CMU 15-445 Lecture #05: Storage Models & Compression
CMU 15-445 Database Systems
Lecture #05: Storage Models & Compression
DataBase WorkLoads
-
On-Line Transaction Processing(OLTP):Fast operations that only read/update a small amount of data each time.
- 快速操作,事务简单,读/写数据量很小
- 通常处理的写操作多于读操作
- 例子:银行转一次钱
- 往往意味着高并发,比如支付宝,微信支付
-
On-Line Analytical Processing(OLAP): Complex queries that read of a lot of data to computer aggregates
- 一般是公司要对某一段时间的所有数据进行统计分析的时候使用
- 事务复杂,且要读大量的数据,从现有的大量数据中分析派生出新的数据
- 典型代表:数仓,深度学习的数据收集(比如常见的深度学习模型的训练)
-
Hybrid(混合) Transaction + Analytical Processing(HTAP): OLTP+OLAP together on the same database instance
- 希望这个数据库两种事务都能应对(兼顾)
- 很像之前讲的disk和memory的结合体(
-
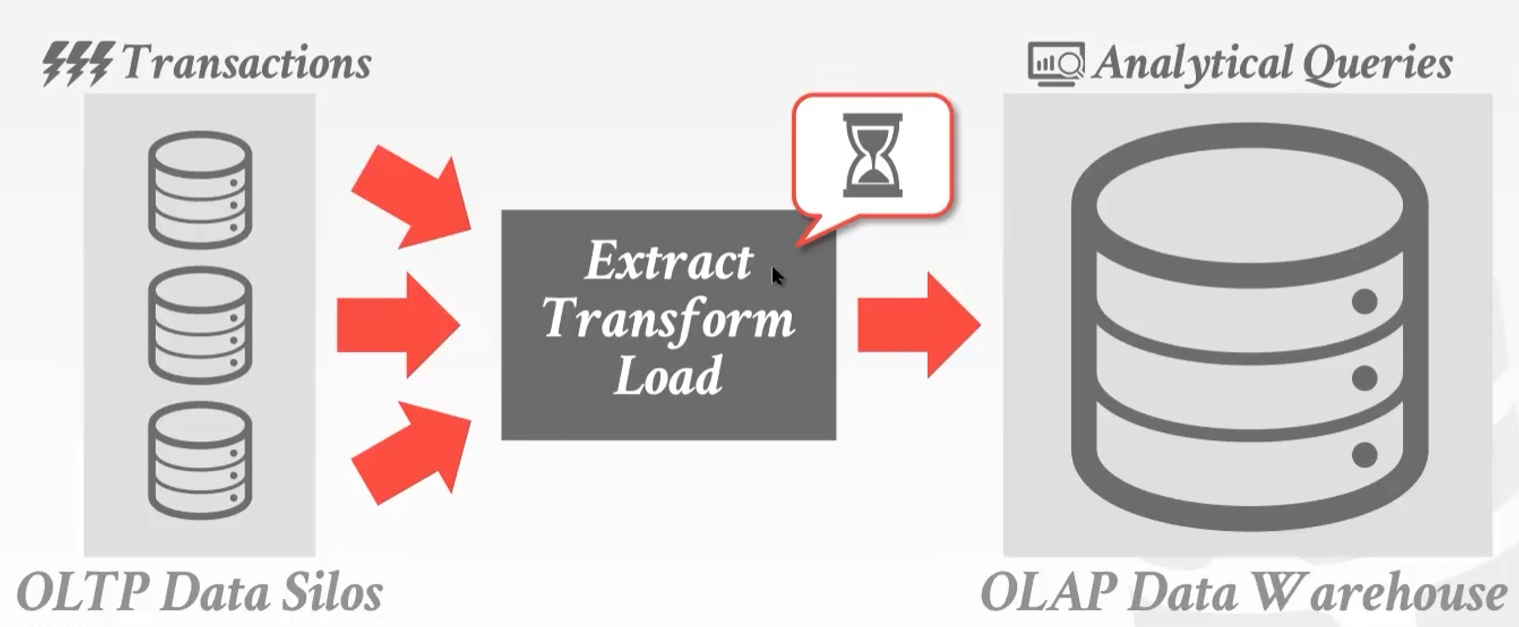
公司方案:BIFURCATED ENVIRONMENT:OLTP和OLAP分别布置
-
HTAP或许能避免上面BIFURCATED ENVIRONMENT(要准备两套数据库,而且数据还要从这两套系统中来回迁移)的问题,但是也有可能是两头都跑不好
-
行存的模型适合OLTP,列存(DSM)的模型适合OLAP
-
现在很多主流数据库也会加入列存引擎来处理OLAP的事务
Storage Models
- 这部分主要讲数据库的数据在磁盘上面不同的物理布局,对于不同的场景,不同的布局会有不一样的效果
-
N-Ary Storage Model (NSM)
-
The DBMS stores (almost) all attributes for a single tuple contiguously in a single page(一个元组里面是所有属性,连续地存储在一个页中)
-
