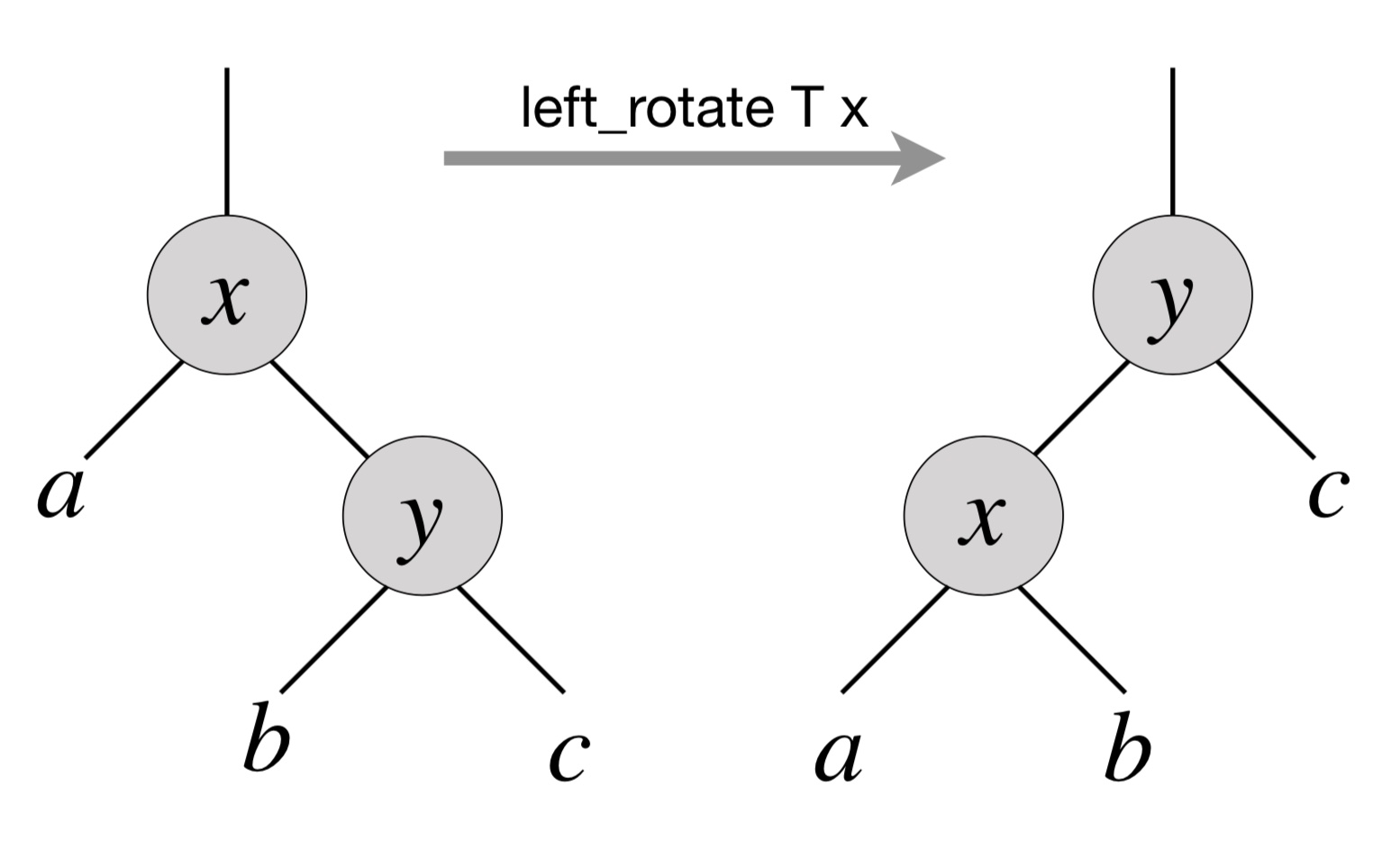
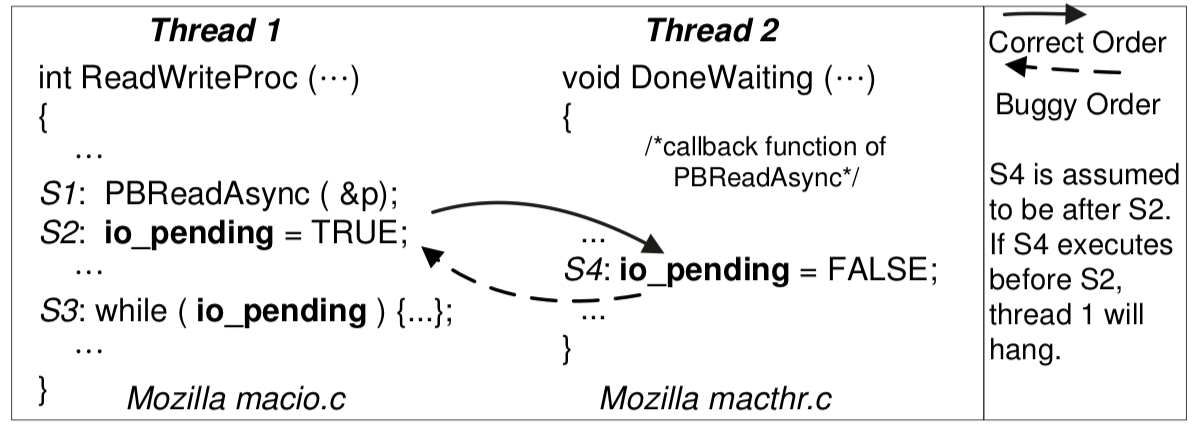
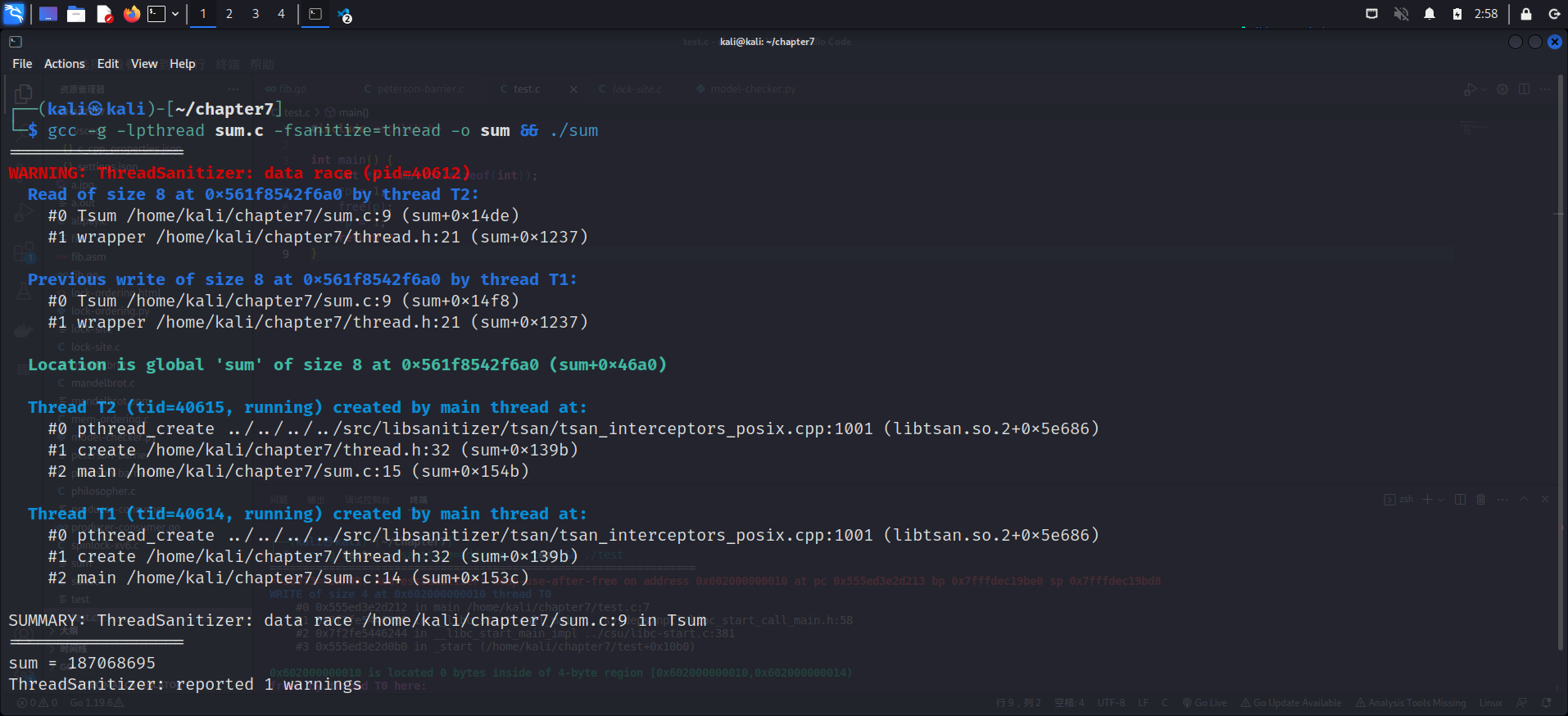
#include"thread.h"#define A 1
#define B 2
#define BARRIER __sync_synchronize()
atomic_intnested;atomic_longcount;voidcritical_section(){longcnt=atomic_fetch_add(&count,1);inti=atomic_fetch_add(&nested,1)+1;if(i!=1){printf("%d threads in the critical section @ count=%ld\n",i,cnt);assert(0);}atomic_fetch_add(&nested,-1);}intvolatilex=0,y=0,turn;voidTA(){while(1){x=1;BARRIER;turn=B;BARRIER;// <- this is critcal for x86
while(1){if(!y)break;BARRIER;if(turn!=B)break;BARRIER;}critical_section();x=0;BARRIER;}}voidTB(){while(1){y=1;BARRIER;turn=A;BARRIER;while(1){if(!x)break;BARRIER;if(turn!=A)break;BARRIER;}critical_section();y=0;BARRIER;}}intmain(){create(TA);create(TB);}
usestd::{sync::{Arc,Mutex},thread,time::Duration,};fnmain(){letx=Arc::new(Mutex::new(0));lety=Arc::new(Mutex::new(0));letx1=Arc::clone(&x);lety1=Arc::clone(&y);letx2=Arc::clone(&x);lety2=Arc::clone(&y);lethandle1=thread::spawn(move||{letx=x1.lock().unwrap();println!