CMU 15-445 Lecture #04: Database Storage (Part II)
CMU 15-445 Database Systems
Lecture #04: Database Storage (Part II)
Log-Structured Storage
-
Slotted-Page(页+槽)的存储结构遇到的一些问题
- Fragmentation:删除元组可能会在页中留下空白
- Useless Disk I/O:更新一组数据,但是你要把这个数据所在的页从磁盘load到内存里面
- Random Disk I/O:如果说你随机更新了很多数据,那么可能需要从磁盘load好多页到内存,时间会变得非常慢
- 另一种解决思路:Log-Structured Storage
Log-structured Storage is based on the Log-Structured File System (LSFS) by Rosenblum and Ousterhout’92 and Log-structured Merge Trees (LSM Tree) by O’Neil, Cheng
LSM-tree也是数据库里面一个重要的知识点
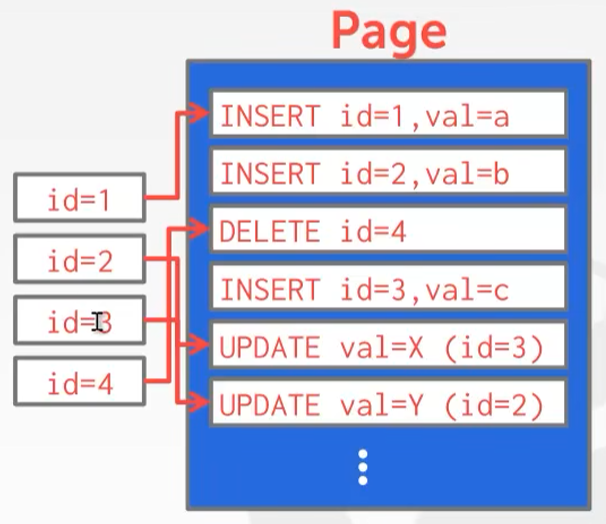
- DBMS不存储元组,而是只存储元组更改的记录,DBMS将新的日志添加到内存缓冲区中,不检查之前记录,然后按照更改数据写回到磁盘里面(这个顺序写盘就能解决上面的Random Disk I/O问题),
- 这种模式对于写数据库的操作来说速度很快(直接写一个log刷回到盘里面就行了),这个在K-V数据库里面很流行
- 读记录的时候则需要从最旧的顺序扫描日志文件,从而获取元组的最新内容,为了提高效率,log也会使用索引来加快查找速度
-
Compaction
-
如果就一直记录日志,那么磁盘肯定有一天会不够写,所以DBMS需要定期压缩日志,压缩后的日志甚至不用按照时间戳排序,而是按照id排序(找的更快)
-
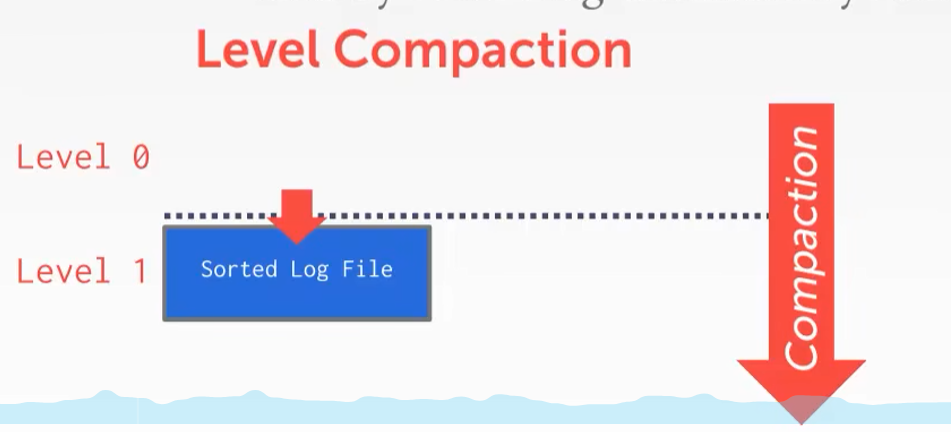
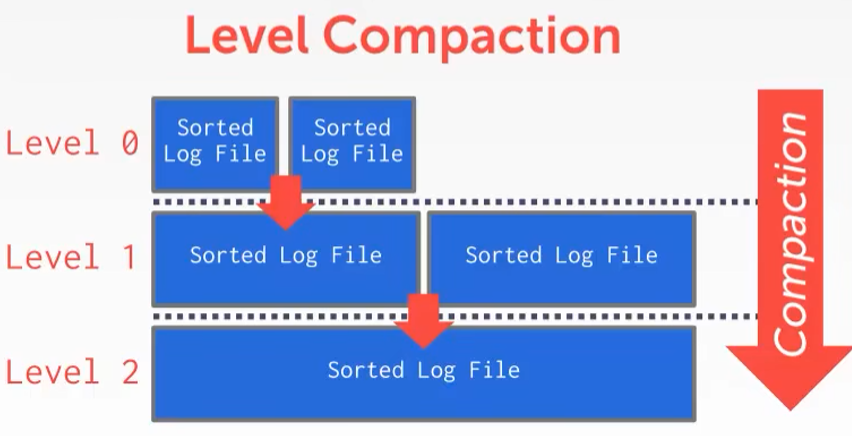
按层压缩(Level Compaction)
- 代表:RocksDB(RocksDB第一/二/三层文件)