Also known as a “row store”(国内叫“行存”)
-
非常适合OLTP的工作负载,读的东西少,但是一直在频繁的写数据,行存的模型对写数据很友好
-
NSM数据库页面大小通常是硬件页面的常数倍(m $\times$ 4KB):Oracle(4KB),Postgres(8KB),MySQL(16KB)
-
-
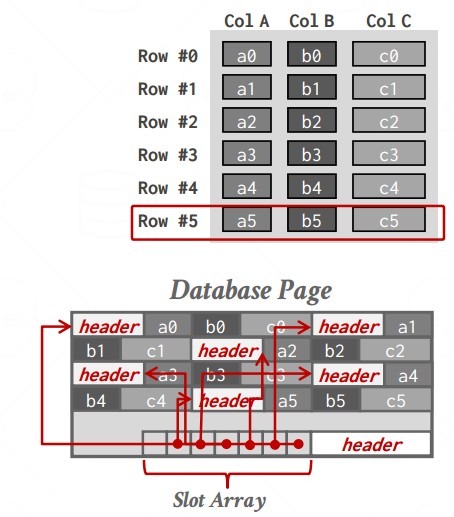
NSM: PHYSICAL ORGANIZATION
-
无论是定长还是不定长度,这个NSM都是用的之前的slotted page的存储模型,元组就连续的存储在页里面,再加上一个slot array来做标定,header来存储头部必要的一些信息
-
DBMS区分物理元组的唯一标识:record id(page#,slot#),注意这个record id是页标识+槽标识构造的,不是数据库主键/唯一键,一定要区分!
-
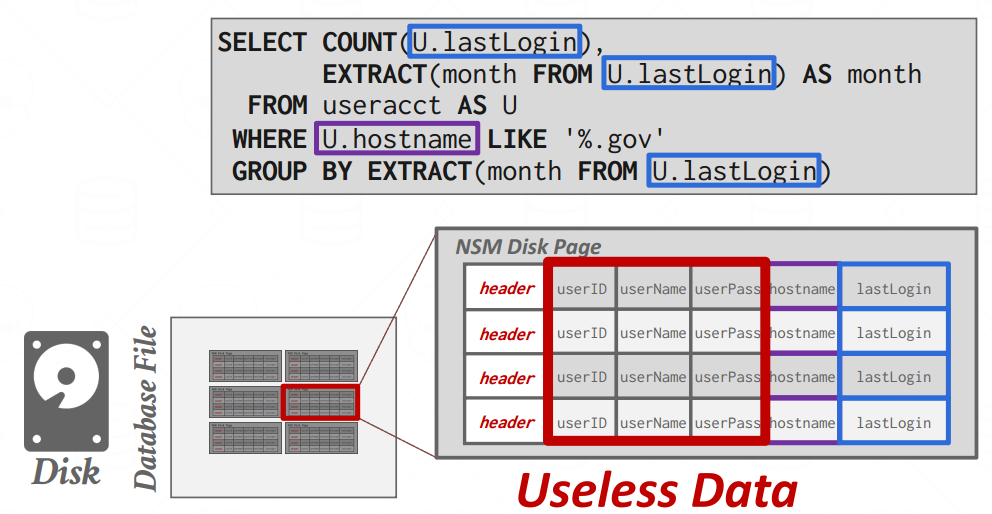
- NSM性能上的缺点
- 进行OLAP的操作的时候会有很多无用的数据,浪费效率
- NSM:SUMMARY
- Advantages
- Fast inserts, updates, and deletes
- Good for queries that need the entire tuple(OLTP)
- Can use index-oriented physical storage for clustering
- Disadvantages
- Not good for scanning large portions of the table and/or a subset of the attributes
- Terrible memory locality for OLAP access patterns.(数据分散到了多个页,属性列不是连续的)
- Not ideal for compression because of multiple value domains within a single page.(压缩数据靠的是数据的相似性,同一列的数据相似性才高,但是NSM是按行存不同列的数据,每一页数据的相似性很低,很难压缩)
- Advantages
-
Decomposition Storage Model (DSM)
- The DBMS stores a single attribute for all tuples contiguously in a block of data.
