CMU 15-445 Lecture #07: Hash Tables
CMU 15-445 Database Systems
Lecture #07: Hash Tables
Data Structures
-
DBMS很多部分使用不同的数据结构
- Internal Meta-Data
- Core Data Storage
- Temporary Data Structures
- Table Indices
-
DBMS设计数据结构需要考虑两个方面
- Data organization:数据结构应该怎么设计,什么数据应该存到那,从而保证有效的访问
- Concurrency:老话题,只要是DBMS上面的东西基本都要考虑并发安全
Hash Table
-
哈希表实现了一个Key $\rightarrow$ Value的关联数组,它提供了平均$O(1)$的操作复杂度(当然最差会是$O(n)$)和$O(n)$的存储复杂度,这理要注意的是$O(1)$是理论上面的,在现实中实现这个数据结构的时候要考虑常数因子的优化
-
哈希表的实现由两部分组成
-
Hash Function:如何将较大的值映射到一个较小的空间内,这里要注意碰撞率和计算耗时的关系
- 计算越复杂,耗时越高,碰撞率越低
- 计算越简单,耗时越低,碰撞率越高
- Hash Function理想的情况就是在计算耗时和碰撞率之间取得平衡
-
Hashing Scheme:考虑哈希冲突的时候的处理办法,在扩大哈希表减少冲突和发生冲突时处理方案的复杂性中取得平衡
-
Hash Functions
-