Level0的两个文件内部可以压缩,但是如果update A在文件一,delete A在文件二,那这两条数据就没法合并压缩了
解决方案:直接读取这两个文件中的日志,一起压缩到Level1的一个新文件里面
这种情况可以一直递归压缩 - RocksDB最多能压缩到第七层
- 读取的时候就从0层开始读,读不到就再读下一层
-
通用压缩(Universal Compaction)
不用分层,能合并就合并


- Log-Structured Storage的利弊
- 快速的顺序写入,对于需要频繁更改的数据库来说效率提示很多
- 读取可能很慢(要读很多日志)
- 压缩日志的代价很大
- 受制于写入放大(一个逻辑写入可能有多个物理写入,比如UPDATE ALL STUDENT age TO age + 1,对于这种语句到它的日志里面要写一堆)

Index-Organized Storage
- 加入额外的索引存储,从而提高查找的速度
Data Representation
There are five high level datatypes that can be stored in tuples: integers, variable-precision numbers, fixedpoint precision numbers, variable length values, and dates/times.
-
元组中的数据本质就是字节数组,你要规定如何存储和解释这些字节,从而存储你的信息
-
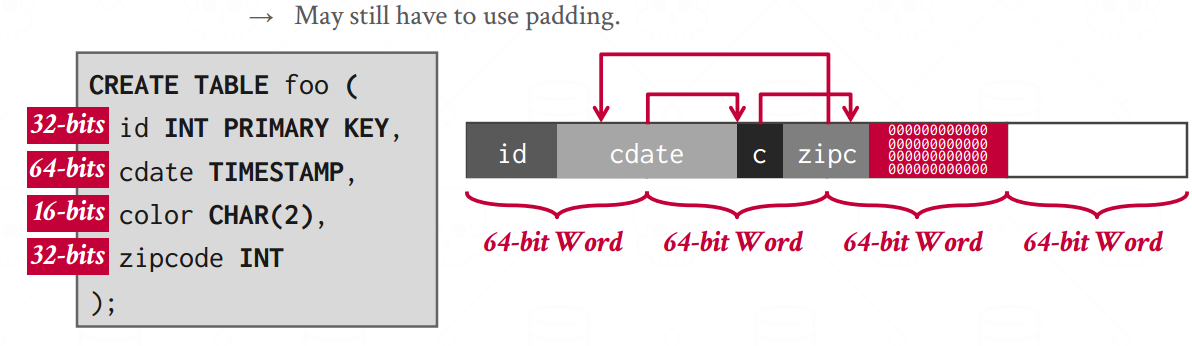
字节对齐的问题
- Padding:在属性后添加空位,确保元组对其
属性长度不够,后面填充字节码 -
Reordering:重新排列属性+填充
能凑到一块的先凑起来,然后再填充
-
-
其他数据表示:整数,字符串这俩都很好记录,字符串可能头部需要存储一个长度,但是也不难,这里重点讨论浮点数/高精度和时间的表示
-
浮点数:IEEE-754下面的标准转到十进制是有误差的,这个在金融等需要绝对准确的领域里面是无法忍受的