- Also known as a “column store”(国内叫“列存”)
- 非常适合OLAP的工作负载,大量的读取数据,而且往往都要的是某一列属性
- DBMS这个时候主要就负责读写的时候拆分和组合属性
-
DSM: PHYSICAL ORGANIZATION
-
Store attributes and metadata (e.g.nulls) in separate arrays of fixedlength values.(固定长度的属性最好存储,数组完美匹配)
-
唯一标识:偏移量
-
难的是处理变长属性,需要在前面在加上一个id数据来做为标识,这样其实造成了数据冗余(id存了好几次)
-

属性定长和不定长的两种存储方式 -
Maintain a separate file per attribute with a dedicated header area for metadata about the entire column.(一个属性一个文件,加上Header来处理元数据)
-

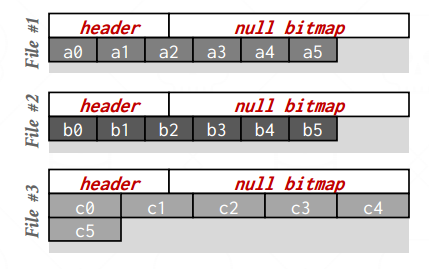
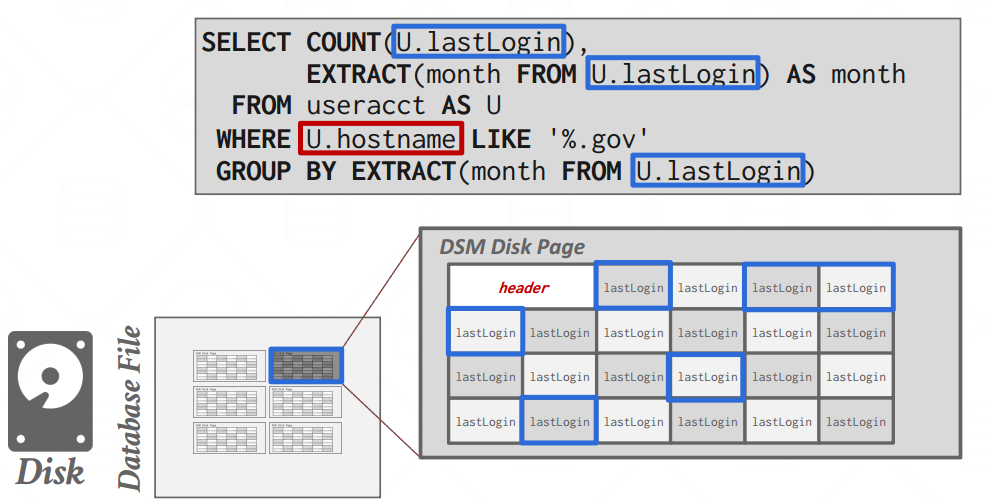
-
DSM:SUMMARY
- Advantages
- Reduces the amount wasted I/O per query because the DBMS only reads the data that it needs.
- Faster query processing because of increased locality and cached data reuse.(属性上面的局部性 > 行的局部性)
- Better data compression (more on this in a few slides).
- Disadvantages
- Slow for point queries, inserts, updates, and deletes because of tuple splitting/stitching/reorganization.
- Advantages
-
OBSERVATION
- OLAP往往也要面临JOIN这样的操作,但是DSM的存储模型在JOIN上面的操作不是很优秀
-
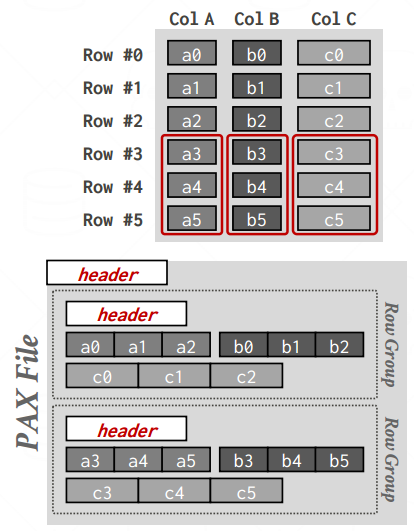
PAX STORAGE MODEL
-
Partition Attributes Across (PAX) is a hybrid storage model that vertically partitions attributes within a database page.