Hash Function接收的参数应该可以是任意类型的,然后返回一个整数,该函数的输出要是确定性的(相同的参数输出的值要一样)
-
Hash Function一般不用网安那套加密安全哈希函数,因为不需要保护密钥的内容(这个东西只在DBMS内部使用,没有泄露的风险),我们只关心计算速度和碰撞率
The current state-of-the-art hash function is Facebook XXHash3.
Static Hashing Schemes
-
对于一个固定容量的Hash table来说,如果容量满了再次扩容代价很大
-
一般扩容都是给扩容成原来的2倍
-
避免hash冲突是很重要的,一般我们期望元素数=槽数$\times$2
-
Linear Probe Hashing
-
碰到Hash冲突就把K-V存到下一个槽里面
-
如果下一个槽还碰撞就下下个槽,直到找到空位置
-

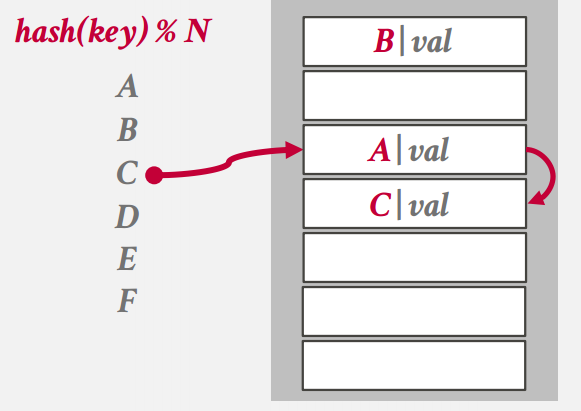
碰撞的处理方法 -
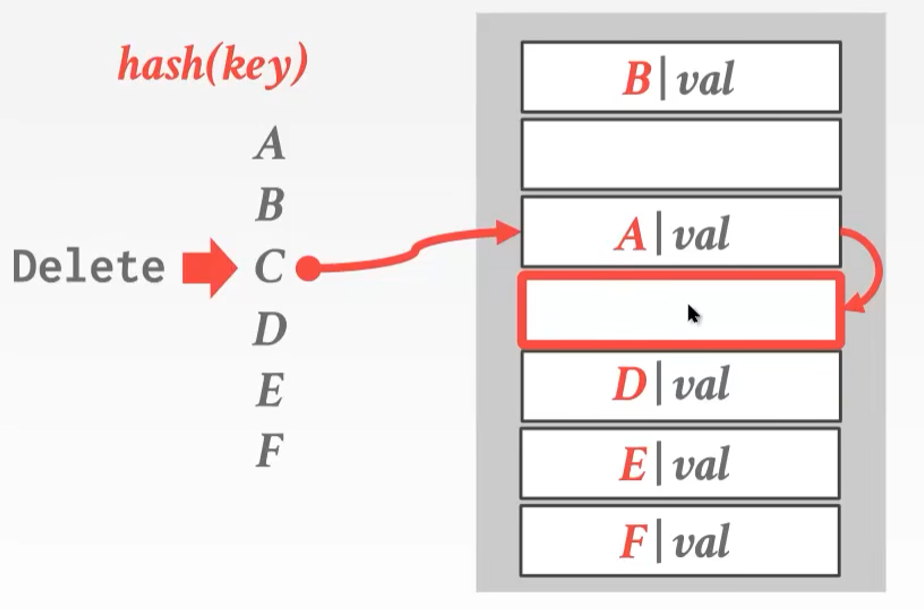
删除比较恶心
-
D因为和C碰撞往下走,现在C被删了,结果查D发现D没有了,出现了错误 -
解决方案
- 加上一个Tombstone标志,说明这个地方原来有数据,然后被删除了
- Movement:把下边的数据往上挪,但是不能傻瓜式的向上推,hash值是对的就不能动
-
- Non-unique Keys:同一个键可能与多个不同的值或元组关联的情况,两种解决方案
