算机系统,其事件周期分别是20ms、80ms。如果这些事件分别需要10ms、20ms来进行处理,那么该计算机系统是可实时调度的,因为
$$ \frac {10}{20} + \frac{20}{80} = 0.75 \le 1 $$
- 如果再增加第三个周期事件,其周期是100ms,需要50ms的时间来处理,我们可以看到
$$ \frac {10}{20} + \frac{20}{80} + \frac{50}{100} = 1.25 \ge 1 $$
- 这说明该计算机系统是不可实时调度的
-
实时计算机系统的调度策略/算法可以是静态或动态的
-
静态调度在进程开始运行之前就作出调度决策
-
动态调度要在运行过程中进行调度决策
-
只有在预知进程要所完成的工作时间上限以及必须满足的截止时间等全部信息时,静态调度才能工作
-
而动态调度则不需要这些前提条件
-
速率单调调度
-
速率单调调度($Rate\ Monotonic\ Scheduling,RMS$)算法是由刘炯朗($Chung\ Laung\ Liu$)教授和$James\ W.\ Layland$在1973年提出的
-
该算法的基本思想是根据进程响应事件的执行周期的长短来设定进程的优先级,即执行周期越短的进程优先级越高
-
操作系统在调度过程中,选择优先级最高的就绪进程执行,高优先级的进程会抢占低优先级的进程
- 该调度算法有如下的前提假设
- 每个周期性进程必须在其执行周期内完成,以完成对周期性事件的响应
- 进程执行不依赖于任何其他进程
- 进程的优先级在执行前就被确定,执行期间不变
- 进程可被抢占
-
可以看出,
RMS调度算法在每个进程执行前就分配给进程一个固定的优先级,优先级等比于进程所响应的事件发生的周期频率 -
即进程优先级与进程执行的速率(单位时间内运行进程的次数)成线性关系,这正是为什么将其称为速率单调的原因
-
例如,必须每20ms运行一次(每秒要执行50次)的进程的优先级为50,必须每50ms运行一次(每秒20次)的进程的优先级为20
-
Liu和Layland证明了在静态实时调度算法中,RMS是最优的 -
任务执行中间既不接收新的进程,也不进行优先级的调整或进行CPU抢占
-
因此这种算法的优点是系统消耗小,缺点是不灵活。一旦该系统的任务决定了,就不能再接收新的任务
-
采用抢占的、静态优先级的策略,调度周期性任务
EDF调度
-
另一个典型的实时调度算法是最早截止时间优先($Earliest\ Deadline\ First,EDF$)算法,其基本思想是根据进程的截止时间来确定任务的优先级
-
截止时间越早,其优先级就越高
-
如果进程的截止期相同,则处理时间短的进程优先级高
-
操作系统在调度过程中,选择优先级最高的就绪进程执行,高优先级的进程会抢占低优先级的进程
-
- 该调度算法有如下的前提假设
- 进程可以是周期性或非周期性的
- 进程执行不依赖于任何其他进程
- 进程的优先级在执行过程中会基于进程的截止期动态变化
- 进程可被抢占
-
EDF调度算法按照进程的截止时间的早晚来分配优先级,截止时间越近的进程优先级越高 -
操作系统在进行进程调度时,会根据各个进程的截止时间重新计算进程优先级,并选择优先级最高的进程执行,即操作系统总是优先运行最紧迫的进程
-
在不同时刻,两个周期性进程的截止时间的早晚关系可能会变化,所以
EDF调度算法是一种动态优先级调度算法
实时调度实例
- 系统中有三个周期性进程PA、PB和PC,它们在一开始就处于就绪状态,它们的执行周期分别是20ms、50ms和100ms
- 它们响应事件的处理时间分别为5ms、20ms和25ms
-
操作系统需要考虑如何调度PA、PB和PC,以确保它们在周期性的截止时间(最终时限,即当前执行周期的绝对时间)到来前都能完成各自的任务
-
计算可调度性
$$ \frac{5}{20} + \frac{20}{50} + \frac{25}{100} = 0.25 + 0.4 + 0.25 = 0.9 \le 1 $$
- 可以看到处理器在理论上有10%的空闲时间,不会被超额执行,所以找到一个合理的调度应该是可能的
-
RMS调度算法 -
由于进程的优先级只与进程的执行周期成线性关系,所以三个进程的优先级分别为50、20和10
-
调度执行过程
-
t=0:在t=0时刻,优先级最高的PA先执行(PA的第一个周期开始),并在5ms时完成
-
t=5:在PA完成后,PB接着执行
-
t=20:在执行到20ms时(PA的第二个周期开始),PA抢占PB并再次执行,直到25m时结束
-
t=25:然后被打断的PB继续执行,直到30ms时结束
-
t=30:接着PC开始执行(PC的第一个周期开始)
-
t=40:在执行到40ms时(PA的第三个周期开始),PA抢占PC并再次执行,直到45ms结束
-
t=45:然后被打断的PC继续执行
-
t=50:然后在50ms时(PB的第二个周期),PB抢占PC并再次执行