("handle1 has own x: {}",*x);thread::sleep(Duration::from_secs(100));lety=y1.lock().unwrap();println!("handle1 has own y: {}",*y);});lethandle2=thread::spawn(move||{lety=y2.lock().unwrap();println!("handle2 has own y: {}",*y);thread::sleep(Duration::from_secs(100));letx=x2.lock().unwrap();println!("handle2 has own x: {}",*x);});handle1.join().unwrap();handle2.join().unwrap();}
// Mutual exclusion spin locks.
#include"types.h"#include"param.h"#include"memlayout.h"#include"spinlock.h"#include"riscv.h"#include"proc.h"#include"defs.h"voidinitlock(structspinlock*lk,char*name){lk->name=name;lk->locked=0;lk->cpu=0;}// Acquire the lock.
// Loops (spins) until the lock is acquired.
voidacquire(structspinlock*lk){push_off();// disable interrupts to avoid deadlock.
if(holding(lk))panic("acquire");// On RISC-V, sync_lock_test_and_set turns into an atomic swap:
// a5 = 1
// s1 = &lk->locked
// amoswap.w.aq a5, a5, (s1)
while(__sync_lock_test_and_set(&lk->locked,1)!=0);// Tell the C compiler and the processor to not move loads or stores
// past this point, to ensure that the critical section's memory
// references happen strictly after the lock is acquired.
// On RISC-V, this emits a fence instruction.
__sync_synchronize();// Record info about lock acquisition for holding() and debugging.
lk->cpu=mycpu();}// Release the lock.
voidrelease(structspinlock*lk){if(!holding(lk))panic("release");lk->cpu=0;// Tell the C compiler and the CPU to not move loads or stores
// past this point, to ensure that all the stores in the critical
// section are visible to other CPUs before the lock is released,
// and that loads in the critical section occur strictly before
// the lock is released.
// On RISC-V, this emits a fence instruction.
__sync_synchronize();// Release the lock, equivalent to lk->locked = 0.
// This code doesn't use a C assignment, since the C standard
// implies that an assignment might be implemented with
// multiple store instructions.
