CMU 15-445 Lecture #02: Modern SQL
CMU 15-445 Database Systems
Lecture #02: Modern SQL
关系型数据库|SQL
-
在历经上个世纪的探索和总结后,关系型数据库被发明了出来,其使用的语言也规范为了SQL
-
SQL可以分为三类
- 数据操作语言(DML):SELECT,INSERT,UPDATE,DELETE
- 数据定义语言(DDL):用于定义表,视图等
- 数据控制语言(DCL):用于访问控制,保证数据库的安全
-
SQL也和其他编程语言一样,每隔几年会更新一次,目前规定最低标准是SQL-92
Some of the major updates released with each new edition of the SQL standard are shown below.
• SQL:1999 Regular expressions, Triggers
• SQL:2003 XML, Windows, Sequences
• SQL:2008 Truncation, Fancy sorting
• SQL:2011 Temporal DBs, Pipelined DML
• SQL:2016 JSON, Polymorphic tables
Joins
- 合并一个或多个表中的列生成新表,主要用于需要使用多个表中数据的操作
- 例子:查学生成绩
|
|
- Example: Which students got an A in 15-721?
|
|
Aggregates
- 接受Tuples,对整体进行计算,几乎只能用于SELECT输出列表
• AVG(COL): The average of the values in COL
• MIN(COL): The minimum value in COL
• MAX(COL): The maximum value in COL
• COUNT(COL): The number of tuples in the relation
- Example: Get # of students with a ‘@cs’ login.
- 下面三个查询是等价的(第三个是COUNT里面填入数字统计出来的都是行数)
|
|
- 可以在一个SELECT中使用多个聚合函数
|
|
-
一些聚合函数支持
DISTINCT的关键字(比如COUNT, SUM, AVG)),这样在计算的时候就直接去重了(unique) -
使用聚合函数/分组后除了聚合函数其他的输出都是undefined,尽量不要使用
|
|
- 如果想让列属性是defined的话,那就必须在
GROUP BY中加入该属性(也就是用这个属性分组)
|
|
- 如果想要过滤聚合函数的数据,需要使用HAVING
|
|
String Operations
- SQL区分字符串大小写,使用单引号
- Pattern Matching: The LIKE keyword is used for string matching in predicates.
- “%” matches any substrings (including empty).
- “_” matches any one character
- String Functions:SQL-92 defines string functions. Many database systems implement other functions in addition to those in the standard. Examples of standard string functions include SUBSTRING(S, B, E) and UPPER(S).
- Concatenation: Two vertical bars (“||”) will concatenate two or more strings together into a single string.
Date and Time
- Operations to manipulate DATE and TIME attributes. Can be used in either output or predicates. The specific syntax for date and time operations varies wildly across systems.
Output Redirection
-
可以将查询的结果直接存储在另一张表中
-
New Table: Store the output of the query into a new (permanent) table.
|
|
- Existing Table: Store the output of the query into a table that already exists in the database. The target table must have the same number of columns with the same types as the target table, but the names of the columns in the output query do not have to match.
|
|
Output Control
- 排序使用ORDER BY,默认是升序排序ASC,如果使用降序请显示标明DESC
|
|
- 可以使用多个ORDER BY效果就是先排序A,A相同比较B
|
|
- 在ORDER BY中可以计算/使用函数
|
|
- 可以使用LIMIT限制数据范围
|
|
Nested Queries
- 在查询中使用其他查询的结果,嵌套查询通常很难被优化
|
|
Nested Query Results Expressions:
• ALL: Must satisfy expression for all rows in sub-query.
• ANY: Must satisfy expression for at least one row in sub-query.
• IN: Equivalent to =ANY().
• EXISTS: At least one row is returned
|
|
Window Functions
- 解决了分组后非聚合函数数值undefined的问题,保留了原来的列结构
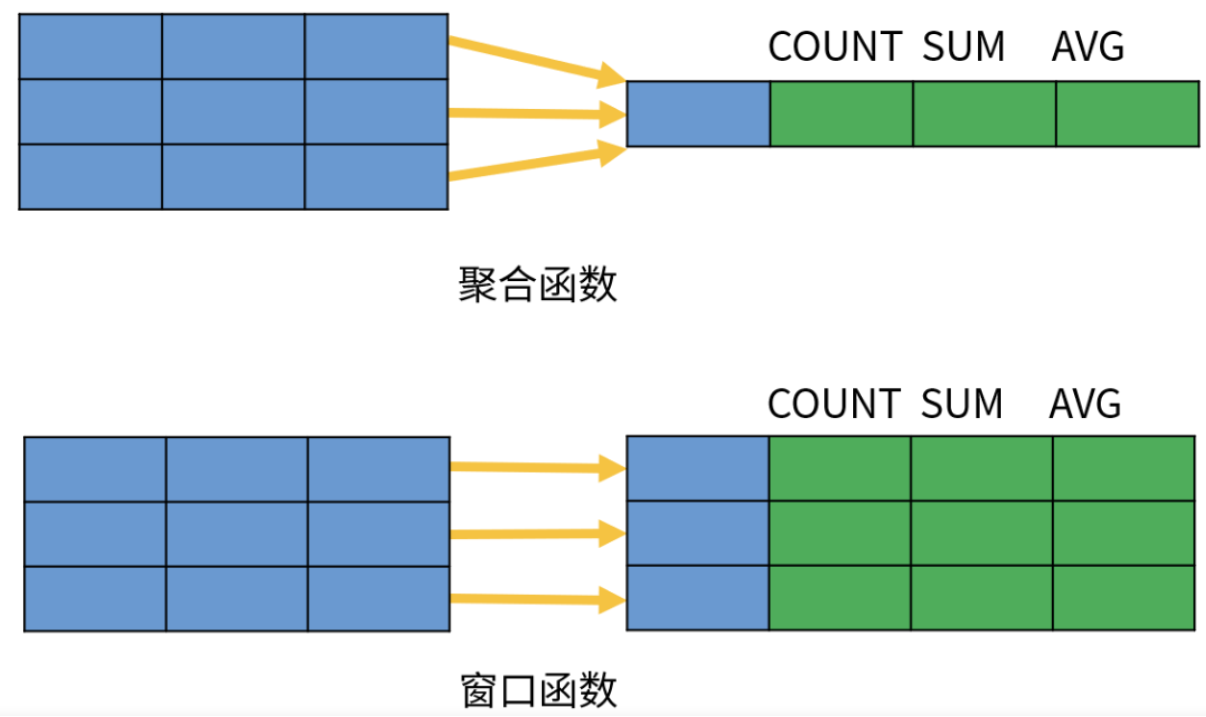
-
ROW NUMBER: The number of the current row.
-
RANK: The order position of the current row.
|
|
- 本质上面来说是一种分析函数,将order by之后的组进行二次分析,而不是只能使用聚合函数来获取那些值
Common Table Expressions
- 主要是WITH,和Python中的WITH做对比,表示临时变量,这样可以简单的生成临时表用于复杂的操作
|
|
- 递归操作
|
|