-
t=60:然后在60ms时(PA的第四个周期开始),PA抢占PB并再次执行,直到65ms时结束
-
t=65:接着PB继续执行,并在80ms时结束
-
t=80:接着PA继续抢占PC(PA的第五个周期开始),在85ms时结束
-
t=85:然后PC再次执行,在90ms时结束
-
-
这样,在100ms的时间内,PA执行了5个周期任务,PB执行了2个周期任务,PC执行了1个周期任务。在下一个100ms的时间内,上述过程再次重复
- 对于
EDF调度算法而言,具有如下的调度执行过程- t=0:首先选择截止时间最短的PA,所以它先执行(PA的第一个周期开始),并在5ms时完成
- t=5:在PA完成后,截止时间第二的PB接着执行
- t=20:在执行到20ms时(PA的第二个周期开始),PA截止时间40ms小于PB截止时间50ms,所以抢占PB并再次执行,直到25m时结束
- t=25:然后被打断的PB继续执行,直到30ms时结束
- t=30:接着PC开始执行(PC的第一个周期开始)
- t=40:在执行到40ms时(PA的第三个周期开始),PA截止时间40ms小于PC截止时间100ms,PA抢占PC并再次执行,直到45ms结束
- t=45:然后被打断的PC继续执行
- t=50:然后在50ms时(PB的第二个周期),PB截止时间100ms小于等于PC截止时间100ms,PB抢占PC并再次执行
- t=60:然后在60ms时(PA的第四个周期开始),PA截止时间80ms小于PB截止时间100ms,PA抢占PB并再次执行,直到65ms时结束
- t=65:接着PB继续执行,并在80ms时结束
- t=80:接着PA截止时间100ms小于等于PC截止时间100ms,PA继续抢占PC(PA的第五个周期开始),在85ms时结束
- t=85:然后PC再次执行,在90ms时结束
- 上述例子的一个有趣的现象是,虽然RMS调度算法与EDF的调度策略不同,但它们的调度过程是一样的。注意,这不是普遍现象,也有一些例子会出现二者调度过程不同的情况,甚至RMS调度无法满足进程的时限要求,而EDF能满足进程的时限要求
多处理器计算机系统的调度
在2000年前,多处理器计算机的典型代表是少见的高端服务器和超级计算机,但到了2000年后,单靠提高处理器的频率越来越困难,而芯片的集成度还在进一步提升,所以在一个芯片上集成多个处理器核成为一种自然的选择。到目前位置,在个人计算机、以手机为代表的移动终端上,多核处理器(
Multi Core)已成为一种普遍的现象,多个处理器核能够并行执行,且可以共享Cache和内存
约束条件
-
为了理解多处理器调度需要解决的新问题,我们需要理解单处理器计算机与多处理器计算机的基本区别
-
对于多处理器计算机而言,每个处理器核心会有共享的
Cache,也会有它们私有的Cache,而各自的私有Cache中的数据有硬件来保证数据的Cache一致性(也称缓存一致性) -
简单地说,位于不同私有
Cache中的有效数据(是某一内存单元的值)要保证是相同的,这样处理器才能取得正确的数据,保证计算的正确性,这就是Cache一致性的基本含义 -
保证一致性的控制逻辑是由硬件来完成的,对操作系统和应用程序而言,是透明的
-
-
在共享
Cache和内存层面,由于多个处理器可以并行访问位于共享Cache和内存中的共享数据,所以需要有后面章节讲解的同步互斥机制来保证程序执行的正确性
-
基本思路
-
以给创建的新子进程设置进程号为例
-
在单处理器情况下,操作系统用一个整型全局变量保存当前可用进程号,初始值为 0 。给新进程设置新进程号的过程很简单:
- 新进程号= 当前可用进程号
- 当前可用进程号 = 当前可用进程号 + 1
-
在多处理器情况下,假设两个位于不同处理器上的进程都发起了创建子进程的系统调用请求,操作系统可以并行地执行创建两个子进程,而且需要给子进程设置一个新的进程号。如果没有一些同步互斥的手段,那么可能出现如下的情况:
-
$t_o:ID_{PA} = CurlD\ and \ ID_{PB} = CurlD\newline t_1: CurlD = CurlD+1\ and\ CurlD= CurlD + 1$
-
这样两个新进程的进程号就是一样的了,这就会在后续的执行中出现各种问题。为了正确处理共享变量,就需要用类似互斥锁(
Mutex)的方法,让在不同处理器上执行的控制流互斥地访问共享变量,这样就能解决正确性问题 -
所以,对于多处理器下运行的进程而言,新增加了如下的假设条件
- 运行在不同处理器上的多个进程可用并行执行,但对于共享资源/变量的处理,需要有同步互斥等机制的正确性保证
-
性能指标
- 这里的性能指标与之前描述的基于单处理器的通用计算机系统一样,主要是周转时间、响应时间和公平性
单队列调度
-
对于多处理器系统而言,两个进程数量多于处理器个数,我们希望每个处理器都执行进程
-