-
The goal is to get the benefit of faster processing on columnar storage while retaining the spatial locality benefits of row storage.(保留行存优势地前提下,在列处理上面提速来匹配OLAP操作)
-
-
PAX: PHYSICAL ORGANIZATION
- 水平地将行划分为组,然后将这组的属性进行列存
- 每个页的Header里面会标明这个页里面每一组的偏移量
- 如果这个文件不可变,Header就存到页脚
- 每一组都会有自己的metadata header(比如标明那一行那个属性是null,其他有关这个组的信息)
Database Compression
-
When a DBMS uses compression, it is always lossless because people don’t like losing data. Any kind of lossy compression must be performed at the application level.(数据库只能做无损压缩,有损压缩只能在应用程序里面做,数据库是绝对不给做的)
-
COMPRESSION GRANULARITY(压缩的力度)
NAÏVE COMPRESSION
-
Block-Level:压缩同一个表里面的元组块
-
使用通用的算法来压缩数据
-
压缩的范围仅限于提供的数据
-
LZO (1996), LZ4 (2011), Snappy (2011),Oracle OZIP (2014), Zstd (2015)
需要考虑的因素
- 计算的开销
- 压缩和解压的速度

- 这个模式的一个弊端就是每次读写数据的时候都先要做解码,效率很低
- 另一个思路:能不能不解码,而是对查询的数据使用算法变换,然后操作压缩后的数据
