CMU 15-445 Lecture #09: Index Concurrency Control
CMU 15-445 Database Systems
Lecture #09: Index Concurrency Control
Index Concurrency Control
-
前面讨论都默认是单线程条件下,但是对于DBMS这种主要问题在I/O上面的系统来说,肯定要上多线程,异步这些来提高效率,那么如何在这种条件下保证索引的线程安全很重要了
-
其他数据库的一些处理方法
- 内存型NoSQL:直接单线程模式运行,比如Redis
-
本节课主要研究Physical Correctness,关注底层设计
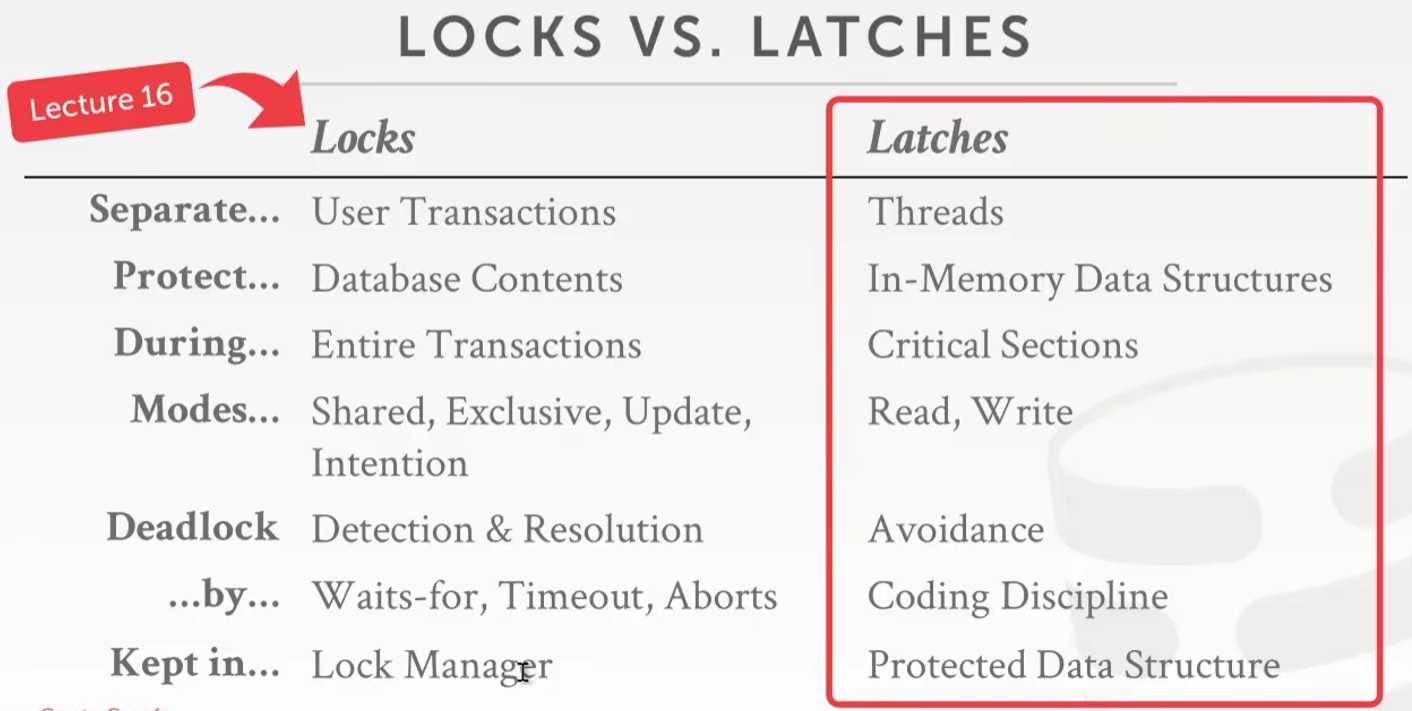
Locks vs. Latches
- 和前面的课讨论的一样,一个逻辑锁,一个底层锁
- 死锁和回滚都是建立在Locks上面的
- Latches这个锁要划分为读锁和写锁
- 多个线程可以同时去读一个变量,相应的读锁可以重入其他线程的读锁,但是其他线程不能写(也叫共享锁)
- 一个线程写数据的时候,其他线程不能读和写这个数据,所以写锁一般不可重入其他线程的锁(也叫独占锁)
Latch Implementations
- Blocking OS Mutex
- simple to use(操作系统自己支持)
- Non-scalable (about 25ns per lock/unlock invocation),大规模使用不行,这东西效率太低
- Example: std::mutex$\rightarrow$pthread_mutex$\rightarrow$futex
|
|
- 底层实现:内存中分配出来一个变量来获取锁,要锁的程序就把这个变量设置值,如果发现锁被夺取,这个线程就直接进入内核态自己sleep,如果锁被释放操作系统会试着唤醒sleep的线程
- 好处:竞争的线程拿不到锁直接sleep,不会额外消耗系统的资源
- 坏处:sleep和notify在操作系统层面上面很浪费资源(线程链表的调整)
- Test-and-Set Spin Latch (TAS)
- 也叫自旋锁
- Very efficient (single instruction to latch/unlatch)
- Non-scalable, not cache friendly, not OS friendly.大规模用效率上也不行,自旋也很笨
- Example: std::atomic<T>
|
|
-
检测和设置这一组操作必须要是原子的
-
自旋锁对于CPU的开销很大(一直空转)
-
很多语言会把TAS和Blocking结合,自旋一阵子不行就去睡一会
- Atomic Instruction Example: compare-and-swap (CAS)
-
Atomic instruction that compares contents of a memory location M to a given value V
- If values are equal, installs new given value V’ in M
- Otherwise, operation fails
-
这个东西是CPU的一条指令,由CPU来保证原子性
-
经常作为自旋锁或者JUC的包里面的一些锁底层的实现
-
- Reader-Writer Latches
- Allows for concurrent readers. Must manage read/write queues to avoid starvation.