// On RISC-V, sync_lock_release turns into an atomic swap:
// s1 = &lk->locked
// amoswap.w zero, zero, (s1)
__sync_lock_release(&lk->locked);pop_off();}// Check whether this cpu is holding the lock.
// Interrupts must be off.
intholding(structspinlock*lk){intr;r=(lk->locked&&lk->cpu==mycpu());returnr;}// push_off/pop_off are like intr_off()/intr_on() except that they are matched:
// it takes two pop_off()s to undo two push_off()s. Also, if interrupts
// are initially off, then push_off, pop_off leaves them off.
voidpush_off(void){intold=intr_get();intr_off();if(mycpu()->noff==0)mycpu()->intena=old;mycpu()->noff+=1;}voidpop_off(void){structcpu*c=mycpu();if(intr_get())panic("pop_off - interruptible");if(c->noff<1)panic("pop_off");c->noff-=1;if(c->noff==0&&c->intena)intr_on();}
Textbooks will tell you that if you always lock in the same order, you will never get this kind of deadlock. Practice will tell you that this approach doesn’t scale: when I create a new lock, I don’t understand enough of the kernel to figure out where in the 5000 lock hierarchy it will fit.
The best locks are encapsulated: they never get exposed in headers, and are never held around calls to non-trivial functions outside the same file. You can read through this code and see that it will never deadlock, because it never tries to grab another lock while it has that one. People using your code don’t even need to know you are using a lock.
gcc -g test.c -fsanitize=address -o test&& ./test
===================================================================37384==ERROR: AddressSanitizer: heap-use-after-free on address 0x602000000010 at pc 0x55c0a903b213 bp 0x7ffe5d50fcd0 sp 0x7ffe5d50fcc8
WRITE of size 4 at 0x602000000010 thread T0
#0 0x55c0a903b212 in main /home/kali/chapter7/test.c:7#1 0x7f8416046189 in __libc_start_call_main ../sysdeps/nptl/libc_start_call_main.h:58#2 0x7f8416046244 in __libc_start_main_impl ../csu/libc-start.c:381#3 0x55c0a903b0b0 in _start (/home/kali/chapter7/test+0x10b0)0x602000000010 is located 0 bytes inside of 4-byte region [0x602000000010,0x602000000014)freed by thread T0 here:
#0 0x7f84162b76a8 in __interceptor_free ../../../../src/libsanitizer/asan/asan_malloc_linux.cpp:52#1 0x55c0a903b1db in main /home/kali/chapter7/test.c:6#2 0x7f8416046189 in __libc_start_call_main ../sysdeps/nptl/libc_start_call_main.h:58previously allocated by thread T0 here:
#0 0x7f84162b89cf in __interceptor_malloc ../../../../src/libsanitizer/asan/asan_malloc_linux.cpp:69#1 0x55c0a903b18a in main /home/kali/chapter7/test.c:4#2 0x7f8416046189 in __libc_start_call_main ../sysdeps/nptl/libc_start_call_main.h:58SUMMARY: AddressSanitizer: heap-use-after-free /home/kali/chapter7/test.c:7 in main
Shadow bytes around the buggy address:
0x0c047fff7fb0: 00000000000000000000000000000000 0x0c047fff7fc0: 00000000000000000000000000000000 0x0c047fff7fd0: 00000000000000000000000000000000 0x0c047fff7fe0: 00000000000000000000000000000000 0x0c047fff7ff0: 00000000000000000000000000000000=>0x0c047fff8000: fa fa[fd]fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff8010: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff8020: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff8030: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff8040: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff8050: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
Shadow byte legend (one shadow byte represents 8 application bytes):
Addressable: 00 Partially addressable: 01020304050607 Heap left redzone: fa
Freed heap region: fd
Stack left redzone: f1
Stack mid redzone: f2
Stack right redzone: f3
Stack after return: f5
Stack use after scope: f8
Global redzone: f9
Global init order: f6
Poisoned by user: f7
Container overflow: fc Array cookie: ac
Intra object redzone: bb
ASan internal: fe
Left alloca redzone: ca
Right alloca redzone: cb==37384==ABORTING