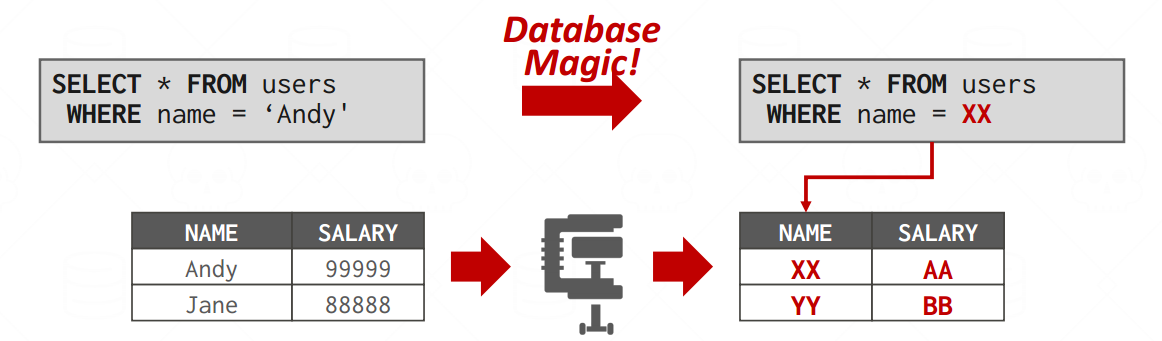
COLUMNAR COMPRESSION
-
Column-Level:压缩属性值的列(DSM-only),也叫COLUMNAR COMPRESSION(柱状压缩)
-
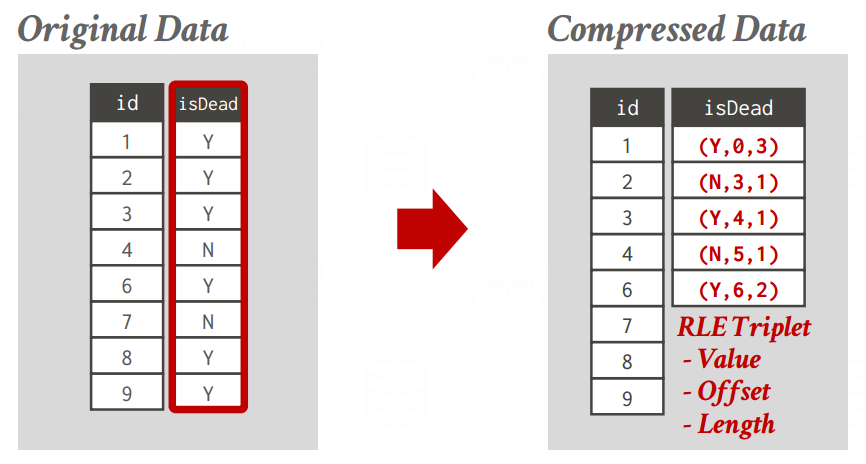
Run-length Encoding
- 将单个列中的相同值改为三元组
- 属性的值
- 该值在这一列的起始位置
- 该值的元素个数
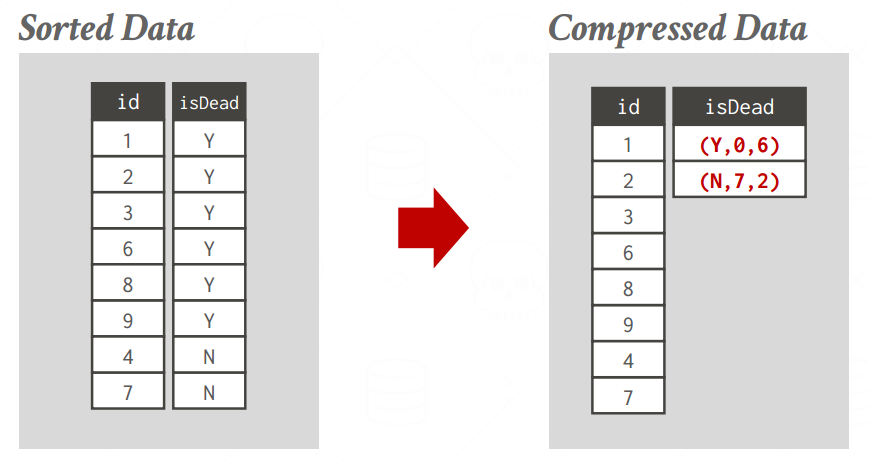
- 适合的情景是该列对属性进行智能排序,这样可以获取最大化压缩的机会
- 将单个列中的相同值改为三元组
- Bit-Packing Encoding
- 如果整数属性的值很小,那么二进制前面的几位就可以不要
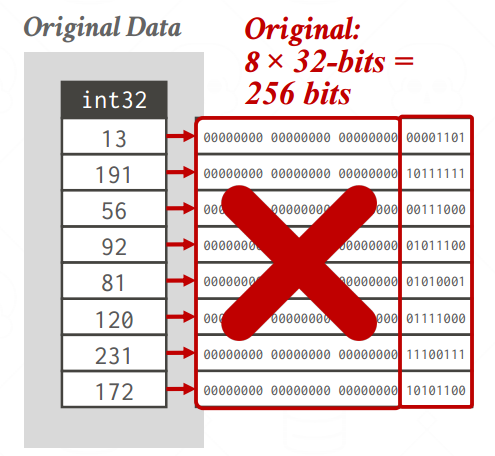
- PATCHING/MOSTLY ENCODING
- 当属性中的大多数值小于对应类型的最大值时,使用更小的数据类型来对其进行存储,对于少数数值很大的值仍然使用原来的数据类型来进行存储

-
Bit-map Encoding
-
对于一些属性,它的值就那些(比如枚举)
-
那直接用位运算存几个bit里面就完全够了
-
一共只有Y和N,那直接用两位bit就够了 -
但是从上面的图上面来看这个模式没有完全压榨二进制位运算的空间(比如只能用01和10,00和11都浪费了),所以在一些情况下压缩不如不压缩
-
-
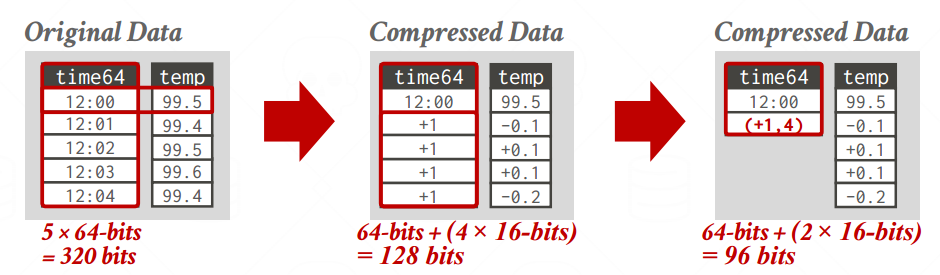
Delta Encoding
-
记录和上一列的差别,不记录实际数据
-
基础值内联到表里面或者单独查询,有这个基础值下面的值都能推断出来了
-
配合Run-Length-Encoding压缩效果会更好
-
先Delta Encoding再Run-Length-Encoding