这一点是之前单处理器调度不会碰到的情况。单处理器的调度只需不断地解答:“接下来应该运行哪个进程?”,而在多处理机中,调度还需解答一个问题:“要运行的进程在哪一个CPU上运行?”。这就增加了调度的复杂性
-
如果我们直接使用单处理器调度的数据结构,其中的重点就是放置就绪进程的就绪队列或其他与调度相关的数据结构。那么这些数据结构就是需要互斥访问的共享数据
-
为简化分析过程,我们以轮转调度采用的单就绪队列为例,面向多处理器的单队列调度的策略逻辑没有改变,只是在读写/修改就绪队列等共享数据时,需要用同步互斥的一些操作保护起来,确保对这些共享数据访问的正确性
-
采用单队列调度的一个好处是,它支持自动负载平衡,因为决不会出现一个CPU空闲而其他CPU过载的情况
处理器亲和性
- 另外,还需考虑的一个性能问题是调度中的处理器亲和性(也称缓存亲和性、调度亲和性)问题
- 其基本思想是,尽量使一个进程在它前一次运行过的同一个CPU上运行
- 其原因是,现代的处理器都有私有Cache,基于局部性的考虑,如果操作系统在下次调度时要给该进程选择处理器,会优先选择该进程上次执行所在的处理器,从而使得Cache中缓存的数据可重用,提高了进程执行的局部性
多队列调度
-
如果处理器的个数较多,频繁对共享数据执行同步互斥操作的开销会很大
-
为此,能想到的一个方法是,还是保持单处理器调度策略的基本逻辑,但把就绪队列或和他与调度相关的数据结构按处理器个数复制多份,这样操作系统在绝大多数情况下,只需访问本处理器绑定的调度相关数据结构,就可用完成调度操作
-
这样在一个调度控制框架下就包含多个调度队列
-
当要把一个新进程或被唤醒的进程放入就绪队列时,操作系统可根据一些启发式方法(如随机选择某个处理器上的就绪队列或选择就绪进程数量最少的就绪队列)来放置进程到某个就绪队列
-
操作系统通过访问本处理器上的调度相关数据结构,就可以选择出要执行的进程,这样就避免了开销大的同步互斥操作
- 多队列调度比单队列调度具有更好的可扩展性,多队列的数量会随着处理器的增加而增加,也具有良好的缓存亲和度。当多队列调度也有它自己的问题:负载均衡(
Load Balance)问题
- 考虑如下的例子,在一个有4个进程,两个处理器的计算机系统中,有两个就绪队列,PA和PB在就绪队列Q1,PC和PD在就绪队列Q2
- 如果采用基于轮转调度的多队列调度,那么两个处理器可以均匀地让4给进程分时使用处理器。这是一种理想的情况
- 如果进程PB结束,而调度不进行进一步的干预,那么就会出现PA独占处理器1,PC和PD分时共享处理器2
- 如果PA也结束了,而调度还不进行进一步的干预,那么(
Load Imbalance)就会出现——处理器1空闲,而处理器2繁忙的情况,这就是典型的负载不均衡(Load Imbalance)的现象了。这就没有达到轮转调度的意图
-
所以多队列调度需要解决负载不均衡的问题
-
一个简单的思路就是允许进程根据处理器的负载情况从一个处理器迁移到另外一个处理器上
- 对于上面的例子,如果是处理器1空闲,处理器2繁忙的而情况,操作系统只需把处理器2上的进程分一半,迁移到处理器1即可
-
当如果是处理器1上运行了PA,处理器2上运行了PC和PD,这就需要统计每个进程的执行时间,根据进程的执行时间,让进程在两个处理器间不停的迁移,达到在一定时间段内,每个进程所占用的处理器时间大致相同,这就达到了轮转调度的意图,并达到了负载均衡
-
-
比如下面的调度方式
$$ \begin{align} &处理器1:A\rightarrow A\rightarrow C \rightarrow A \rightarrow A \rightarrow C \rightarrow \dots \newline &处理器2:C\rightarrow D\rightarrow D\rightarrow C\rightarrow D \rightarrow D \rightarrow \dots \newline &或者是:\newline &处理器1:A\rightarrow C\rightarrow A \rightarrow A \rightarrow C \rightarrow A \rightarrow \dots \newline &处理器2:C\rightarrow D\rightarrow D\rightarrow C\rightarrow D \rightarrow D \rightarrow \dots \newline \end{align} $$
-
当然,这个例子是一种简单的理想情况,实际的多处理器计算机系统中运行的进程行为会很复杂,除了并行执行,还有同步互斥执行、各种/O操作等,这些都会对调度策略产生影响
-
如果需要了解实际的操作系统调度策略和算法,建议阅读关于
UNIX、Linux、Windows和各种RTOS等操作系统内核的书籍和文章,其中有关于这些操作系统的调度策略和算法的深入讲解
声明:本文章引用资料与图像均已做标注,如有侵权本人会马上删除