- Separate Linked List:存储Value的不再是一个值,而是List<V>,这样就可以存储多个值了
- Redundant Keys:将Key和Value结合起来再做hash
- Optimizations
- Specialized hash table implementations based on the data type or size of keys:根据数据结构不同/键大小采取不同的措施,比如字符串,小的字符串我拷贝存一份,大的字符串我存指针或者哈希
- Storing metadata in a separate array:将空槽/墓碑数据集中存在一个bitmap里面,作为哈希表的头文件或者作为一个单独的哈希表,这样避免查找已经删除的键
- Maintaining versions for the hash table and its slots:在哈希表上面删除/分配内存代价很高,所以给哈希表的Value添加一个version字段,只要version不匹配就认为没有这个Value,删数据就不用释放内存了
Google’s absl::flat hash map is a state-of-the-art implementation of Linear Probe Hashing.
- Cuckoo Hashing
- 使用多个哈希表,每个哈希表使用的哈希函数整体一样,但是参数不同(就是设定的种子)
- 一旦发生哈希碰撞,就把原有的值使用别的哈希函数驱赶到别的哈希表中,如果被驱逐的值也发生哈希碰撞就重复上面的过程,直到没有哈希碰撞
- 使用的很少,现实中这种实现问题很大
Dynamic Hashing Schemes
-
如果不知道需要存储数据的量,那么就需要一个能够动态扩容的哈希表
-
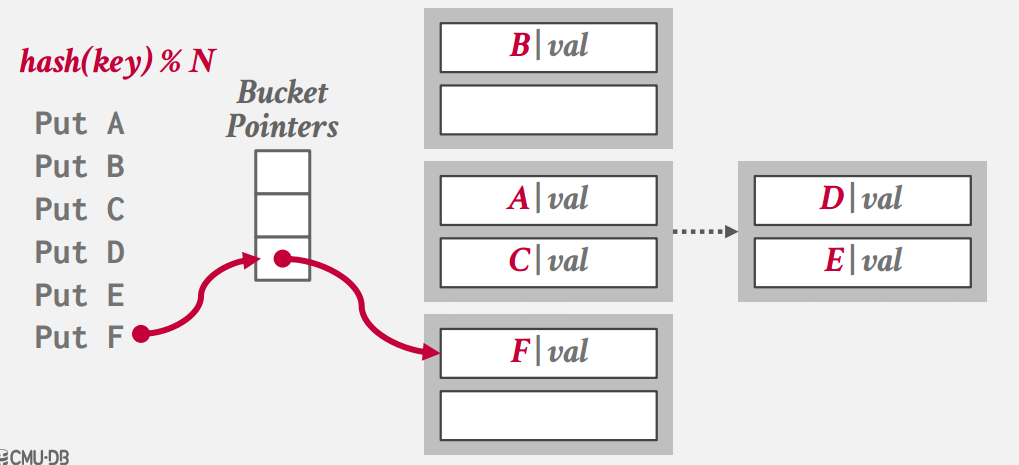
Chained Hashing
-
槽不再是单独的一个槽,而是变成了一个指针,指向一个“桶”,桶能存好多Value,一般也具备扩容的功能,有名的实现是Java的HashMap
-
Chained Hashing模型 -
Bloom Filters:布隆过滤器,Redis有讲,用来先过滤一遍不存在的数据
-
-
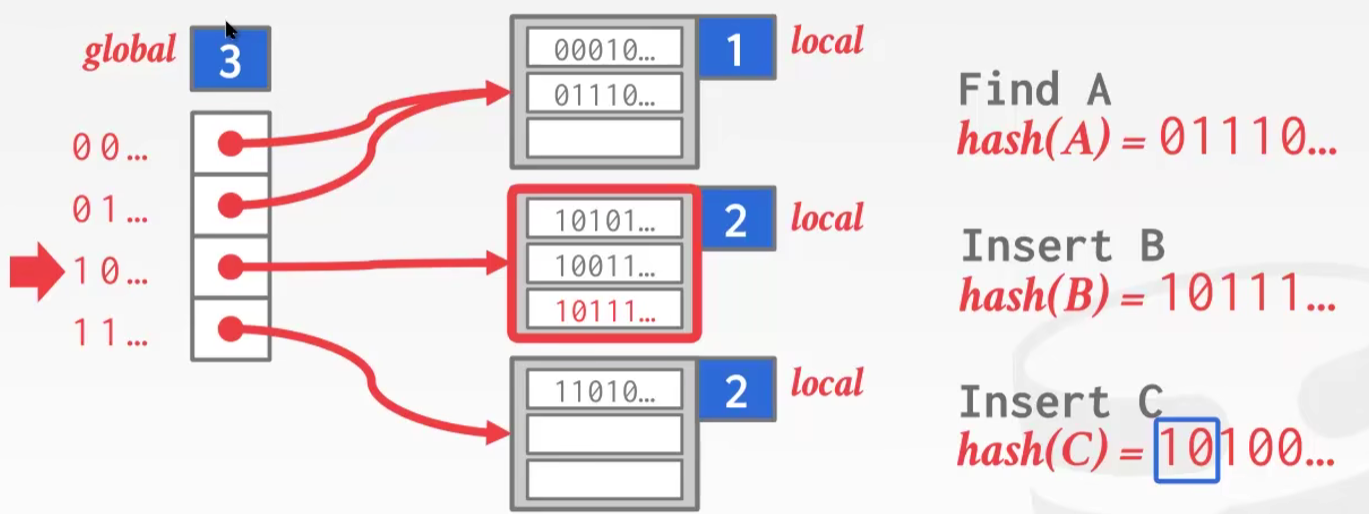
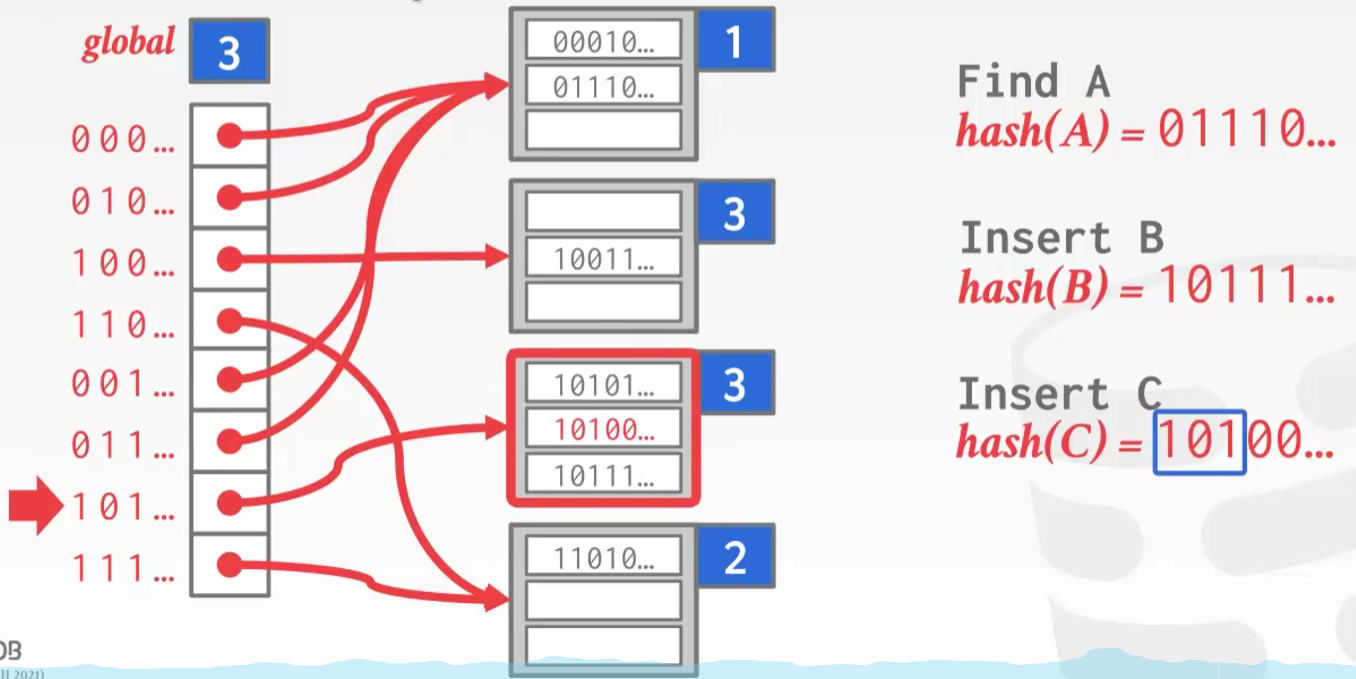
Extendible Hashing:这个也和Java的HashMap思想很像,2的幂次方扩容,每次扩容重排桶中的数据,计算hash的时候因为是2的幂次所以可以用位运算,每次扩容就是参与运算的二进制位变多了一位
扩容前
扩容后 -
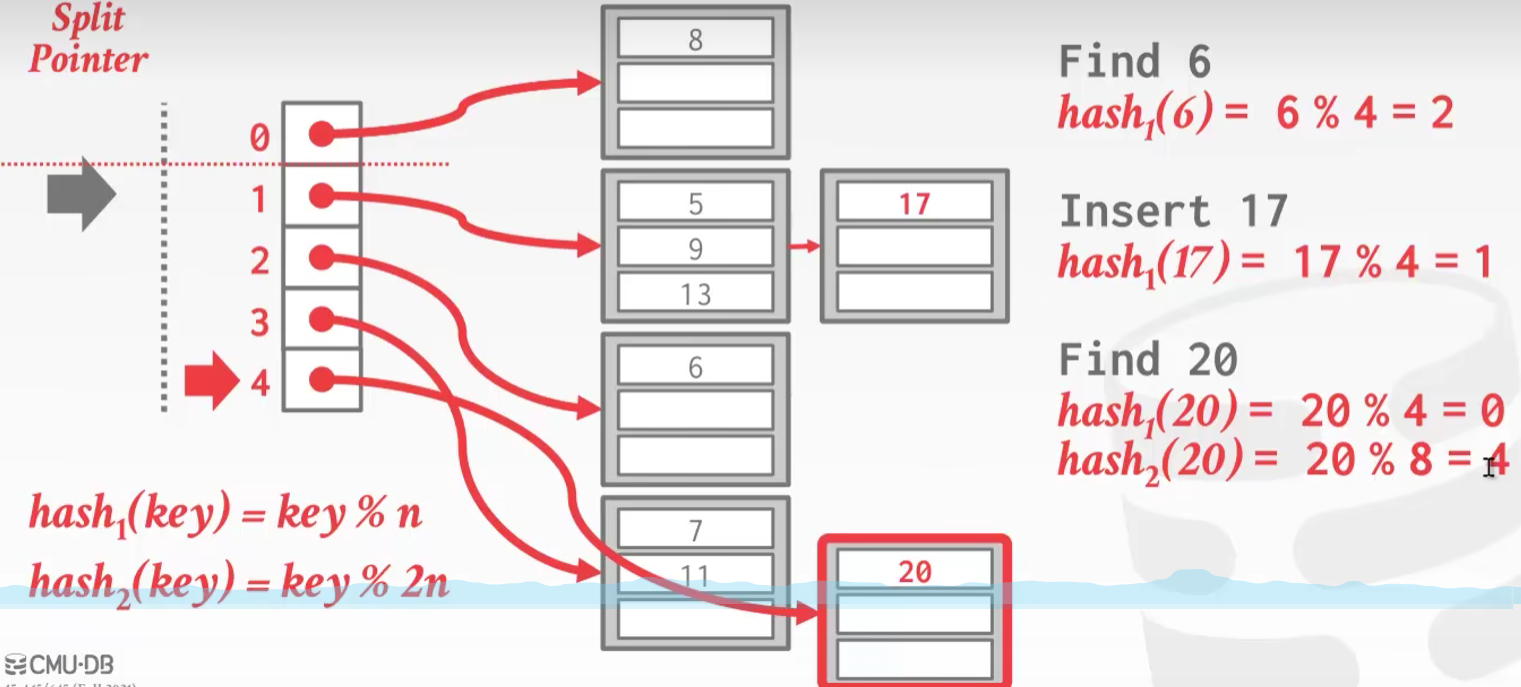
Linear Hashing
-
之前的扩容是按照2的幂次扩容,扩容一次需要的代价很大,需要用户等待很多时间
-
Linear Hashing希望扩容不要那么猛,一点一点慢慢扩容
-
由size = 4扩容到size = 5,分家指针向下移动一位,分家指针上面的槽用旧哈希函数x%n,分家指针下面的槽用新哈希函数x%2n -
分家指针指向原来的槽末尾再扩容就会回到0,此时一轮的扩容已经完成
-