-
-
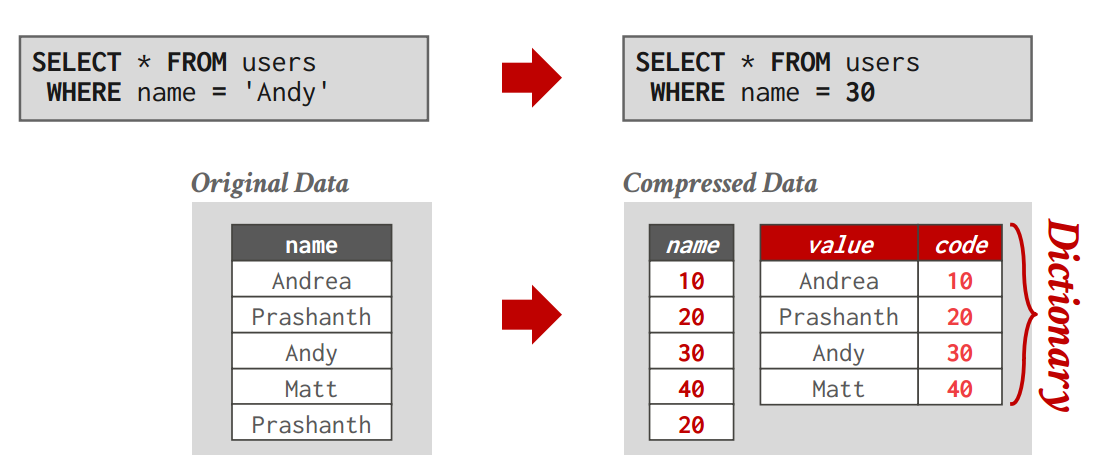
DICTIONARY COMPRESSION
-
Replace frequent values with smaller fixed-length codes and then maintain a mapping (dictionary) from the codes to the original values(搞一个K-V的映射,然后把原来数据的V换成长度更小的K)
-
Most widely used native compression scheme in DBMSs.
-
理想的字典查询是希望在单点查询和范围查询上面都有良好的性能
-
建一个Hash表,然后压缩原表 -
字典需要有两个功能
- Eecode/Locate:给了Key要能编码
- Decode/Extract:给了Value能解压成Key
- 所以即使上面会用Hash这个词,但是这个结构不能靠Hash函数来实现(Hash只能正着算,不能反向算)
-
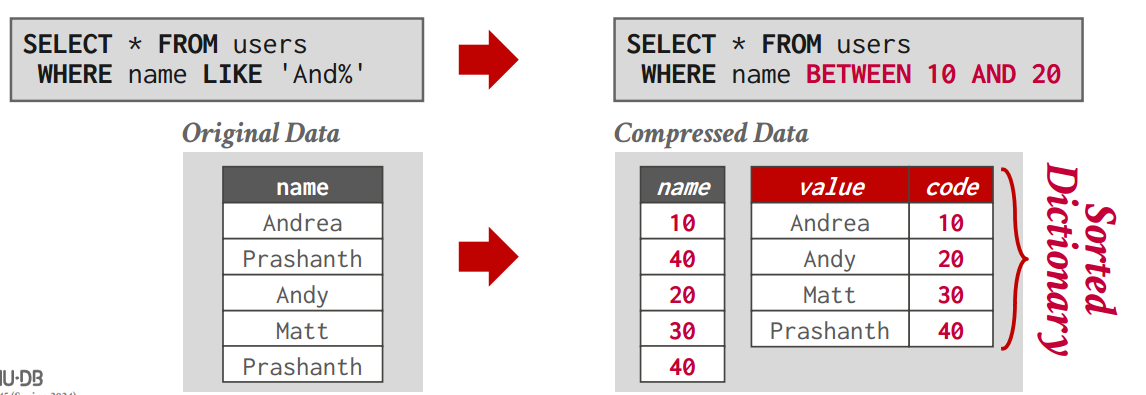
字典还要保序,不能说编完码之后你原表的数据顺序就变了,因为你要考虑范围查找这种东西
-
如果保序,范围查找对SQL里面的key做一次Hash就可以操作压缩后的数据了 -
字典压缩还有一个好处就是如果查询中有DISTINCT这种关键字,那么不需要进行全表扫描,直接去字典里面扫描一遍Value就够了
-
数据结构的选择
- Array
- 一个数组包含可变长度的字符串,一个数组包含指向映射到前面数组字符串的指针
- 更新成本很高,只能用在不可变文件中
- Hash Table
- 快速,紧凑
- 无法进行范围查询和前缀查询
- B+ Tree
- 比Hash Table要慢,而且占用更多的内存
- 支持范围查询和前缀查询
- Array
-