- Can be implemented on top of spinlocks
- Example: std::shared_mutex $\rightarrow$ pthread_rwlock
Hash Table Latching
-
好加锁,无论是桶还是开放地址哈希,大家查找的方向是一致的,并且一次只能访问一个页/槽,这点上出不了死锁(当然HashMap的头插法可能会出,不过这个和链表的结构有关),向其他搜索方向不一致的B+ Tree可能就会出死锁
-
如果要调整容量,一般把整个哈希表都给加上全局的写锁
-
其他情况下一般锁部分就可以了
-
Page/Block-level Latches
- Each page/block has its own reader-writer latch that protects its entire contents.
- Threads acquire either a read or write latch before they access a page/block
- 按块划分,加锁
- Java的ConcurrentHashMap是这种处理方案,几个槽一个锁
- 好处:不用维护太多锁,还保证了并发性
-
Slot Latches
- 一个槽加一个锁
- 锁更细了,更能避免死锁和提高并发
- 但是维护这么多锁开销太高了
-
还有其他方法,比如读写分离(比如go的sync.Map)
-
B+Tree Latching
- 两方面的并发问题
- 节点内部的数据要做并发保护
- 节点的分裂/合并过程中要做并发保护
-
Latch Crabbing/Coupling
-
Get latch for parent,给根节点上锁
-
Get latch for child,给子节点上锁
-
Release latch for parent if “safe”,判断子节点是否“安全”,安全的话放根节点的锁
-
“safe”:A safe node is one that will not split or merge when updated.
-
-
Find: Start at root and traverse down the tree
- Acquire R latch on child
- Then unlatch parent
- Repeat until we reach the leaf node
-
Insert/Delete: Start at root and go down, obtaining W latches as needed. Once child is latched, check if it is safe:
- If child is safe, release all latches on ancestors
-
问题:所有的操作都要先锁根节点,这是一个性能上面的瓶颈
- 原因:上面的想法是悲观的,认为每次写操作都有可能会造成根节点的分裂/合并,但是实际上来说根节点变动的次数很少
- 使用乐观的想法:我认为大部分操作不会改变根节点的结构,所以我给根节点加读锁,如果说发现根节点要变动结构,这个时候从根节点重新给加写锁
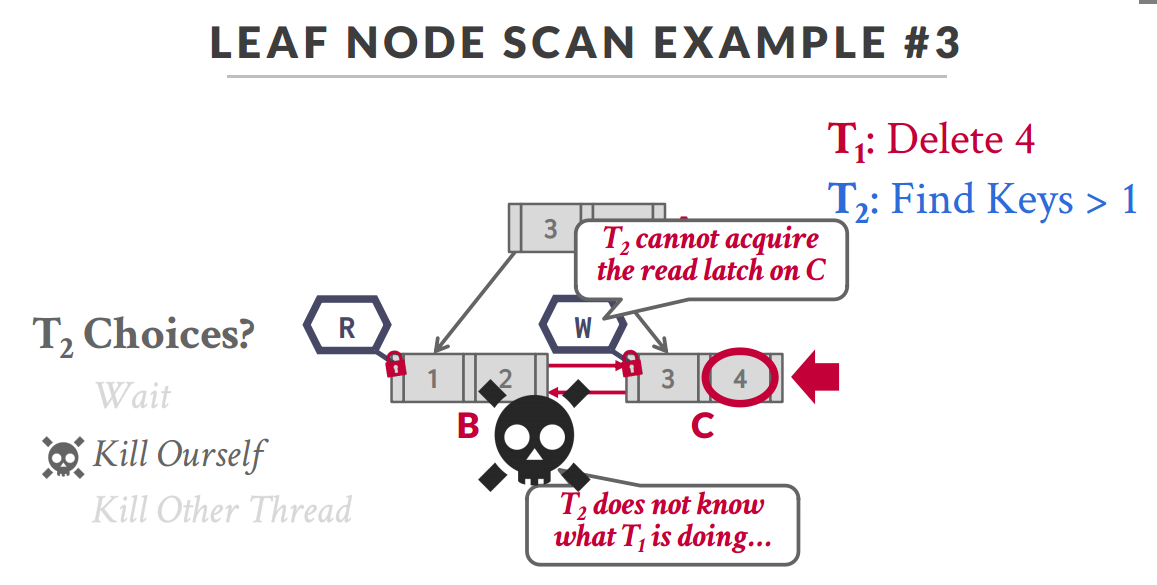
- Leaf Node Scans
- 一般来说是顺序扫描
- 但是这样会带来一个风险:Find key > 4和Find key < 1扫描叶子节点的时候方向是相反的,会有死锁的风险

方向相反造成死锁 - 解决方法:制定规则,比如数据只能从大往小走,比如MySQL,之前不支持倒序遍历就和这个有关,后面又加上了倒叙索引才解决了这个问题