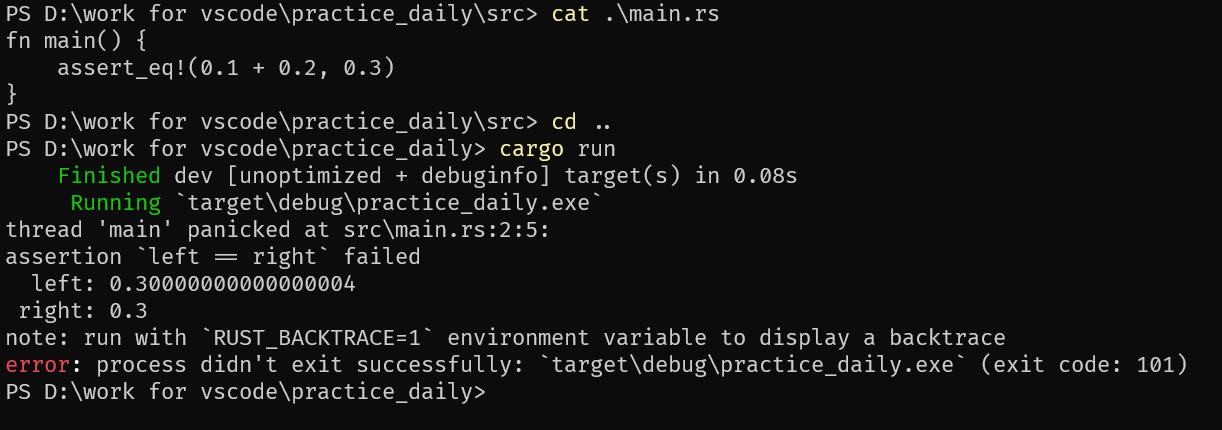
- 解决方案:高精度

-
LARGE VALUES
-
某一段数据很长造成的,比如在存储字符串的地方存了一本电子小说的内容,数据长到比最小的页还长,整个页都没法完整地把这个数据给存储下来
-
解决方案:Overflow Page,新开一个“溢出页”,把大的数据存到这个新开的页里面,然后原始页里面存放这个数据的地方去存放这个新开的页的地址

-
如果溢出页还不够:后面再加溢出页(当成拉链法去理解就好)
-
使用数据库尽量避免这样的情况,很损害数据库的性能
- 一种方案是存成文件,然后数据库里面存文件路径,缺点就是这个文件里面数据没有持久性和事务保护
- Null Data Types
- 在DBMS里面表示null的方法
- Null Column Bitmap Header:在数据的头部集中存储一个bitmap,这个bitmap就表示本条数据里面那些属性是null,这是最常见的方法
- Special Values:用特殊值来标记null,比如给整数标定一个int32min来表示null
- Per Attribute Null Flag:给每个属性前面都加一位来表示这个属性是不是为null,不推荐,因为不节约内存,多这一位的数据可能会造成内存需要填充好几位才能维持字节对齐
System Catalogs
- 每个数据库都有一个System Catalogs,里面的表存自己的元数据(有什么表,表结构,用户,用户权限,统计信息,日志信息。。。)
- 每个数据库里面都有information schema,但是存的东西不一样